- Table of contents
- QE tools - Team description
- Team responsibilities
- Out of scope
- Our common userbase
- How we work
- What we expect from team members
- Common tasks for team members
- Best practices for major changes
- Guideline for communication in tickets
- How we work on our backlog
- Team meetings
- Team
- Onboarding for new joiners
- Offboarding
- Alert handling
- Collaboration best practices
- openQA short video creation
- Things to try
- Literature references
- Historical
- Team-internal Hack Week (or Hackweek)
- Change announcements
QE tools - Team description¶
"The easiest way to provide complete quality for your software"
We provide the most complete free-software system-level testing solution to ensure high quality of operating systems, complete software stacks and multi-machine services for software distribution builders, system integration engineers and release teams. We continuously develop, maintain and release our software to be readily used by anyone while we offer a friendly community to support you in your needs. We maintain the main public and SUSE internal openQA server as well as supporting tools in the surrounding ecosystem.
Team responsibilities¶
- Develop and maintain upstream openQA including the backend os-autoinst
- Administration of SUSE internal openqa.suse.de (osd) and workers
- Helps administrating and maintaining openqa.opensuse.org (o3), including coordination of efforts aiming at solving problems affecting o3
- Develop and maintain SUSE maintenance QA tools, e.g. qem-bot, osc-plugin-qam, MTUI
- Help with the investigation of specific issues, especially when they are likely related to generic, hardware or backend problems
- Support colleagues, team members and open source community
Out of scope¶
- Maintenance and recurring review of individual tests (besides openQA-in-openQA tests)
- Maintenance of special worker addendums needed for tests, e.g. external hypervisor hosts for s390x, powerVM, xen, hyperv, IPMI, VMWare (Clarification: We maintain the code for all backends but we are no experts in specific domains. So we always try to help but it's a case by case decision based on what we realistically can provide based on our competence. We can't be expected to be experts in everything and also we are limited in what we can actually test.)
- Maintenance of most openSUSE related triggering solutions, e.g. for Tumbleweed or Leap maintenance that use https://github.com/openSUSE/opensuse-release-tools on https://botmaster.suse.de. Contact "SUSE Security Solutions", e.g. Marcus Meissner, for this.
- Ticket triaging of http://progress.opensuse.org/projects/openqatests/
- Setup of configuration for individual products to test, e.g. new job groups in openQA
- Feature development within the backend for single teams (commonly provided by teams themselves)
Our common userbase¶
Known users of our products: Most SUSE QA engineers, SUSE SLE release managers and release engineers, every SLE developer submitting "submit requests" in OBS/IBS where product changes are tested as part of the "staging" process before changes are accepted in either SLE or openSUSE (staging tests must be green before packages are accepted), same for all openSUSE contributors submitting to either openSUSE:Factory (for Tumbleweed, SLE, future Leap versions) or Leap, other GNU/Linux distributions like Fedora https://openqa.fedoraproject.org/ , AlmaLinux http://openqa.almalinux.org/, Debian https://openqa.debian.net/ , https://openqa.qubes-os.org/ , https://openqa.endlessm.com/ , the GNOME project https://openqa.gnome.org, https://www.codethink.co.uk/articles/2021/automated-linux-kernel-testing/, https://en.euro-linux.com/blog/openqa-or-how-we-test-eurolinux/, openSUSE KDE contributors (with their own workflows, https://openqa.opensuse.org/group_overview/23 ), openSUSE GNOME contributors (https://openqa.opensuse.org/group_overview/35 ), OBS developers (https://openqa.opensuse.org/parent_group_overview/7#grouped_by_build) , wicked developers (https://gitlab.suse.de/wicked-maintainers/wicked-ci#openqa), and of course our team itself for "openQA-in-openQA Tests" :) https://openqa.opensuse.org/group_overview/24 . Also see https://en.opensuse.org/openSUSE:OpenQA/Partners .
Keep in mind: "Users of openQA" and talking about "openSUSE release managers and engineers" means SUSE employees but also employees of other companies, also development partners of SUSE.
In summary our products, for example openQA, are a critical part of many development processes hence outages and regressions are disruptive and costly. Hence we need to ensure a high quality in production hence we practice DevOps with a slight tendency to a conservative approach for introducing changes while still ensuring a high development velocity.
This might be reworked via: https://github.com/os-autoinst/linux-qa/issues/1 to make it more discoverable
How we work¶
The joint QE Tools team is following the DevOps approach working using a lightweight Agile approach also inspired by Extreme Programming and Kanban and of course the original http://agilemanifesto.org/. We structure our team and roles following Agile Product Ownership in a Nutshell. We plan and track our works using tickets on https://progress.opensuse.org . We pick tickets based on priority and planning decisions. We use weekly meetings as checkpoints for progress and also track cycle and lead times to crosscheck progress against expectations. The joint QE Tools team is composed of two closely collaborating teams with individual scope:
- dev: openQA - upstream os-autoinst+openQA and operating openQA on o3
- infra: QE infrastructure - OSD, o3 OS and base, qem-dashboard, hardware, compliance, etc. - SUSE specific solutions
Relevant ticket queries:
- tools team - joint team backlog: The complete backlog of the joint team
- tools team - backlog, high-level view: A high-level view of the backlog, all epics and higher (an "epic" includes multiple stories)
- tools team - backlog, top-level view: A top-level view of the backlog, only sagas and higher (a "saga" is bigger than an epic and can include multiple epics, i.e. "epic of epics")
- dev team - backlog: The backlog of the dev team
- infra team - backlog: The backlog of the infra team
- tools team - what members of the team are working on: To check progress and know what the team is currently occupied with
- tools team - closed within last 60 days: What was recently resolved
- tools team - next: The staging ground for next tasks considered to be picked into the backlog
Be aware: Custom queries in the right-hand sidebar of individual projects, e.g. https://progress.opensuse.org/projects/openqav3/issues , show queries with the same name but are limited to the scope of the specific projects so can show only a subset of all relevant tickets.
What we expect from team members¶
- Actively show visible contributions to our products every workday (pull requests, code review, ticket updates in descending priority, i.e. if you are very active in pull requests + code review ticket updates are much less important)
- Be responsive over usual communication platforms and channels (user questions, team discussions)
- Stick to our rules (this wiki, SLOs, alert handling)
Common tasks for team members¶
This is a list of common tasks that we follow, e.g. reviewing daily based on individual steps in the DevOps Process 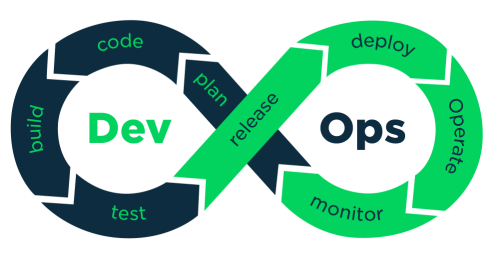
- Plan:
- State daily learning and planned tasks in internal chat room
- Review backlog for time-critical, triage new tickets, pick tickets from backlog; see https://progress.opensuse.org/projects/qa/wiki#How-we-work-on-our-backlog
- Coordinate on the agile board https://progress.opensuse.org/agile/board?query_id=711
- Code:
- See project specific contribution instructions
- Provide peer-review and development support of projects about and around openQA, in particular:
- https://github.com/os-autoinst/openQA
- https://github.com/os-autoinst/os-autoinst
- https://github.com/os-autoinst/scripts
- https://github.com/os-autoinst/os-autoinst-distri-openQA
- https://github.com/os-autoinst/openqa-trigger-from-obs
- https://github.com/os-autoinst/openqa_review
- https://github.com/os-autoinst/openqa_bugfetcher
- https://github.com/openSUSE/Mojo-IOLoop-ReadWriteProcess
- https://github.com/openSUSE/mtui
- https://github.com/openSUSE/qem-bot
- https://github.com/openSUSE/backlogger
- https://github.com/openSUSE/qem-dashboard
- https://github.com/openSUSE/openSUSE-release-tools/tree/master/factory-package-news
- Offer development help for people contributing to those projects when it's not their main job anyway, e.g. review in pull requests, offer to continue developing, help to fix CI tests, dependabot updates, etc.
- Build:
- See project specific contribution instructions
- Test:
- Monitor failures on https://app.circleci.com/pipelines/github/os-autoinst/openQA?branch=master relying on https://build.opensuse.org/project/show/devel:openQA:ci for openQA (email notifications)
- Release:
- By default we use the rolling-release model for all projects unless specified otherwise
- Monitor devel:openQA on OBS (all packages and all subprojects) for failures, ensure packages are published on http://download.opensuse.org/repositories/devel:/openQA/, ensure to be added as a Maintainer for that project (members need to be added individually, you can ask existing team members, e.g. the SM). To be notified of build errors via email:
- Add it to your watchlist:
- Go to devel:openQA, click on "Watchlist" in the top navi and click on "Watch this project"
- Go to subscriptions, to the section "Package failed to build" and enable notifications for "Watching the project"
- Alternatively get notifications for all projects that you maintain:
- Just enable "Package failed to build" - "Maintainer" notifications in subscriptions
- Add it to your watchlist:
- Monitor http://jenkins.qe.nue2.suse.org for the openQA-in-openQA Tests and automatic submissions of os-autoinst and openQA to openSUSE:Factory through https://build.opensuse.org/project/show/devel:openQA:tested
- Deploy:
- o3 is automatically deployed (daily), see https://progress.opensuse.org/projects/openqav3/wiki/Wiki#Automatic-update-of-o3
- Operate:
- Apply infrastructure changes to o3 (manually over ssh)
- Ensure old unused/non-matching needles are cleaned up (osd+o3), see #73387
- Monitor:
- For openqa.opensuse.org react on alerts from zabbix.suse.de (emails on o3-admins@suse.de
- Look for incomplete jobs or scheduled not being worked on o3 and osd (API or webUI) - see also #81058 for power
- React on alerts from https://gitlab.suse.de/openqa/auto-review/, https://gitlab.suse.de/openqa/openqa-review/, https://gitlab.suse.de/openqa/monitor-o3 (subscribe to projects for notifications)
- Be responsive on #opensuse-factory (irc://irc.libera.chat/opensuse-factory, formerly irc://chat.freenode.net/opensuse-factory) for help, support and collaboration (Unless you have a better solution it is suggested to use Element.io for a sustainable presence; you also need a registered IRC account, formerly freenode) note don't use matrix features on irc!
- Be responsive on #team-qa-tools in chat for internal coordination and alarm handling, fallback to #suse-qe-tools:opensuse.org (matrix) as backup if other channels are temporarily down, alternatively public channels on matrix/ IRC if the topics are not confidential
- for incidents walk through the checklist in the #team-qa-tools. When it is needed, reply to the incident/comment on the Slack with a :rotating_light:

- for incidents walk through the checklist in the #team-qa-tools. When it is needed, reply to the incident/comment on the Slack with a :rotating_light:
- Also join #team-qa-tools-notifications
- Be responsive on #eng-testing for help, support and collaboration
- Be responsive on mailing lists opensuse-factory@opensuse.org and openqa@suse.de (see https://en.opensuse.org/openSUSE:Mailing_lists_subscription)
- Be responsive in https://matrix.to/#/#openqa:opensuse.org or the bridged room #openqa on https://discord.gg/opensuse if you have a discord account
For SUSE internal information see https://gitlab.suse.de/suse/wiki/
Best practices for major changes¶
When proposing non-trivial changes with the potential of breaking existing tests consider the follow best practice patterns:
- Make the problematic change opt-in via a test variable like MY_NEW_FEATURE_ENABLED to enable the new behavior, and otherwise log a warning only
- Include a reference to a relevant GitHub PR and progress ticket
- If a BARK test is to be conducted to assess the full impact of the change an autoreview regex matching the most relevant error message should be prepared so that affected jobs can be restarted trivially without disrupting daily operation too much - it's called a BARK test from how the bark of a tree is scratched to confirm if it's green and alive or brown and not healthy anymore.
- Inform all stakeholders in relevant Slack channels, Matrix and mailing lists
- Include an explicit mention in the release notes
Guideline for communication in tickets¶
-
Clarify action items and steps (to be) taken, for example
- I will implement ... from the suggestions
- I will monitor ... and evaluate results
- Confirm if other experts will provide reproducers
- Document mitigations with references to MRs, PRs or manual file changes and keep the description updated
- Confirm if adjustments made by others are still in place
-
Explicitly include examples of what won't be done
- I won't look into the test code itself here
-
Make use of the scientific method template with hypotheses, experiments and observations
How we work on our backlog¶
- "due dates" are only used as exception or reminders. Commonly the due-date is set automatically to 14 days in the future as soon as a non-low ticket is picked up. That period is roughly the median cycle time which we want to stay well below. And on top, to prevent redmine sending a reminder and the backlog status to flag issues the ticket should be resolved before the due-date, at least a day but possibly a reminder is sent out even on the last day before so better resolve on the second to last day. Of course, even better to always try to finish as soon as possible, well before the due date.
- every team member can pick up tickets themselves
- everybody can set priority, PO can help to resolve conflicts
- consider the ready, not assigned/blocked/low query as preferred. It is suggested to pick up tickets based on priority. "Workable" tickets are often convenient and hence preferred.
- ask questions in tickets, even potentially "stupid" questions, oftentimes descriptions are unclear and should be improved
- Ask assignees and domain experts explicitly for agreement or disagreement, especially for expert tickets
- There are "low-level infrastructure tasks" only conducted by some team members, the "DevOps" aspect does not include that but focusses on the joint development and operation of our main products
- Consider tickets with the subject keyword or tag beginner as good learning opportunities for people new to a certain area. Experts in the specific area should prefer helping others but not work on the ticket
- For tickets which are out of the scope of the team remove from backlog, delegate to corresponding teams or persons but be nice and supportive, e.g. see our IT ticket handling process and SLA, test maintainer, QE-LSG PrjMgr/mgmt
- Whenever we apply changes to the infrastructure we should have a ticket
- Refactoring and general improvements are conducted while we work on features or regression fixes
- For every regression or bigger issue that we encounter try to come up with at least two improvements, e.g. the actual issue is fixed and similar cases are prevented in the future with better tests and optionally also monitoring is improved
- For critical issues and very big problems especially when we were informed by users about outages collect "lessons learned", e.g. in notes in the ticket or a meeting with minutes in the ticket, consider Five whys and answer at least the following questions: "User impact, outwards-facing communication and mitigation, upstream improvement ideas, Why did the issue appear, can we reduce our detection time, can we prevent similar issues in the future, what can we improve technically, what can we improve in our processes". See previous 5 whys. Also see https://youtu.be/_Dv4M39Arec
- okurz proposes to use "#NoEstimates". Though that topic is controversial and often misunderstood. https://ronjeffries.com/xprog/articles/the-noestimates-movement/ describes it nicely :) Hence tickets should be evenly sized and no estimation numbers should be provided on tickets
- If you really want you can look at the burndown chart (some people wish to have this) but we consider it unnecessary due to the continuous development, not a project with defined end. Also an agile board is available but likely due to problems within the redmine installation ordering cards is not reliable.
- Write to qa-team@suse.de as well for critical changes as well as chat channels
- Everyone should propose reverts of features if we find problems that can not be immediately fixed or worked around in production
Definition of DONE¶
Also see https://web.archive.org/web/20110308065330/ http://www.allaboutagile.com/definition-of-done-10-point-checklist/ and https://web.archive.org/web/20170214020537/ https://www.scrumalliance.org/community/articles/2008/september/what-is-definition-of-done-(dod)
- Code changes are made available via a pull request on a version control repository, e.g. github for openQA
- Guidelines for git commits have been followed
- Code has been reviewed (e.g. in the github PR)
- Depending on criticality/complexity/size/feature: A local verification test has been run, e.g. post link to a local openQA machine or screenshot or logfile (especially also for hardware-related changes, e.g. in os-autoinst backend)
- For regressions: A regression fix is provided, flaws in the design, monitoring, process have been considered
- Potentially impacted package builds have been considered, e.g. openSUSE Tumbleweed and Leap, Fedora, etc.
- Code has been merged (either by reviewer or "mergify" bot or reviewee after 'LGTM' from others)
- Code has been deployed to osd and o3 (monitor automatic deployment, apply necessary config or infrastructure changes)
Definition of READY for new features¶
The following points should be considered before a new feature ticket is READY to be implemented:
- Follow the ticket template from https://progress.opensuse.org/projects/openqav3/wiki/#Feature-requests
- A clear motivation or user expressing a wish is available
- Acceptance criteria are stated (see ticket template) or use
[timeboxed:<nr>h]with<nr>hours for tasks that should be limited in time, e.g. a research task with[timeboxed:20h] research … - add tasks as a hint where to start
WIP-limits (reference "Kanban development")¶
- global limit of 10 tickets, and 3 tickets per person respectively In Progress
- global limit of 10 tickets in Feedback, not-low
Target numbers or "guideline", "should be", in priorities¶
- New, untriaged QA (openQA, etc.): 0 (daily) . Every ticket should have a target version, e.g. "Ready" for QE tools team, "future" if unplanned, others for other teams
- Untriaged "tools" tagged: 0 (daily) . Every ticket should have a target version, e.g. "Ready" for QE tools team, "future" if unplanned, others for other teams
- Workable (properly defined): 10-40 . Enough tickets to reflect a proper plan but not too many to limit unfinished data (see "waste")
- Overall backlog length: ideally less than 100 . Similar as for "Workable". Enough tickets to reflect a proper roadmap as well as give enough flexibility for all unfinished work but limited to a feasible number that can still be overlooked by the team without loosing overview. One more reason for a maximum of 100 are that pagination in redmine UI allows to show only up to 100 issues on one page at a time, same for redmine API access.
- Within due-date: 0 (daily/weekly) . We should take due-dates serious, finish tickets fast and at the very least update tickets with an explanation why the due-date could not be hold and update to a reasonable time in the future based on usual cycle time expectations
SLAs (service level agreements)¶
-
for at least picking up tickets, better providing reasonable updates based on priority, first goal is "urgency removal":
-
immediate: <1 day
-
urgent: <1 week / 6 days
-
high: <1 month / 29 days
-
normal: <1 year / 364 days
-
low: undefined
-
"reasonable updates": Provide fixes, workarounds or at least state of progress or when the task is blocked
-
to ensure timely updates immediate/urgent tickets must never be in status "Blocked" or "Feedback"
-
aim for cycle time of individual tickets (not epics or sagas): 1h-2w
SLOs (service level objectives, internal)¶
-
For providing reasonable updates on tickets in our backlog based on priority, first goal is "urgency removal":
-
immediate: multiple times within the day
-
urgent: <1 day
-
high: <1 week / 6 days
-
normal: <1 month / 29 days
-
low: <1 year / 364 days
-
Frequent updates do not necessarily need to happen in tickets but visible in written form, e.g. just internal chat. Especially in ticket updates every comment should give a clear answer: Who plans to do what until when, in particular the ticket assignee.
-
Reference for SLOs and related topics: https://sre.google/sre-book/table-of-contents/
Status overview¶
Dynamic dashboard showing target numbers and SLOs: https://os-autoinst.github.io/qa-tools-backlog-assistant/
Backlog prioritization¶
When we prioritize tickets we assess:
- What the main use cases of openQA are among all users, be it SUSE QA engineers, other SUSE employees, openSUSE contributors as well as any other outside user of openQA
- We try to understand how many persons and products are affected by feature requests as well as regressions and prioritize issues affecting more persons and products and use cases over limited issues. See #120540 for details in particular about the various os-autoinst backends
- We prioritize regressions higher than work on (new) feature requests
- If a workaround or alternative exists then this lowers priority. We prioritize tasks that need deep understanding of the architecture and an efficient low-level implementation over convenience additions that other contributors are more likely to be able to implement themselves.
Periodic backlog refinement¶
These queries can be used to help organize our work efficiently
- QE tools team - backlog - sorted by update time ensure all tickets are reasonably up-to-date and don't keep hanging around
- QE tools team - due date forecast prevent running into due-dates proactively
- QE tools team - next - sorted by update time ensure all next tickets are reasonably up-to-date and considered for the backlog
- QE tools team - backlog, non-reactive, needs parent ensure all our (non-reactive) work is linked to higher-level planning as motivation
It's good practice to keep an eye on the queries to anticipate blockers. All team members are encouraged to utilize them.
Note that due dates should provide a hint as to when a ticket will be resolved but they need to be realistic. Availability, reviews and deployment need to be factored in as well since typically a ticket will be in Feedback before it can be resolved. If in doubt the Due date should be extended with an accompanying message like "Outstanding branches still need to be reviewed" or simply "Bumping the due date because of availability".
Team meetings¶
Note: We're are using the virtual office on workadventu.re for regular meetings unless otherwise mentioned. We meet at the glass table in the north-east (walk towards the right) linked to https://meet.opensuse.org/6blugd-meetopensuseorg .
There's other tables for ad-hoc conversations such as the white sofa space where it says senf call linked to https://lecture.senfcall.de/liv-inx-vgs-jf0 . You just need to be next to each other to chat.
Regular calls:
-
Dailies: Infra Every weekday 1020-1035 CET/CEST, Dev Every weekday 1040-1055 CET/CEST. Use (internal) chat actively, e.g. formulate your findings or achievements and plans for the day, "think out loud" while working on individual problems. Join our regular meeting location . At the latest at 1100 CET/CEST everyone working on that day must have checked in, at least with a text message in chat.
- Goal: Emergency responses, clarify next steps or blockers on current work items, asking and answering questions on tickets that would be ignored otherwise, ticket estimations (after the regular daily) (compare to Daily Scrum)
-
Conduction: Answer the following questions concerning dev tickets and infra tickets respectively:
- Is the backlog status green?
- Are there any time-critical issues to be handled?
- What was achieved since the last time?
- Who needs help?
- Plans until next time?
- Are the ACs still feasible given the due date on the ticket?
-
Ticket Estimations: Infra Every Tuesday 1400 CET/CEST, Dev Every Thursday 1100-1150 CET/CEST including a 5 minute break
- Goal: Estimate t-shirt sizes for non-estimated tickets i.e. non-estimated infra tickets and non-estimated dev tickets.
- Goal: Ensure tickets are workable. Refine and split tickets for larger estimates.
-
Conduction:
- Consider using SCRUM Poker or Jitsi surveys to make explicit decision points for ticket estimation calls to prevent awkward silences
- Check who reads out tickets, prepares the etherpad and updates the ticket respectively at the start of the call
- Try and aim for S size tickets (e.g. <20h of effort), and split up the ticket if needed. An M size ticket is more complex, e.g. when multiple code repositories need to be touched.
- If a ticket can't be estimated in 10 minutes, schedule a follow-up conversation or skip the ticket e.g. with a short comment on open questions
- Consider adding a tag for beginner and expert tickets.
- Explicitly consider a good subject for each ticket
- Consider going by priority and status i.e. start with immediate/urgent/high and otherwise feedback/progress
- If a ticket is in feedback, check if it needs more discussion or can be resolved
-
Midweekly Unblock: Every Wednesday 1100-1150 CET/CEST including a 5 minute break
- Goal: Discuss tasks in progress in more detail, unblock currently assigned tasks and tasks avoided for longer (see Periodic backlog refinement), apply the pull principle based on tickets in progress firstly and tickets updated by priority secondarily, confirm if a ticket should be split up or re-estimated, and whether the difficulty level was considered before - the collaborative session can be used to dedicate more time to tickets in need of attention.
-
Collaborative Session: Thursdays between 1330-1630 CET/CEST in our regular meeting location if a topic was picked at the latest in the Estimations and announced accordingly. Pick from previous suggestions or bring up your own topic
- Goal: Follow-up on tasks too difficult to solve alone, or where someone looks to be stuck using pair programming and other means
-
Fortnightly Coordination: Friday 1100-1150 CET/CEST every even week including a 5 minute break. Community members and guests are particularly welcome to join this meeting.
- Goal: Reflect on how well the team worked in the past two weeks, Team backlog coordination and design decisions of bigger topics (compare to Sprint Planning).
- Conduction: Evaluate metrics(#152957), Demo recently finished feature work depending on last closed, crosscheck status of team, discuss blocked tasks and upcoming work
- Metrics: an Average can be defined as the sum of all numbers divided by the total number of values / a mean can be defined as an average of the set of values in a sample of data / the
-
Fortnightly Retrospective: Friday 1100-1150 CET/CEST every odd week including a 5 minute break - a link to our retro board can be found in the Slack bookmarks, or the reminder to join the call.
- Goal: Inspect and adapt, learn and improve (compare to Sprint Retrospective)
- Conduction: The board is made available via Slack. Topics can also be brought up in conversation. Follow-up actions will be recorded as tickets with the "retro" tag.
-
Virtual coffee: Weekly every Monday 1330-1345 CET/CEST in our regular meeting location.
- Goal: Connect and bond as a team, understand each other (compare to Informal Communication in an all-remote environment)
Weekly moderation duty¶
- By default calls are moderated by the SM of the respective team (Liv/Tina) or Oliver. Otherwise a fallback moderator can take over, see Team for people with a mod indicator. See also #177895#note-12
- The moderator should make an effort to give everyone a chance to participate, or if nothing else ask if anyone had no chance to speak up
- For the conduction of calls see Team meetings and Best practices for meetings
- Hand over to the next person after the weekly, going by the order of team members in the wiki
- Asks for standin on unavailabilities
Best practices for meetings¶
- It is recommended to use the Jitsi Audio-feedback feature, blue/green circles depending on microphone volume. Everybody should ensure that at least "two green bubbles" show up. Consider audio trouble shooting hints from the openSUSE Support DataBase
- Ask and give feedback regarding the audio quality. Use plain-language radio checks such as "Loud and clear" if everything is good or "weak but readable" if of low volume but one can understand what the person is saying if there is no one else overlaying with higher volume. Or "loud but distorted" if there are interferences, e.g. broken sound due to overloaded system or too low connection bandwidth.
- Hand signals over video can be used, e.g. "waving/circling hands": "I am lost, please bring me into discussion again"; "T-Sign": "I need a break"; "Raised hand": "I would like to speak"
- Ask if people need a break, especially between topics and ideally announce this spoken and in chat to avoid confusion about the duration of the break
- Make the end of each meeting explicit. For example clearly mention when a meeting is done plus use visual cues like a chat message "daily is over" or the Jitsi "clapping hands" 👏 reaction. This ensures that people are engaged in the meeting and only staying as long as they want and can be engaged and not miss it when a new spontaneous meeting started end-to-end #153937
- Use https://etherpad.opensuse.org/p/suse_qe_tools for collaborative editing and put the content back into tickets or wikis. For a SUSE internal and hence more protected environment use https://etherpad.prg2.suse.org/
Daylight savings¶
- We would prefer UTC for meeting times but as many other SUSE meetings are bound to European time we usually observe German daylight savings
- Reminders in Slack correct for summer/winter time automatically but if you make changes the time might be shifted by one hour e.g. if you scheduled a reminder on 10:30 am CEST, it will become 9:30 CET
Workshop¶
- Time: Friday 0900-0950 CET/CEST every even week in meet.opensuse.org/suse_qa_tools especially for community members and users!
- Goal: Demonstrate new and important features, explain already existing, but less well-known features, and discuss questions from the user community. All your questions are welcome!
- Announcements: Consider to drop a reminder with a teaser in #eng-testing. On schedule changes consider updating https://calendar.opensuse.org/teams/qe-tools/events/suse-qe-tools-workshop
- Recordings: Consider recording, e.g. using OBS, and upload it to our YouTube channel. SUSE internal topics can be published on http://streaming.nue.suse.com/i/QE-Tools-Workshops/ by ssh-uploading to ftp@streaming.nue.suse.com:~/i/QE-Tools-Workshops/ (get your SSH key added by existing team members, e.g. okurz)
- Content: See topics!
Workshop Topics¶
- The SUSE QE Tools roadmap: Recent achievements, mid-term plan and future outlook. Every first Friday every even month
- Find older workshop topics and recordings on our SUSE QE Tools Workshop Archive
For the call details see Team Meetings
- 2025-01-10: DONE Onboarding experience in SUSE QE tools #168712 (@robert.richardson)
- 2025-01-24: DONE Increasing code coverage in os-autoinst based on example #167932 (@gpuliti)
- 2025-02-07: DONE SUSE QE Tools roadmap - 2025-02 (@okurz)
- 2025-02-21: DONE How to contribute to openQA based on example #134840 (@robert.richardson)
- 2025-03-07: DONE Allow variable expansion incorporating worker settings #169159 (@mkittler)
- 2025-03-21: DONE How we automatically update perl modules in devel:languages:perl (@tinita)
- 2025-04-04: DONE SUSE QE Tools roadmap - 2025-04 (@okurz)
- 2025-04-18: skipped due to common public holiday
- 2025-05-02: skipped due to common holiday bridging day
- 2025-05-16: DONE Automatic submission of openQA related packages using CI pipelines and openQA-in-openQA (@okurz, @jbaier_cz)
- 2025-05-30: skipped due to common holiday bridging day
- 2025-06-13: SUSE QE Tools roadmap - 2025-06
- 2025-06-27: meet us at the openSUSE conference
- 2025-07-11: Full version control awareness within openQA #58184 (@okurz)
- 2025-07-25: **
- 2025-08-08: skipped due to summer holiday period
- 2025-08-22: **
- 2025-09-05: **
- 2025-09-19: **
- 2025-10-03: skipped due to common public holiday
- 2025-10-17: SUSE QE Tools roadmap - 2025-10
- 2025-10-31: **
- 2025-11-14: **
- 2025-11-28: **
- 2025-12-12: SUSE QE Tools roadmap - 2025-12
- 2025-12-26: skipped due to common public holiday
- periodic proposal by okurz: How to report tickets, investigate issues, etc. (#104805)
- general proposal: if there are no further topics make it an "open conversation", at least from time to time :)
- proposal by okurz: Generic agile project management trainings and tutorials
- feedback from yearly workshop review: run it every second week but maybe longer, more interactive, more technical sessions, about backends and more openQA internals, from jlausuch: maybe understanding how svirt backend boots VMs in s390x, VMWare, etc? Highlight the differences between how qemu backend spawns VMs and how others do
Note: Everybody should feel welcome to add topic proposals here or approach us with ideas or requests.
Remove appointments from https://calendar.opensuse.org/ when events are skipped.
Announcements¶
- For every meeting, regular or one-off, desired attendants should be invited to make sure a slot blocked in their calendar and reminders with the correct local time will show up when it's time to join the meeting
- Create a new event, for example in Thunderbird via the Calendar tab or
New > Eventvia the menu. - Select individual attendants via their respective email addresses .g. Invite attendees in Thunderbird
- Specify the time of the meeting
- Set a schedule to repeat the event if applicable.
- Add a location, e.g. https://meet.opensuse.org/suse_qa_tools
- Don't worry if any of the details might change - you can update the invitation later and participants will be notified.
- Prefer new events if the time and date change
- Create a new event, for example in Thunderbird via the Calendar tab or
- See the respective meeting for regular actions such as communication via chat
Team¶
The team is comprised of engineers from different organisational units, some only partially available:
- Liv Dywan (Scrum Master - Ensure that we build it fast) @livdywan / @kalikiana
- Oliver Kurz (Product Owner - Ensure that we build the right thing) @okurz / @okurz
- Nick Singer (only infra) @nicksinger / @nicksinger
- Tina Müller (dev; Scrum Master Dev April 31 - May 16, see #179966) (Part time (35h)) @tinita / @perlpunk
- Dominik Heidler (both dev and infra) @dheidler / @dheidler
- Marius Kittler (mod, dev) @mkittler / @Martchus
- Yannis Bonatakis (dev) @ybonatakis / @b10n1k
- Robert Richardson (mod, infra) @robert.richardson / @r-richardson
- Gaurav Pathak (mod, infra) @gpathak / @gauravpathak
- Gabriele Puliti (mod, dev) @gpuliti / @wabri
- Emil Miler (mod, dev, March 26 2025 - June 20) @emiler / @realcharmer
Sebastian Riedel (mostly working on other projects currently, only bug fixing and feature development) @kraih / @kraih-
Jan Baier (part time, QEM-dedicated work areas) @jbaier_cz / @baierjan(on a temporary assignment in UV squad)
Onboarding for new joiners¶
- For mentors: https://plan.io/blog/hire-remote-developers/
Communication¶
- Subscribe to opensuse-factory@opensuse.org
- Connect to
#opensuse-factoryon libera.chat, see Common tasks/ Monitoring - Consider logging in with the osd-admins mailing list with the according password to add yourself to the list of admins
OBS¶
- Request to join qe-tools-team on OBS and check that you have
Request created,New comment for request created,New comment for package createdenabled forMaintainer of the targetin your OBS notification settings - Add devel:openQA on OBS to your watchlist
Github¶
- Request to get added to the os-autoinst Tools team on GitHub as well as the openSUSE Tools team (Link throws 404 if not org member, existing members can filter for owners to ask for new members to be added) and subscribe to notifications for projects within that organization
- Once you have been added to these two teams, create an account on CircleCI and join the os-autoinst org on CircleCI (which will prompt for your GitHub login) and change the "User Settings -> Project notifications" to be notified by "All builds in my project" and make sure you have your @suse.com email address selected for "openSUSE" and "os-autoinst"
- Watch qa-tools-backlog-assistant and choose All Activity
- Subscribe to notifications of the Mojo-IOLoop-ReadWriteProcess project on GitHub as it is also closely related to openQA development
- Ensure you are subscribed to all projects referenced in Common tasks for team members
Other¶
- Request to get added to the QA project in Progress and enable notifications for the "QA" project in your account settings
- Watch this wiki page (click "Watch" button on top of this page)
- SUSE internal onboarding: https://gitlab.suse.de/suse/wiki/-/blob/main/qe_infrastructure.md?#suse-qe-tools-team-onboarding
Offboarding¶
When someone leaves the team the following steps should be taken
- Conduct a team-internal exit-interview (Learn about what was good, what can be improved, what to learn)
- Remove from https://github.com/orgs/os-autoinst/teams/tools-team . Optionally add the people still as contributors with additional priviledges to individual projects
- Remove from team calendars
Alert handling¶
Best practices¶
- "if it hurts, do it more often": https://www.martinfowler.com/bliki/FrequencyReducesDifficulty.html
- Reduce Mean-time-to-Detect (MTTD) and Mean-time-to-Recovery
Process¶
- React on any alert or report of an outage
- If users report outages of components of our infrastructure
- Ensure there is a ticket on the backlog tracking the issue
- For any user-facing outages
- Consider teaming up and assigning individual tasks to focus on
- Inform affected users about the impact and ETA via chat channels, ticket updates and mailing list posts
- Look into mitigations and short-term workarounds such as a hotpatch in production or a revert to an older release
- Investigate a proper solution with a conservative estimate on the effort involved
- Set a time limit to ensure either a workaround or a solution is available within a reasonable amount of time (for example 4 hours or end of working day of the person communicating the changes)
- Join an ad-hoc video call to discuss further steps
- Keep a record of what was discussed and investigated to allow for a later analysis
- Look into symptoms such as restarting incomplete jobs
- For each failing alert, e.g. Grafana, failing CI pipelines, etc.
- Create a ticket for the issue (with a tag "alert"; create ticket unless the alert is trivial to resolve and needs no improvement; if an alert is unhandled for at least 4h then a ticket must be created; even create a ticket if alerts turn to "ok" to prevent these issues in the future and to improve the alert)
- Link the corresponding ... in the ticket
- Grafana panel as reference in the alert email
- Details of the failing job in case of an Unreviewed issue alert
- Pipeline name and link in case of GitLab
- Copy relevant metadata from the email, especially date and time, mentioned hostname(s) and the subject of the email
- Respond to the notification email with a link to the ticket or forward the email to a corresponding mailing list, e.g. o3-admins@suse.de or osd-admins@suse.de (Caveat: gitlab@suse.de as sender seems to be able to receive emails and swallow them without any useful response or error message)
- Optional: Inform in chat
- Optional: Add "annotation" in corresponding Grafana panel with a link to the corresponding ticket
- Silence/pause the alert to mitigate urgency and reduce the priority of the ticket
- For grafana just follow the "silence" button in alert emails or use https://monitor.qa.suse.de/alerting/silences, consider a default of 2 months, reference the ticket and mention to remove the silence in the ticket in "Rollback actions". Alternatively if you as ticket assignee want to be notified on alerts but to not distract others on https://monitor.qa.suse.de/alerting/routes click next to the policy for
__contacts__ =~ .*"osd-admins".*on "New nested policy" and add direct messages to yourself instead of the mailing list. Also mention that in "Rollback actions" - GitLab pipelines can be paused after taking ownership (think of it as who touched it last, not who maintains it)
- In Zabbix a problem can be suppressed
- When observing an Unknown issue, file a ticket and add it in a comment on the job and consider an autoreview regex in case it affects multiple test modules
- To address openqa logwarn issues, add the message to the list of known messages (and potentially look into changing the message or log level later)
- See Munin
- See gitlab pipeline notifications
- For grafana just follow the "silence" button in alert emails or use https://monitor.qa.suse.de/alerting/silences, consider a default of 2 months, reference the ticket and mention to remove the silence in the ticket in "Rollback actions". Alternatively if you as ticket assignee want to be notified on alerts but to not distract others on https://monitor.qa.suse.de/alerting/routes click next to the policy for
- If you consider an alert non-actionable then change it accordingly
- If you do not know how to handle an alert ask the team for help
- We must always strive for an accepted hypothesis when we want to change alerts or call an issue resolved
- After resolving the issue add explanation in ticket, unpause alert and verify it going to "ok" again, resolve ticket
References¶
- https://nl.devoteam.com/en/blog-post/monitoring-reduce-mean-time-recovery-mttr/
- Also see https://gitlab.suse.de/suse/wiki/-/blob/main/qe_infrastructure.md for SUSE internal infrastructure alert handling
Munin¶
- To completely disable alert emails from munin: in
/etc/munin/munin.conf, comment out the linecontact.o3admins.command. - For individual plugins it is necessary to read the plugin docs, e.g. in
/etc/munin/plugins/dfyou can see how to adjust the values for warning and critical. You then put this in/etc/munin/plugin-conf.d/munin-nodeand thensystemctl restart munin-node, e.g.
[df]
env.exclude none unknown rootfs iso9660 squashfs udf romfs ramfs debugfs cgroup_root devtmpfs
env.warning 92
env.critical 98
Weekly alert duty¶
We all should react on alert but additionally we can have one person on "alert duty" for one week each to ensure quicker reaction times when other team members are focussed on development work. For this the person on duty should do the following:
- React quickly (e.g. within two hours) on any unhandled alerts
- Hand over to the next person after the weekly, going by the order of team members in the wiki
- Asks for standin on unavailabilities
Collaboration best practices¶
Sometimes there are pull requests that are based on other pull requests. Person X reviews PR 1 and Person Y reviews PR 2, but they share the same commit. As a result we have more work for all. For a best practice it is recommended to
- Include keywords in the PR subject line, e.g. "Part 2: … - based on #<previous_pr>". Example: https://github.com/os-autoinst/openQA/pull/4473
- Include the list of base pull request(s) in the PR description. Keep in mind that pull request links in github only seem to be properly rendered as preview links when included in a Markdown list, e.g.
Based on
* #1234
- Mark the dependant pull request as draft until the base pull request is approved or merged
See #105244 for the motivation for these best practices
openQA short video creation¶
We create short videos informing about openQA and its usage from time to time. (Example)
The recommended tools are Kdenlive, Audacity and OBS.
Create a script of what to say during the video¶
- Try to make it fit 60 seconds
- Think about if the subject is actually suitable for a short
- If you have previously held a presentation on the subject which was recorded, you can save time by converting the transcript to a 60 second short script draft using Gemini and then adjusting that
Record a rough version of the vocals in one take (Using e.g. Audacity)¶
- Ignore mispronunciations and small audio issues for now
- Cut pauses and background noise out, as far as possible
- Adjust/Restructure the script, then restart from step 2 until the script actually fits one minute.
Record the visuals (Using e.g. builtin screen capture or OBS)¶
- Video material may exceed 60s, as we can speed up playback in the next step
- Vertical screen (16:9) orientation
- Try to only create 1080p/30fps content or better
Align the audio and visuals (Using e.g. Kdenlive)¶
- When creating a new Kdenlive Project, select
Custom->Vertical HD 60 fpsorCustom->Vertical HD 30 fps - Increase the speed (Hold
CTRLto be able to "squeeze" clips) for anything happening on the screen that is taking too much time, and is not mentioned in the script or otherwise important to point out. (Cut as few visuals as possible, try to only speed them up) - To be able to select multiple clips, hold
SHIFT, then click and drag. - To be able to have a single effect target multiple elements at a time, select multiple clips and use the "Create Sequence from Selection", then apply a effect to the sequence
- To move elements use
Effects->Transform, Distort and Perspective->Transformand create the desired keyframes. - This can be used to pan and zoom the screen by moving and resizing the main sequence.
- You can use
Project->Add Title Clipto quickly create a overlay text or a transparent rectangle with a colored frame which can be used to highlight specific elements on the screen. - Make sure the visuals are "snappy". Every few seconds there should either be camera movement or a cut.
- Add (or hide) a Geeko somewhere within the short.
Re-record and align audio¶
- Find a good spot to record (e.g. record in a small room, or use a blanket to further dampen the sound)
- Do multiple takes in a row for each section of the script without changing the recording setup.
- Align the best audio recordings with the the visuals and delete the initial audio track
Things to try¶
- Everybody can be "Product Owner" or "Scrum Master" or "Admin" or "Developer" for some time to get the different perspective
- From time to time ask stakeholders for their list of priorities regarding our tasks
- Seelect mob-programming tasks in unblock meetings to deep-dive in dedicated meeting
Literature references¶
Historical¶
Previously the former QA tools team used target versions "Ready" (to be planned into individual milestone periods or sprints), "Current Sprint" and "Done". However the team never really did use proper time-limited sprints so the distinction was rather vague. After having tickets "Resolved" after some time the PO or someone else would also update the target version to "Done" to signal that the result has been reviewed. This was causing a lot of ticket update noise for not much value considering that the Definition-of-Done when properly followed already has rather strict requirements on when something can be considered really "Resolved" hence the team eventually decided to not use the "Done" target version anymore. Since about 2019-05 (and since okurz is doing more backlog management) the team uses priorities more as well as the status "Workable" together with an explicit team member list for "What the team is working on" to better visualize what is making team members busy regardless of what was "officially" planned to be part of the team's work. So we closed the target version. On 2020-07-03 okurz subsequently closed "Current Sprint" as also this one was in most cases equivalent to just picking an assignee for a ticket or setting to "In Progress". We can just distinguish between "(no version)" meaning untriaged, "Ready" meaning tools team should consider picking up these issues and "future" meaning that there is no plan for this to be picked up. Everything else is defined by status and priority.
In 2020-10-27 we discussed together to find out the history of the team. We clarified that the team started out as a not well defined "Dev+Ops" team. "team responsibilities" have been mainly unchanged since at least beginning of 2019. We agreed that learning from users and production about our "Dev" contributions is good, so this part of "Ops" is responsibility of everyone.
Also see #73060 for more details about how the responsibilities were setup.
Team-internal Hack Week (or Hackweek)¶
Rules of the game¶
- Regular meetings with the exception of the Weekly are cancelled
- Look into future tickets or other projects that relate to our usual work
- Backlog priorities are not enforced, short of emergency responses
- The challenge has to be solved the previous week, weekly to weekly
Extra-ordinary "hack-week" 2020-W51¶
SUSE QE Tools plans to have an internal "hack-week": Condition: We close 30 tickets from our backlog within the time frame 2020-12-03 until 2020-12-11 start of weekly meeting. No cheating! :) See this query. During week 2020-W51 everyone is allowed to work on any hack-week project, it should just have a reasonable, "explainable" connection to our normal work. okurz volunteers to take over ops-duty for the week.
Result during meeting 2020-12-11: We missed the goal (by a slight amount) but we are motivated to try again in the next year :) Everybody, put some easy tickets aside for the next time!
Extra-ordinary "hack-week" 2021-W8¶
Similar as our attempt for 2020-W51 with same rules, except condition: We close 30 tickets from our backlog within the time frame 2021-02-05 until 2021-02-19 start of weekly meeting. No cheating! See this query.
Result during meeting 2021-02-19: We missed the goal (25/30 tickets resolved) but again we are open to try again, maybe after next SUSE hack week.
Extra-ordinary "hack-week" 2022-W9¶
Same as in before, similar condition: We close 30 tickets from our backlog within the time frame 2022-02-18 until 2022-02-25 start of weekly meeting. No cheating! See this query.
Change announcements¶
For new, cool features or disruptive changes consider providing according notifications to our common userbase as well as potential future users, for example create post on opensuse-factory@opensuse.org , link to post on openqa@suse.de , invite for workshop, #opensuse-factory (IRC) (irc://irc.libera.chat/opensuse-factory), #testing (Slack)
Updated by okurz 13 days ago · 579 revisions