action #138593
closedcoordination #154768: [saga][epic][ux] State-of-art user experience for openQA
coordination #157345: [epic] Improved test reviewer user experience
Restart of scheduled products is prone to retriggers by humans size:S
Description
Observation¶
I found many scheduled test suites waiting for ipmi workers, but the number of running tests (also using ipmi worker) is less than the number of ipmi workers. It is very obvious and can be seen easily in openQA Build page like this https://openqa.suse.de/tests/overview?distri=sle&version=15-SP6&build=28.1&groupid=263.
I learned that llzhao reran the whole product, because she did not find a way to rerun only her job group. Maybe this can be considered within this feature request or a new one.
Steps to reproduce¶
- Will update if there are known steps help reproduce
Impact¶
Workers are already assigned to tests that are supposed to stop. So resource is wasted.
Problem¶
After investigating this a while, I found some workers are executing some tests secretly, which means it can not be seen from above openQA Build page, for example:
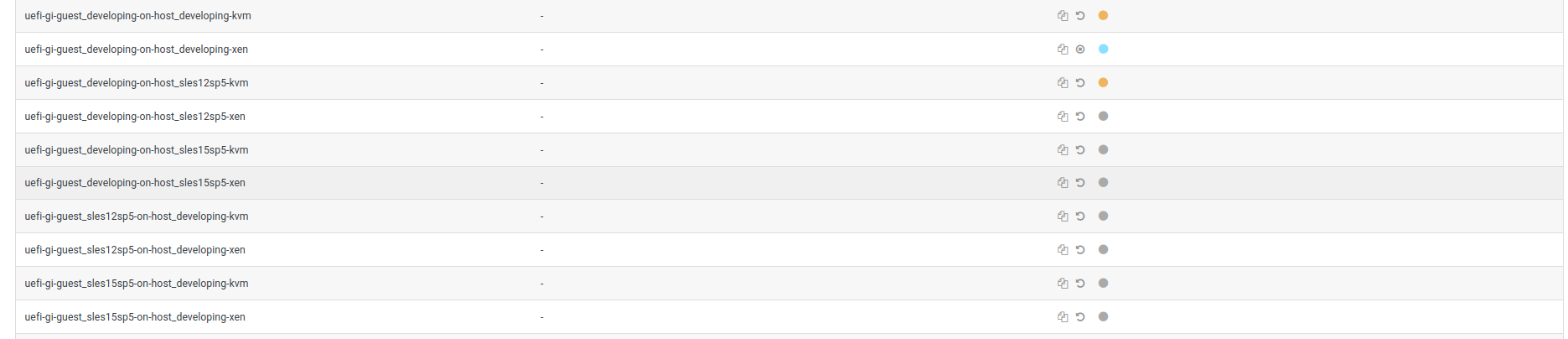
All test suites were already cancelled.
But after navigating into specific worker page, I found it was executing a test suite secretly, for example:

Because the running one is not on top, so it can not be seen by just look up in openQA job group or build page.
Let's take worker sapworker3:2 and test suite sle-15-SP6-Online-x86_64-Build28.1-uefi-gi-guest_sles12sp5-on-host_developing-kvm@64bit-ipmi-large-mem as an example. The scheduled test run https://openqa.suse.de/tests/12668997 was already cancelled, and it is expected to stop. But it was then triggered and run again secretly as another test run https://openqa.suse.de/tests/12664633 without being displayed in openQA job group or build page. Although the test number 12664633 is smaller than 12668997, the 12668997 was cancelled hours earlier. And I confirmed sapworker3:2 is assigned to test 12664633 after it became idle, and at that time point, test 12668997 was already cancelled hours ago. The 12664633 is hidden in sapworker3:2 worker page, for example:
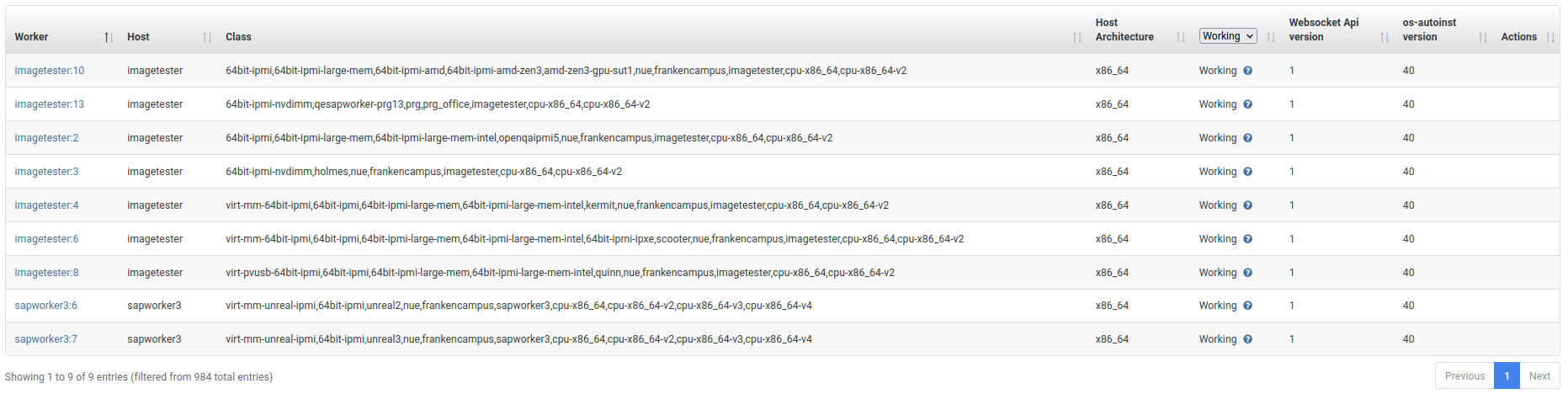
So I have to click the "working" button right to sapworker3:2 to discover it.
I did not manually triggered or scheduled any relevant test for this issue.
Suggestions¶
- Show running test run always on top if feasible
- Better schedule and trigger logic
- Make the "restart" icon for products a proper button with a frame and a label like "Restart the whole product"
- Move the button out of the area with the labels (results, product, assigned) e.g. more to the right
- Additionally consider a confirmation dialogue (maybe with xy jobs restarted if possible)
Workaround¶
n/a
Acceptance Criteria¶
- AC1: Accidental retriggers of complete products from test details pages are less likely
Out of scope¶
- Partial scheduling of products #157342
Files
| Selection_284.png (49.9 KB) Selection_284.png | |||
| Selection_283.png (110 KB) Selection_283.png | |||
| Selection_285.png (121 KB) Selection_285.png | |||
| Selection_284.png (49.9 KB) Selection_284.png | |||
| Selection_283.png (110 KB) Selection_283.png | |||
| Selection_285.png (121 KB) Selection_285.png | |||
| Selection_287.png (78.2 KB) Selection_287.png | |||
| Selection_288.png (99.2 KB) Selection_288.png | |||
| 6th_rounds.png (39.8 KB) 6th_rounds.png | |||
| 5th_rounds.png (45 KB) 5th_rounds.png | |||
| 4th_rounds.png (44 KB) 4th_rounds.png | |||
| 3rd_rounds.png (45.4 KB) 3rd_rounds.png | |||
| screenshot__Y_M_D__H_m_S.png (92.9 KB) screenshot__Y_M_D__H_m_S.png | re-scheduling of https://openqa.suse.de/tests/14610658 |
Updated by waynechen55 over 1 year ago
- Subject changed from [openQA][worker][assignment][job] Some jobs triggered and executed secretly without being noticed to [openQA][worker][schedule][assignment][job] Some jobs triggered and executed secretly without being noticed
Updated by Julie_CAO over 1 year ago
There were two rounds of product triggering:
Scheduled product 1980120
| Time | User | Status | Distri | Version | Flavor | Arch | Build | ISO | Actions |
|---|---|---|---|---|---|---|---|---|---|
| about 16 hours ago | geekotest | scheduled | SLE | 15-SP6 | Online | x86_64 | 28.1 | SLE-15-SP6-Online-x86_64-Build28.1-Media1.iso |
Scheduled product 1980232
| Time | User | Status | Distri | Version | Flavor | Arch | Build | ISO | Actions |
|---|---|---|---|---|---|---|---|---|---|
| about 14 hours ago | geekotest | scheduled | SLE | 15-SP6 | Online | x86_64 | 28.1 | SLE-15-SP6-Online-x86_64-Build28.1-Media1.iso |
Updated by okurz over 1 year ago
- Subject changed from [openQA][worker][schedule][assignment][job] Some jobs triggered and executed secretly without being noticed to [openQA][worker][schedule][assignment][job][qe-core] Some jobs triggered and executed secretly without being noticed
@qe-core this looks like an issue in obs-rsync-trigger. Can you take a look?
Updated by waynechen55 over 1 year ago
- File Selection_287.png Selection_287.png added
- File Selection_288.png Selection_288.png added

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Updated by Julie_CAO over 1 year ago
- File 6th_rounds.png 6th_rounds.png added
- File 5th_rounds.png 5th_rounds.png added
- File 4th_rounds.png 4th_rounds.png added
- File 3rd_rounds.png 3rd_rounds.png added
For build #28.1, except those two rounds of build initially, there have been 4 more rounds in these 4 days. It has exausted lots of resources and brought us much troubles to handle these tests. @xlai




Updated by xlai over 1 year ago
I raised the topic of multiple openqa triggering of same build , in https://suse.slack.com/archives/C02CANHLANP/p1698981583137759. Hope more attention can be given and avoid it.
@ybonatakis @emiura I am not sure if I am reaching the same ones that have openqa accounts mentioned in https://progress.opensuse.org/issues/138593#note-7. Please forgive me if not. If it is correct, I would appreciate if you can share why you need to rerun such a large range of tests, including virtualization, for build 28.1. Thanks!
@szarate Hello Santi, would you please help a look why two times of geekotest triggering for the build? Any bug to fix on CI tool?
Updated by ybonatakis over 1 year ago
xlai wrote in #note-8:
I raised the topic of multiple openqa triggering of same build , in https://suse.slack.com/archives/C02CANHLANP/p1698981583137759. Hope more attention can be given and avoid it.
@ybonatakis @emiura I am not sure if I am reaching the same ones that have openqa accounts mentioned in https://progress.opensuse.org/issues/138593#note-7. Please forgive me if not. If it is correct, I would appreciate if you can share why you need to rerun such a large range of tests, including virtualization, for build 28.1. Thanks!
This meant to run only HPC test group from my side. Usually it just do that. I dont know why Virtualization tests re-triggered.
@szarate Hello Santi, would you please help a look why two times of geekotest triggering for the build? Any bug to fix on CI tool?
Updated by xlai over 1 year ago
ybonatakis wrote in #note-9:
xlai wrote in #note-8:
I raised the topic of multiple openqa triggering of same build , in https://suse.slack.com/archives/C02CANHLANP/p1698981583137759. Hope more attention can be given and avoid it.
@ybonatakis @emiura I am not sure if I am reaching the same ones that have openqa accounts mentioned in https://progress.opensuse.org/issues/138593#note-7. Please forgive me if not. If it is correct, I would appreciate if you can share why you need to rerun such a large range of tests, including virtualization, for build 28.1. Thanks!
This meant to run only HPC test group from my side. Usually it just do that. I dont know why Virtualization tests re-triggered.
@ybonatakis thanks for the reply. Would you please paste your trigger command here, so that the relevant team may help to find out the reason? From https://openqa.suse.de/admin/productlog?id=1988393, there is a long successful job list which seems much more than HPC only.
BTW, did you specify "TEST=" in your command? If nothing given, but only mediums info provided, all tests binded to that would be rerun. That used to happen on OSD before by accident.
Updated by emiura over 1 year ago
xlai wrote in #note-8:
I raised the topic of multiple openqa triggering of same build , in https://suse.slack.com/archives/C02CANHLANP/p1698981583137759. Hope more attention can be given and avoid it.
@ybonatakis @emiura I am not sure if I am reaching the same ones that have openqa accounts mentioned in https://progress.opensuse.org/issues/138593#note-7. Please forgive me if not. If it is correct, I would appreciate if you can share why you need to rerun such a large range of tests, including virtualization, for build 28.1. Thanks!
@szarate Hello Santi, would you please help a look why two times of geekotest triggering for the build? Any bug to fix on CI tool?
@xlai
I'm sorry for the trouble, my intention was to restart the teststo check if registry related errors had been fixed. It will not happen again.
Updated by waynechen55 over 1 year ago
For Build34.1 and Build37.1, the historical scheduled products are as below:
1992810 a day ago epaolantonio scheduled SLE 15-SP6 Online x86_64 37.1 SLE-15-SP6-Online-x86_64-Build37.1-Media1.iso
1990407 8 days ago geekotest scheduled SLE 15-SP6 Online x86_64 34.1 SLE-15-SP6-Online-x86_64-Build34.1-Media1.iso
Updated by waynechen55 over 1 year ago
@ybonatakis It seems you scheduled test for Build39.1 again. All virtualization tests are running again now.
about an hour ago ybonatakis scheduled sle 15-SP6 Online x86_64 39.1 SLE-15-SP6-Online-x86_64-Build39.1-Media1.iso
Why do you need to do this ?
Updated by xlai about 1 year ago
Similar thing happens again. Individuals triggers full build test accidentally. It's also raised and discussed in https://suse.slack.com/archives/C0564EU665S/p1709176558631769.
Updated by szarate about 1 year ago
- Copied to action #156277: [qe-core] Some jobs are retriggered by geekotest (likely obs-sync plugin) without clear answer why added
Updated by szarate about 1 year ago
- Project changed from openQA Infrastructure (public) to openQA Project (public)
- Subject changed from [openQA][worker][schedule][assignment][job][qe-core] Some jobs triggered and executed secretly without being noticed to Restart of scheduled products is prone to retriggers by humans
- Description updated (diff)
- Assignee set to okurz
- Priority changed from High to Normal
- Target version changed from QE-Core: Ready to future
- Parent task set to #154768
Following up my message over slack, on @xlai's thread:
Shall we take some actions to avoid that? Eg, forbid it on the web UI to rerun scheduled product? Or bump access right for that button?
One of the things I was discussing days ago with @Oliver Kurz was the possibility of having RBAC - Role Based Access Control in openQA so that things like restarting a whole product is behind a specific permission. because, at the moment, everybody basically can.
Another possibility is fixing the UI, as mentioned by @Xiaoli Ai, but eventually, we’ll have to get there.
We can focus first on moving the restart button for scheduled products behind an admin permission. Look into the RBAC later
Updated by xlai about 1 year ago
Just for clarification:
The historical comments and the original ticket description may mix two issues up.
- In this ticket, please focus on what the ticket title gives -- Restart of scheduled products is prone to retriggers by humans, which will need the help from openqa tool to improve. For anyone helps with it, please focus on related comments for it only.
- the other issue of multiple triggers by geekotest has been scoped into a new ticket #156277.
Updated by ybonatakis about 1 year ago
I am new to the discussion but as a user who have fell into the mistake of trigger incidentally jobs for other job groups I want to say that I disagree with the suggestion of an admin permission for that. Usually the problem is the misuse or misunderstanding of pressing a button or of openqa-cli. Instead, I would like to have a prompt and a warning before the execution.
For example when i do an post isos from the console, and if this has a results to schedule a whole job group, I would expect a prompt which shows me what it is going to schedule and ask for confirmation to continue.
Updated by okurz about 1 year ago
I also question both the ACs
- "RBAC is implemented or an Epic for its implementation exists": IMHO that already exists. We already have three different levels with user, operator, admin. What do you see as missing here?
- Restart of Scheduled produtcs is put behind a higher level permission (Admin?)
Same as ybonatakis stated that wouldn't help: we have many admins and they can still make a mistake. And others might still have a valid need to retrigger. I would like us to check why we even have that retrigger button on the job details page as we already have one in the "scheduled products" page where I think it shows more clearly that many jobs would be affected
Updated by Julie_CAO about 1 year ago
The entire build 59.2 was retriggered again ...
about 11 hours ago coolo scheduled SLE 15-SP6 Online x86_64 59.2 SLE-15-SP6-Online-x86_64-Build59.2-Media1.iso
Updated by Julie_CAO about 1 year ago
One more retrigger ...
about 12 hours ago dheidler scheduled SLE 15-SP6 Online x86_64 59.2 SLE-15-SP6-Online-x86_64-Build59.2-Media1.iso
Updated by okurz about 1 year ago
- Status changed from New to Feedback
No response on #138593-21, lowering prio
Updated by xlai about 1 year ago
okurz wrote in #note-24:
No response on #138593-21, lowering prio
I would like us to check why we even have that retrigger button on the job details page as we already have one in the "scheduled products" page where I think it shows more clearly that many jobs would be affected
I vote for this too. Maybe removing the button of rescheduling products from job details page can decrease such accidental trigger. Anyone would like to do so, better to go to "scheduled products" page.
Then how about those accidental triggers from command line via openqa-cli?
Updated by okurz about 1 year ago
- Description updated (diff)
- Category set to Feature requests
- Status changed from Feedback to New
- Assignee deleted (
okurz)
ok. I replaced the two questionable ACs with "* AC1: Accidental retriggers of complete products from test details pages are less likely"
Updated by okurz about 1 year ago
- Related to action #157342: Partial product re-scheduling scheduled whole build added
Updated by Julie_CAO about 1 year ago
one more time again today:
about 4 hours ago llzhao scheduled SLE 15-SP6 Online x86_64 88.1 SLE-15-SP6-Online-x86_64-Build88.1-Media1.iso
Updated by xlai about 1 year ago
- Status changed from New to Workable
- Priority changed from Low to High
Given the large impact of accidental re-triggering of whole product and not very high effort to remove the button from job details page, suggest to bump the priority and do it sooner.
@okurz Is it possible to plan into tools team's recent sprints?
Updated by okurz about 1 year ago
- Status changed from Workable to New
- Priority changed from High to Normal
- Target version changed from future to Ready
Careful when changing the fields. This ticket is not workable according to https://progress.opensuse.org/projects/qa/wiki/Tools#Definition-of-READY-for-new-features
We will look into this with high priority. Be aware though that we don't have sprints.
Removing the button might be easy but also it was added based on a certain request so it's not as easy as that. But I am certain we will be able to find a better solution
Updated by xlai about 1 year ago
okurz wrote in #note-31:
Careful when changing the fields. This ticket is not workable according to https://progress.opensuse.org/projects/qa/wiki/Tools#Definition-of-READY-for-new-features
Oops, sorry. Which item do you think is missing for workable?
We will look into this with high priority. Be aware though that we don't have sprints.
I see.
Removing the button might be easy but also it was added based on a certain request so it's not as easy as that. But I am certain we will be able to find a better solution
Cool, thanks!
BTW, just for your information, I learned that llzhao reran the whole product, because she did not find a way to rerun only her job group. Maybe this can be considered within this feature request or a new one.
Updated by okurz about 1 year ago
xlai wrote in #note-32:
okurz wrote in #note-31:
Careful when changing the fields. This ticket is not workable according to https://progress.opensuse.org/projects/qa/wiki/Tools#Definition-of-READY-for-new-features
Oops, sorry. Which item do you think is missing for
workable?
The ticket has good details but we need the tools team to estimate the ticket and verify that we have all necessary information about the goal and starting steps
BTW, just for your information, I learned that llzhao reran the whole product, because she did not find a way to rerun only her job group. Maybe this can be considered within this feature request or a new one.
That would be related to
#157342 but "just one job group" is a kinda special request. We will have to see if it fits within what we can do with the webUI or just CLI tooling
Updated by livdywan about 1 year ago
- Subject changed from Restart of scheduled products is prone to retriggers by humans to Restart of scheduled products is prone to retriggers by humans size:S
- Description updated (diff)
Updated by mkittler 12 months ago
The PR has been merged and deployed (on o3 at least). I got a "thumbs-up" reaction on the PR by @Julie_CAO.
The feedback about the buttons I got on Slack is also good. The explicitness also triggered some questions - but I guess that's a good thing. Some minor tweaks to apply (considering the Slack conversation so far):
- Don't show "Actions:" at all if there are no actions to show. It already doesn't show if the user has not the right permissions but it shows on jobs that have already been restarted. Maybe it would make more sense to make that explicit (instead of hiding the button completely), e.g. show the restart button but disabled and with a popover stating that the job has already a clone so it cannot be restarted.
- Maybe mention in the help popover for restating where to find the advanced options. (The "<" on the left is maybe a bit too subtle on its own.)
Updated by xlai 12 months ago
Hi @mkittler ,
Thanks for the effort on this.
To me, it is much more differentiated for the two rerun buttons now. I believe it will give less chance that the rerun button is clicked by mistake. Nice improvement!
I still have some confusion here on the explanation for the button Reschedule product from here in job details page. Would you please explain the difference between it and rescheduling product tests in https://openqa.suse.de/admin/productlog?
Updated by mkittler 11 months ago
@xlai Note that the "Reschedule from here" button was added for #124469. It is not just a shortcut for the button on the product log page. The requirement was to re-schedule a product only partially starting from a specific job. Only this "start job" and its child dependencies (but not parents) were supposed to be scheduled again. So that is what this feature does - as explained in the help text/icon next to the button.
I'll see whether it makes sense to implement ideas from #138593#note-39 after the bootstrap migration (because it would cause conflicts).
Updated by mkittler 11 months ago
- Status changed from Workable to Feedback
PR to implement additional improvements: https://github.com/os-autoinst/openQA/pull/5688
I would consider the ticket resolved when it has been merged.
Updated by xlai 11 months ago
- Status changed from Resolved to Workable
@okurz @mkittler Hi guys, given the explanation in https://progress.opensuse.org/issues/138593#note-42, it seems there was misunderstanding before in the discussion. It turns out that clicking the "wrong" rerun button in job detail page, would not have caused so many large scale tests, eg those actions of rerunning HPC job group, but in the end virtualization jobs were all rerun, which had no dependency to HPC jobs at all. Then it seems that the most "wrong" product rerun actually came from cmd openqa-cli.
Would you please have a look at comment https://progress.opensuse.org/issues/138593#note-10 and https://progress.opensuse.org/issues/138593#note-20, and help find some way to decrease such accidental triggers from command line via openqa-cli, eg by adding some warnings and confirmation before proceeding?
Sorry for the late request due to misunderstanding before. But this is crucial to avoid accidental product trigger in future.
Updated by mkittler 11 months ago
What was the openqa-cli command that was invoked accidentally? And what was the command that should have been invoked instead? With that information we could think how to improve openqa-cli. However, we should keep in mind that breaking compatibility of openqa-cli is probably a bad idea as well. Maybe we can create a new user friendly sub command for whatever the use case was or add a --dry-run feature to the existing command and advertise its use.
Updated by xlai 11 months ago
mkittler wrote in #note-48:
What was the openqa-cli command that was invoked accidentally? And what was the command that should have been invoked instead? With that information we could think how to improve openqa-cli. However, we should keep in mind that breaking compatibility of openqa-cli is probably a bad idea as well. Maybe we can create a new user friendly sub command for whatever the use case was or add a
--dry-runfeature to the existing command and advertise its use.
@ybonatakis Would you please provide some input for above based on your #note-20?
ybonatakis wrote in #note-20:
I am new to the discussion but as a user who have fell into the mistake of trigger incidentally jobs for other job groups I want to say that I disagree with the suggestion of an admin permission for that. Usually the problem is the misuse or misunderstanding of pressing a button or of openqa-cli. Instead, I would like to have a prompt and a warning before the execution.
For example when i do anpost isosfrom the console, and if this has a results to schedule a whole job group, I would expect a prompt which shows me what it is going to schedule and ask for confirmation to continue.
Updated by xlai 11 months ago · Edited
@mkittler
This morning, there is one more problematic product rerun from job details page via Reschedule product from here button. To me, it seems a bug of the button that it does not only trigger CHILD jobs, but only jobs without dependency at all.
Rescheduled product link is https://openqa.suse.de/admin/productlog?id=2180274. From it, you can see overall 974 jobs got rerun.
The owner (@tinawang123 ) did not remember exactly the job that she clicked the button. But she confirmed below:
- she just clicked
Reschedule product from herebutton from one of the failure jobs in Yast 15sp6 job group, https://openqa.suse.de/tests/overview?distri=sle&version=15-SP6&groupid=129&build=93.5. - The most complex dependency is this , https://openqa.suse.de/tests/14611144#dependencies, less than 900. If only CHILD Jobs are supposed to be rerun, it shall be less than that.
- she guess the job that she clicks reschedule product button is yast2_cmd@64bit, the link given above, but I can't tell now because the wrong triggered jobs have been deleted by her
- I observed irrelevant jobs (not child or parent jobs to any of the job in the group) got rerun via this test, https://openqa.suse.de/tests/14610325#next_previous. But now the job has been deleted via openqa-cli. You shall be able to get it from logs.
More background info:
- why she clicks that button
Reschedule product from here: she updated some settings, then click theRestart this and dependent jobswon't have the updated setting, so she clicked it
Maybe this is one of the main root causes for the initial problem -- virtualization jobs got rerun multiple times? Please help have a look. Thanks.
Updated by mkittler 11 months ago
Ok, that's useful information. The number of re-triggered jobs should indeed not exceed 900 in that case. I will import a production database dumb and see whether I can reproduce the problem.
Note that she was also generally correct to click the button to make use of updated settings from tables like test suites. This aspect was one of the reasons why we initially added the feature. It might be helpful to know what settings have changed. If dependency-related settings have changed this might make a difference.
Updated by xlai 11 months ago
mkittler wrote in #note-51:
Ok, that's useful information. The number of re-triggered jobs should indeed not exceed 900 in that case. I will import a production database dumb and see whether I can reproduce the problem.
Glad to know that. Thank you!
Note that she was also generally correct to click the button to make use of updated settings from tables like test suites. This aspect was one of the reasons why we initially added the feature. It might be helpful to know what settings have changed. If dependency-related settings have changed this might make a difference.
I asked @tinawang123 , she said she only added this setting START_AFTER_TEST: 'create_hdd_textmode', no other setting change.
Updated by mkittler 11 months ago
- Status changed from Workable to In Progress
I was able to reproduce the problem, see https://github.com/os-autoinst/openQA/pull/5706. I also mentioned in that PR that there are unfortunately more problems with the partial rescheduling.
Updated by openqa_review 11 months ago
- Due date set to 2024-07-02
Setting due date based on mean cycle time of SUSE QE Tools
Updated by mkittler 11 months ago
- Status changed from In Progress to Feedback
PR to fix dependencies: https://github.com/os-autoinst/openQA/pull/5707
After that is merged and deployed I would consider this issue resolved.
Updated by xlai 11 months ago
Ok, that's useful information. The number of re-triggered jobs should indeed not exceed 900 in that case. I will import a production database dumb and see whether I can reproduce the problem.
@mkittler Thanks for the fixes. May I ask for some data? With your above 2 fixes, how many jobs shall actually be rerun for the scene that the problem was triggered?
Updated by okurz 11 months ago
@xlai I can't directly answer your question but as of today https://github.com/os-autoinst/openQA/pull/5707 is deployed also on OSD. Changelog notification message in https://mailman.suse.de/mlarch/SuSE/openqa/2024/openqa.2024.06/msg00014.html . If you are using the different retriggering features maybe you will observe the change in behaviour and can verify that it's working better now.
Updated by mkittler 11 months ago
@mkittler Thanks for the fixes. May I ask for some data? With your above 2 fixes, how many jobs shall actually be rerun for the scene that the problem was triggered?
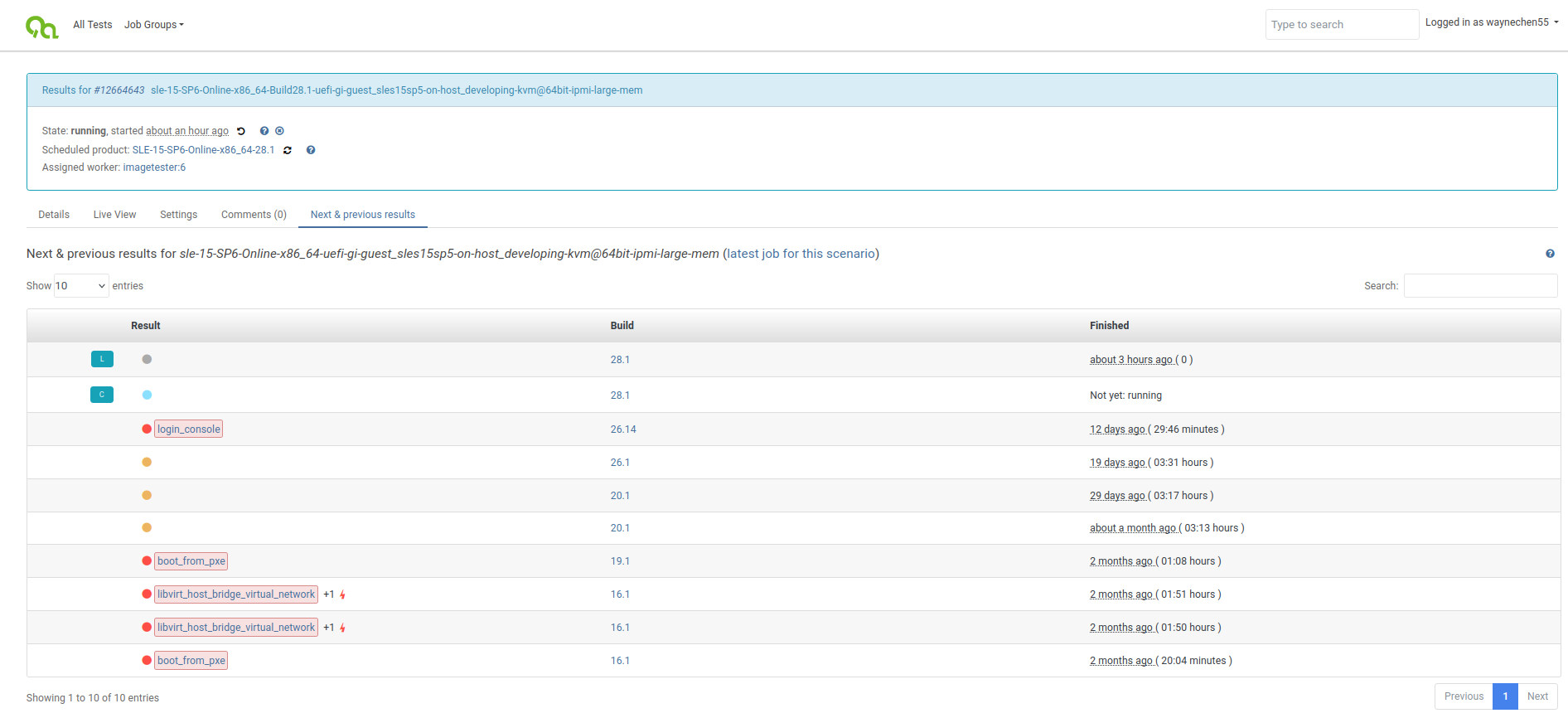
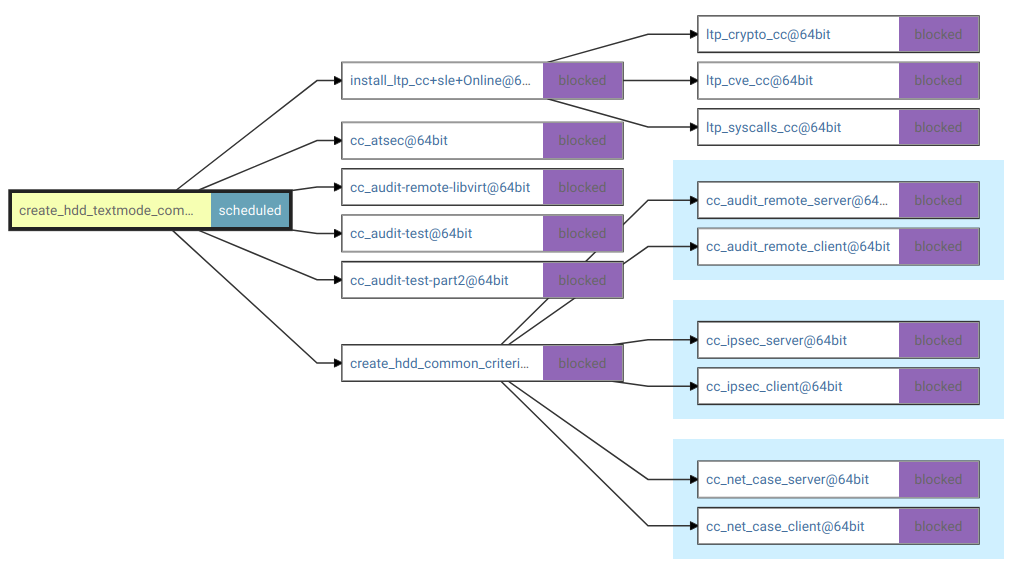
When I re-scheduled https://openqa.suse.de/tests/14611144#dependencies locally (after importing the OSD production database locally) only that exact job was re-scheduled. But in general it really depends on from where you do the re-scheduling (hence the button is on a concrete job details page) and what test suites are defined at this time. So for instance I also re-scheduled https://openqa.suse.de/tests/14610658#dependencies. This job has children which also have children and parallel dependencies so this entire sub-tree was re-scheduled (16 jobs, see attached screenshot).
Another side-note from the behavior I noticed when extending unit tests: The algorithm never goes up the dependency chain. So if e.g. job C is supposed to start after A and B (but there is no dependency between A and B; job C simply has multiple chained parents) and you re-trigger from A you get A and C but not B. (And if you re-trigger from B you get B and C but not A.)
I hope now that the actual behavior is in-line with the documentation the documentation also makes more sense.
Updated by mkittler 11 months ago
- Related to action #162608: Rescheduling product from the webUI adds invalid settings added
Updated by okurz 11 months ago
- Status changed from Feedback to Resolved
- Priority changed from Low to Normal
I don't think we should wait until SLE15SP7 builds are in a usable enough state to further verify this. We can assume that this works fine using the current verification and having automated tests. And as xlai stated she will be able to comment later at any time in case of unexpected issues still rising up.