action #119551
closedMove QA labs NUE-2.2.14-B to Frankencampus labs - bare-metal openQA workers size:M
Added by okurz about 2 years ago. Updated over 1 year ago.
0%
Description
Motivation¶
Rent at Maxtorhof will end. The new location at Nbg Frankencampus will have lab rooms in the same building where the office rooms are. We must prepare and execute the move of QA equipment from the old location, mostly NUE-2.2.13 QA cold storage and NUE-2.2.14 (TAM) to an according Frankencampus room
Acceptance criteria¶
- AC1: All bare-metal openQA workers from NUE-2.2.14 (TAM) are operational from the new location
- AC2: racktables is up-to-date
Acceptance tests¶
- AT1-1: Check that openQA jobs on the following list that they at least reach the openQA test modules "installation/welcome"
Suggestions¶
- Wait for initial setup in #119548
- Organize transport of hot equipment
- Setup hot equipment at new location
- Extend and adapt DHCP/DNS/PXE accordingly
- Ensure racktables is up-to-date
- Conduct AT1-1 at least once before and once after a weekend :)
Files
| SUSE_FC_Basement_different_length_L_shaped_brackets.jpg (379 KB) SUSE_FC_Basement_different_length_L_shaped_brackets.jpg | okurz, 2023-02-16 09:19 | ||
| osd-amd-zen3-pxe-boot.png (19.1 KB) osd-amd-zen3-pxe-boot.png | waynechen55, 2023-03-10 01:59 | ||
| boot_from_pxe_do_not_download.png (23.3 KB) boot_from_pxe_do_not_download.png | waynechen55, 2023-03-17 07:30 | ||
| boot_from_pxe_do_not_download_2.png (98.4 KB) boot_from_pxe_do_not_download_2.png | waynechen55, 2023-03-17 08:02 |
Updated by okurz almost 2 years ago
- Related to action #123028: A/C broken in TAM lab size:M added
Updated by okurz almost 2 years ago
- Status changed from Blocked to In Progress
There is the plan to disassemble all the equipment from NUE-2.2.14 and move to FC lab or SRV2 on Tuesday. That will be executed by mgriessmeier with help from nsinger and mmoese even though #119548 is not finished yet but the plan is expedited due to #123028
Updated by jstehlik almost 2 years ago
Good to know. That means we need to finish all tests until Tuesday 24.1. since then the machines will be offline for how long .. one or two days? That might impact Rado's plan to aim for Thursday release if there are critical bugs found. And the week after is hackweek. Feels like planning a walk through a mine field :)
Updated by okurz almost 2 years ago
jstehlik wrote:
Good to know. That means we need to finish all tests until Tuesday 24.1. since then the machines will be offline for how long .. one or two days?
We should keep in mind that the most critical machines are not affected as they are in server rooms and not in labs. Anyone critically relying on on systems within labs should consider using additionally or as replacement machines in other locations. However the "more important" machines should be moved to SRV2 already on Monday so in best case there is only an outage of some hours. The machines which are currently offline due to the A/C outage anyway will be moved to FC on Tuesday and available as soon as EngInfra could setup the network in FC labs. This might take days to weeks to be realistic.
Updated by openqa_review almost 2 years ago
- Due date set to 2023-02-04
Setting due date based on mean cycle time of SUSE QE Tools
Updated by okurz almost 2 years ago
The equipment and NUE-2.2.14-B was disassembled, also see #123028#note-14 . Some machines were put into NUE-SRV2, others pending move to FC, see list in https://racktables.nue.suse.com/index.php?page=rack&rack_id=19904. It is planned to install the servers on Wednesday and continue with setting up the network. Also I consider openqaworker1 as not critical and as done in the past with the move to NUE-2.2.14 we can experiment with connecting an o3 worker from the FC labs without sharing the VLAN as VLANs will not be shared across locations so we can try to come up with a proper routing approach. Keep in mind that some workstations are still in NUE-2.2.13
Updated by okurz almost 2 years ago
- Status changed from In Progress to Blocked
NUE-2.2.14 (TAM) was cleaned out and updated accordingly in racktables. All relevant equipment if not in NUE-SRV2 is now in FC Basement. Now back to #119548 waiting for DHCP+DNS.
Updated by livdywan almost 2 years ago
- Due date changed from 2023-02-04 to 2023-02-10
Bumping due date due to hackweek.
Updated by okurz almost 2 years ago
- Related to action #123933: [worker][ipmi][bmc] Some worker can not be reached via BMC added
Updated by xlai almost 2 years ago
okurz wrote:
The equipment and NUE-2.2.14-B was disassembled, also see #123028#note-14 . Some machines were put into NUE-SRV2, others pending move to FC, see list in https://racktables.nue.suse.com/index.php?page=rack&rack_id=19904.
NUE-2.2.14 (TAM) was cleaned out and updated accordingly in racktables. All relevant equipment if not in NUE-SRV2 is now in FC Basement. Now back to #119548 waiting for DHCP+DNS.
@okurz, Hi Oliver, does "FC" here means "Nbg Frankencampus" -- the new office building? What's the latest status for the machines in https://racktables.nue.suse.com/index.php?page=rack&rack_id=19904? Have they all been moved to Frankencampus lab? What's the ETA for the infra setup there being fully ready? Besides, what's the plan for those machines in NUE-SRV2(the lab in Maxtorhof)? Will they be moved to Frankencampus too? Any date/plan?
Let me also add more information to let you better know our situation for VT test as impact by this. We have totally ten ipmi x86 machines in NUE lab at Maxtorhof before this change. Based on the latest racktable records this morning, now the machines distribution is like below:
a) FC BASEMENT ->FC Inventory Storage : storage_qe2
amd-zen3-gpu-sut1.qa.suse.de
gonzo.qa.suse.de
scooter.qa.suse.de
kermit.qa.suse.de
b) NUE-SRV2-B:
openqaw5-xen.qa.suse.de
fozzie
quinn
amd-zen2-gpu-sut1.qa.suse.de
openqaipmi5.qa.suse.de
ix64ph1075.qa.suse.de
Here are the challenges we are facing atm by this new hardware location distribution and wip changes , in together with some needs from VT test:
- the 4 SUT machines in FC BASEMENT (nearly half of all total 9 x86 SUTs) are not usable now, given that infra setup at FC is not fully ready. And it will always be a major problem for 15sp5 test before infra setup there is done
- we have 2 pair of machines for key test of virutalization migration and are better to locate in one lab. Now fozzie is in NUE-SRV2-B, while 3 other machines(kermit, gonzo, scooter) in FC basement. If the network communication between the two labs(after FC setup is done in days or weeks as you expected) is not good enough, the key migration test will loose one pair of machines and impact 15sp5 acceptance test in a way that we can't finish test within 1 day. Is there any chance that the 4 machines can stay together in one stable lab?
- openqaw5-xen.qa.suse.de is one jump host used in vmware&hyperv VT test, it is better to stay in the same lab/network with the vmware&hyperv machines (eg hyperv2016(worker7-hyperv.oqa.suse.de) and vmware6.5(worker8-vmware.oqa.suse.de)). See lessons learned from https://progress.opensuse.org/issues/122662#note-18. Is it possible to put it into consideration in infra setup?
@jstehlik FYI. This lab move impact to virtualization test for sle15sp5 and tumbleweed is huge. The VT test speed and possibility for some tests will be impacted a lot before all infra setup is fully done/fixed in both FC new lab and Maxtorhof lab. Now we are debugging why all VT jobs on OSD fail at pxe boot. After this , we will then run the planned 15sp5 beta3 milestone test. Very likely that it will need much longer time because we loose many test machines by lab move in this ticket.
Updated by okurz almost 2 years ago
xlai wrote:
@okurz, Hi Oliver, does "FC" here means "Nbg Frankencampus" -- the new office building?
Yes
What's the latest status for the machines in https://racktables.nue.suse.com/index.php?page=rack&rack_id=19904? Have they all been moved to Frankencampus lab?
The status in racktables should be up-to-date. For all machines that have not been moved to NUE1-SRV2 they have been moved to "FC Basement" that is the new lab at Frankencampus location.
What's the ETA for the infra setup there being fully ready?
We are waiting for Eng-Infra to do the setup and they provide us neither ETA nor status updates. My expectation is some days up to in the worst case multiple weeks
Besides, what's the plan for those machines in NUE-SRV2(the lab in Maxtorhof)? Will they be moved to Frankencampus too? Any date/plan?
Maybe we will move some machines to the FC Lab if we are happy with the quality and stability there but most machines from NUE1 that is Maxtorhof, both SRV1&SRV2 will eventually go to a new datacenter location somewhere in the vicinity of Nuremberg, planned for this year
Let me also add more information to let you better know our situation for VT test as impact by this. We have totally ten ipmi x86 machines in NUE lab at Maxtorhof before this change. Based on the latest racktable records this morning, now the machines distribution is like below:
a) FC BASEMENT ->FC Inventory Storage : storage_qe2
amd-zen3-gpu-sut1.qa.suse.de
gonzo.qa.suse.de
scooter.qa.suse.de
kermit.qa.suse.deb) NUE-SRV2-B:
openqaw5-xen.qa.suse.de
fozzie
quinn
amd-zen2-gpu-sut1.qa.suse.de
openqaipmi5.qa.suse.de
ix64ph1075.qa.suse.deHere are the challenges we are facing atm by this new hardware location distribution and wip changes , in together with some needs from VT test:
- the 4 SUT machines in FC BASEMENT (nearly half of all total 9 x86 SUTs) are not usable now, given that infra setup at FC is not fully ready. And it will always be a major problem for 15sp5 test before infra setup there is done
- we have 2 pair of machines for key test of virutalization migration and are better to locate in one lab. Now fozzie is in NUE-SRV2-B, while 3 other machines(kermit, gonzo, scooter) in FC basement. If the network communication between the two labs(after FC setup is done in days or weeks as you expected) is not good enough, the key migration test will loose one pair of machines and impact 15sp5 acceptance test in a way that we can't finish test within 1 day. Is there any chance that the 4 machines can stay together in one stable lab?
- openqaw5-xen.qa.suse.de is one jump host used in vmware&hyperv VT test, it is better to stay in the same lab/network with the vmware&hyperv machines (eg hyperv2016(worker7-hyperv.oqa.suse.de) and vmware6.5(worker8-vmware.oqa.suse.de)). See lessons learned from https://progress.opensuse.org/issues/122662#note-18. Is it possible to put it into consideration in infra setup?
- amd-zen3-gpu-sut1.qa.suse.de needs to be used by O3, please help to consider this too
Right. Good that you bring this up. This is important to keep in mind. My intention is to provide a geo-redundany by spreading out services over locations where possible but also put critical machines together due to the strong requirements in network performance as you stated. Regarding jump hosts the best approach is likely to have likely even virtual machines but within the same server room as target hosts. Can you elaborate how
openqaw5-xen.qa.suse.de which is a xen hypervisor host is used as jump host?
Updated by xlai almost 2 years ago
okurz wrote:
xlai wrote:
Right. Good that you bring this up. This is important to keep in mind. My intention is to provide a geo-redundany by spreading out services over locations where possible but also put critical machines together due to the strong requirements in network performance as you stated. Regarding jump hosts the best approach is likely to have likely even virtual machines but within the same server room as target hosts. Can you elaborate how
openqaw5-xen.qa.suse.de which is a xen hypervisor host is used as jump host?
@okurz, Hi Oliver, thanks for the quick reply. That's very helpful.
- yes, we also highly recommend to put the 4 pair machines together. Now fozzie is in NUE-SRV2-B, while 3 other machines(kermit, gonzo, scooter) in FC basement.
- about openqaw5-xen.qa.suse.de, it serves as the xen hypervisor, then on top of it,multiple vms are created (one per worker), which are used in automation to either translate rdp to vnc(svirt-vmware/hyperv workers), or serving as test vm(svirt-xen workers)
Updated by xlai almost 2 years ago
Corrected one info in https://progress.opensuse.org/issues/119551#note-12 -- amd-zen3-gpu-sut1.qa.suse.de is used in OSD, rather than O3, and amd-zen2-gpu-sut1 is used in O3. Sorry for any confusion brought by it.
Updated by okurz almost 2 years ago
We progressed in the FC Basement lab. All machines and equipment has been sorted, racks and shelfs have been labeled and everything relevant is updated accordingly in racktables. The biggest hurdle is not enough suitable rack mounting rails. One machine was mounted using L-shapes and connected to power and switch in B1. Also the PDU in B1 is connected to switch and marked accordingly in racktables. The blocking ticket is still the current blocker.
Updated by okurz almost 2 years ago
- Tags changed from infra to infra, next-office-day, frankencampus
- Category set to Infrastructure
- Status changed from Blocked to In Progress
- Assignee changed from okurz to nicksinger
- Priority changed from Normal to Urgent
With #119548 resolved, see notes in #119548#note-21, we can progress here. Today nicksinger plans to go to FC Basement and mount and setup more machines. I will see if I can join to help.
Updated by okurz almost 2 years ago
nicksinger and me installed machines into NUE-FC-B1 QE LSG. Specifically those are the machines migration-qe1, power8.openqanet.opensuse.org, openqaworker1.openqanet.opensuse.org, holmes.qa.suse.de, gonzo.qa.suse.de, kermit.qa.suse.de, scooter.qa.suse.de, amd-zen3-gpu-sut1.qa.suse.de, openqaworker-arm-5.qa.suse.de, openqaworker-arm-4.qa.suse.de, openqa-migration-qe1.qa.suse.de . We had to adjust the spacing of the vertical holders in the rack as they had been assembled in a tilted way with two L-shaped brackets that are about 5mm longer than all other L-shaped brackets. We have disassembled those two L-shaped brackets and labeled them clearly as "too long" for our purposes. Then we put the above mentioned machines onto those L-shaped brackets as there are no rails fitting our machines. We connected all machines to power and network and documented everything accordingly in racktables. On the DHCP VM "qa-jump" as provided by Eng-Infra we could see that all mgmt interfaces show up and get an IPv4 address assigned by dhcpd. The next step is to assign static leases and adjust DNS entries on qanet accordingly.
I added all hosts to the dhcpd config:
# NUE-FC-B: Rack https://racktables.nue.suse.com/index.php?page=rack&rack_id=19174
host amd-zen3-gpu-sut1-sp { hardware ethernet ec:2a:72:0c:25:4c; fixed-address 10.168.192.83; option inventory-url "https://racktables.suse.de/index.php?page=object&object_id=16390"; option host-name "amd-zen3-gpu-sut1-sp"; }
host amd-zen3-gpu-sut1-1 { hardware ethernet ec:2a:72:02:84:20; fixed-address 10.168.192.84; option inventory-url "https://racktables.suse.de/index.php?page=object&object_id=16390"; option host-name "amd-zen3-gpu-sut1-1"; filename "pxelinux.0"; }
host amd-zen3-gpu-sut1-2 { hardware ethernet b4:96:91:9c:5a:d4; fixed-address 10.168.192.85; option inventory-url "https://racktables.suse.de/index.php?page=object&object_id=16390"; option host-name "amd-zen3-gpu-sut1-2"; filename "pxelinux.0"; }
host scooter-sp { hardware ethernet ac:1f:6b:4b:a7:d7; fixed-address 10.168.192.86; option inventory-url "https://racktables.suse.de/index.php?page=object&object_id=10124"; option host-name "scooter-sp"; }
host scooter-1 { hardware ethernet ac:1f:6b:47:73:38; fixed-address 10.168.192.87; option inventory-url "https://racktables.suse.de/index.php?page=object&object_id=10124"; option host-name "scooter-1"; filename "pxelinux.0"; }
host kermit-sp { hardware ethernet ac:1f:6b:4b:6c:af; fixed-address 10.168.192.88; option inventory-url "https://racktables.suse.de/index.php?page=object&object_id=10102"; option host-name "kermit-sp"; }
host kermit-1 { hardware ethernet ac:1f:6b:47:03:26; fixed-address 10.168.192.89; option inventory-url "https://racktables.suse.de/index.php?page=object&object_id=10102"; option host-name "kermit-1"; filename "pxelinux.1"; }
host gonzo-sp { hardware ethernet ac:1f:6b:4b:6b:03; fixed-address 10.168.192.90; option inventory-url "https://racktables.suse.de/index.php?page=object&object_id=10104"; option host-name "gonzo-sp"; }
host gonzo-1 { hardware ethernet ac:1f:6b:47:06:86; fixed-address 10.168.192.91; option inventory-url "https://racktables.suse.de/index.php?page=object&object_id=10104"; option host-name "gonzo-1"; filename "pxelinux.0"; }
host holmes-sp { hardware ethernet 58:8a:5a:f5:60:4a; fixed-address 10.168.192.92; option inventory-url "https://racktables.suse.de/index.php?page=object&object_id=10699"; option host-name "holmes-sp"; }
host holmes-1 { hardware ethernet 00:0a:f7:de:79:54; fixed-address 10.168.192.93; option inventory-url "https://racktables.suse.de/index.php?page=object&object_id=10699"; option host-name "holmes-1"; filename "pxelinux.0"; } # NVDIMM test host
host holmes-4 { hardware ethernet 00:0a:f7:de:79:53; fixed-address 10.168.192.94; option inventory-url "https://racktables.suse.de/index.php?page=object&object_id=10699"; option host-name "holmes-4"; filename "pxelinux.0"; } # NVDIMM test host
# openqaworker1 not included for now
# power8 not included for now
and updated openqa-migration-qe1. I restarted the DHCP server and the service started fine.
Updated by openqa_review almost 2 years ago
- Due date set to 2023-03-02
Setting due date based on mean cycle time of SUSE QE Tools
Updated by okurz almost 2 years ago
- File SUSE_FC_Basement_different_length_L_shaped_brackets.jpg SUSE_FC_Basement_different_length_L_shaped_brackets.jpg added
This was the biggest surprise of today:

The first rack was already mounted with L-shaped brackets on both sides. So we tried to mount more servers and found we couldn't fix the next brackets with screws due to the mismatch visible in the picture which is about 5mm difference for a 70cm long bracket. Turned out somebody managed to mount a 70cm bracket on the left side for which we have about 50 brackets and a 70,5mm version for which we have exactly two pieces. After realizing we dismounted those two and used only 70cm pieces consistently
Updated by okurz almost 2 years ago
https://gitlab.suse.de/qa-sle/qanet-configs/-/merge_requests/49 to update DHCP/DNS entries
EDIT: merged and deployed
qanet:~ # for i in scooter holmes gonzo kermit amd-zen3-gpu-sut1; do ping -c 1 $i-sp.qa.suse.de; done
PING scooter-sp.qa.suse.de (10.168.192.86) 56(84) bytes of data.
64 bytes from 10.168.192.86: icmp_seq=1 ttl=59 time=2.28 ms
--- scooter-sp.qa.suse.de ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 2.281/2.281/2.281/0.000 ms
PING holmes-sp.qa.suse.de (10.168.192.92) 56(84) bytes of data.
64 bytes from 10.168.192.92: icmp_seq=1 ttl=59 time=2.62 ms
--- holmes-sp.qa.suse.de ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 2.627/2.627/2.627/0.000 ms
PING gonzo-sp.qa.suse.de (10.168.192.90) 56(84) bytes of data.
64 bytes from 10.168.192.90: icmp_seq=1 ttl=59 time=2.63 ms
--- gonzo-sp.qa.suse.de ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 2.638/2.638/2.638/0.000 ms
PING kermit-sp.qa.suse.de (10.168.192.88) 56(84) bytes of data.
64 bytes from 10.168.192.88: icmp_seq=1 ttl=59 time=8.20 ms
--- kermit-sp.qa.suse.de ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 8.203/8.203/8.203/0.000 ms
PING amd-zen3-gpu-sut1-sp.qa.suse.de (10.168.192.83) 56(84) bytes of data.
64 bytes from 10.168.192.83: icmp_seq=1 ttl=59 time=2.59 ms
--- amd-zen3-gpu-sut1-sp.qa.suse.de ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 2.597/2.597/2.597/0.000 ms
https://gitlab.suse.de/openqa/salt-pillars-openqa/-/merge_requests/493 To be merged after verification in openQA
EDIT: Cloning a set of openQA jobs with
openqa-clone-set https://openqa.suse.de/tests/10493728 okurz_investigation_ipmi_workers_poo119551 WORKER_CLASS=64bit-ipmi_disabled BUILD=okurz_poo119551 _GROUP=0
results on https://openqa.suse.de/tests/overview?build=okurz_poo119551&distri=sle&version=15-SP5
- gonzo: https://openqa.suse.de/tests/10514912
- amd-zen3-gpu-sut1: https://openqa.suse.de/tests/10514913
- kermit: https://openqa.suse.de/tests/10514914
- scooter: https://openqa.suse.de/tests/10514915
and for holmes:
end=003 openqa-clone-set https://openqa.suse.de/tests/10493728 okurz_investigation_ipmi_workers_poo119551 WORKER_CLASS=64bit-ipmi-nvdimm_disabled BUILD=okurz_poo119551_holmes _GROUP=0 INCLUDE_MODULES=bootloader_start
Created job #10515077: sle-15-SP5-Online-x86_64-Build72.1-guided_btrfs@64bit-ipmi -> https://openqa.suse.de/t10515077
I guess the next step is to ensure that files are delivered over PXE
Updated by nicksinger almost 2 years ago
- Status changed from In Progress to Blocked
I tried several options to point to our existing TFTP-server on qanet but realized after resorting to tcpdump that the (tftp) packages never arrive at qanet. I created https://sd.suse.com/servicedesk/customer/portal/1/SD-112718 to address this problem.
Updated by okurz almost 2 years ago
ok, which tcpdump command did you use?
nicksinger wrote:
I tried several options to point to our existing TFTP-server on qanet but realized after resorting to tcpdump that the (tftp) packages never arrive at qanet. I created https://sd.suse.com/servicedesk/customer/portal/1/SD-112718 to address this problem.
I guess the alternative could be to provide a TFTP server from qa-jump which we will want in the future anyway. At best find someone from Eng-Infra to get the "get into salt and provide DHCP+DNS+PXE"-part done in one go. By the way as we learned it's "Georg" currently working on (re-)connecting qa-jump to Eng-Infra salt.
Updated by xlai almost 2 years ago
@nicksinger @okurz Hello guys, Jan just shared me that this ticket was done. But based on current ticket status , it is blocked. Would you please help clarify the real status? I saw that a lot had been done for this ticket, can I assume that there is only few TODO? Besides, what do you expect the machine owners to do to have the machines ready to serve as openqa SUT? We will prepare for that if needed.
Our situation is like this -- public beta is to be announced soon, if we can have the 4 affected machines back BEFORE THIS WEEKEND, we will wait for them and launch the tests next week via openqa. Otherwise, we will start manual test immediately after public beta is announced, for which the effort is not minor. Hope to have some forecast for the ticket , so that we can plan our next step for VT.
Thanks for your efforts. It means a lot for us!
Updated by nicksinger almost 2 years ago
xlai wrote:
@nicksinger @okurz Hello guys, Jan just shared me that this ticket was done. But based on current ticket status , it is blocked. Would you please help clarify the real status? I saw that a lot had been done for this ticket, can I assume that there is only few TODO? Besides, what do you expect the machine owners to do to have the machines ready to serve as openqa SUT? We will prepare for that if needed.
The main missing component is PXE here. We tried to setup a quick solution by just forwarding to our existing server but this unfortunately failed. We're in contact here with eng-infra to get this resolved but I simply cannot estimate when and if they will be able to resolve this problem.
Our situation is like this -- public beta is to be announced soon, if we can have the 4 affected machines back BEFORE THIS WEEKEND, we will wait for them and launch the tests next week via openqa. Otherwise, we will start manual test immediately after public beta is announced, for which the effort is not minor. Hope to have some forecast for the ticket , so that we can plan our next step for VT.
We do our best to get the setup up and running but cannot guarantee a working and stable environment at the moment as this is a fairly new setup. If these machines are so very important for public beta I'd say you should prepare the manual tests. If everything is working in openQA you could stop manual testing when openQA tests are showing results, no?
Thanks for your efforts. It means a lot for us!
@nicksinger, thanks for the reply. Appreciate your work to set up it. We will then plan our manual test in case it is needed.
Updated by okurz over 1 year ago
- Status changed from Blocked to Workable
Robert Wawrig commented in https://sd.suse.com/servicedesk/customer/portal/1/SD-112718 with a change and a request to test again. If that is not successful please followup with #119551#note-26
Updated by okurz over 1 year ago
With rrichardson changed NUE-FC-B:5 to match the shorter L-rails and put cloud4.qa, qanet2, seth+osiris there. Updated racktables to include the servers but couldn't yet finish the cabling.
Updated by nicksinger over 1 year ago
I've setup a tftp server on qa-jump with some basic config required for pxegen.sh. I and the script populated some files in /srv/tftpboot required for PXE booting. What is left is to test the setup by adding the custom tftp-server-url in https://gitlab.suse.de/OPS-Service/salt/-/blob/production/pillar/domain/qe_nue2_suse_org/hosts.yaml - Martin showed me that other domains do this already but I need to figure out what the correct syntax is for that
Updated by nicksinger over 1 year ago
- Status changed from Workable to Feedback
created https://gitlab.suse.de/OPS-Service/salt/-/merge_requests/3233 which needs to be merged before I can further test if my setup works
Updated by nicksinger over 1 year ago
- Status changed from Feedback to In Progress
Updated by okurz over 1 year ago
- Related to action #117043: Request DHCP+DNS services for new QE network zones, same as already provided for .qam.suse.de and .qa.suse.cz added
Updated by nicksinger over 1 year ago
I tried with gonzo but the request didn't make it to our own TFTP/PXE. Apparently "dhcp_next_server" just should be "next_server" but this unfortunately already fails in the tests: https://gitlab.suse.de/nicksinger/salt/-/jobs/1427672#L33 - I asked Martin in private message if he can give me a hint
Updated by okurz over 1 year ago
nicksinger wrote:
I tried with gonzo but the request didn't make it to our own TFTP/PXE. Apparently "dhcp_next_server" just should be "next_server" but this unfortunately already fails in the tests: https://gitlab.suse.de/nicksinger/salt/-/jobs/1427672#L33
I like that the error message is very specific. It's also pretty cool that you can test this in your own fork before even creating a merge request. I assume you didn't create a merge request yet, right?
I asked Martin in private message if he can give me a hint
why not in a public room? Did you make it personal? ;)
Updated by okurz over 1 year ago
- Copied to action #125204: Move QA labs NUE-2.2.14-B to Frankencampus labs - non-bare-metal machines size:M added
Updated by okurz over 1 year ago
- Subject changed from Move QA labs NUE-2.2.14-B to Frankencampus labs to Move QA labs NUE-2.2.14-B to Frankencampus labs - bare-metal openQA workers
- Due date changed from 2023-03-02 to 2023-03-10
I extracted a ticket #125204 for everything that goes beyond "just make bare-metal openQA tests using PXE work". @nicksinger will bring up the topic in #help-it-ama
Updated by nicksinger over 1 year ago
Created a SD ticket for a DNS entry for "qa-jump": https://sd.suse.com/servicedesk/customer/portal/1/SD-113814
Updated by okurz over 1 year ago
https://gitlab.suse.de/qa-sle/qanet-configs/-/merge_requests/53 created for our .qa.suse.de DNS entry.
EDIT: Merged
Updated by okurz over 1 year ago
gpfuetzenreuter was nice and helpful in https://suse.slack.com/archives/C029APBKLGK/p1677671947741049 but eventually he asked to create (another) ticket so we did with https://sd.suse.com/servicedesk/customer/portal/1/SD-113832
Motivation¶
https://gitlab.suse.de/OPS-Service/salt/-/blob/production/pillar/domain/qe_nue2_suse_org/init.sls#L54 defines a PXE server and we can see machines like gonzo-1.qe.nue2.suse.org seeing the PXE boot menu from icecream.nue2.suse.org on bootup. But openQA tests need either a custom PXE boot menu or a mountpoint serving current openQA builds for booting. We tried to fix this ourselves on the machine “qa-jump”, formerly, 10.168.192.1, but this machine was replaced with walter1 denying us access so we can not investigate and fix this ourselves anymore. We tried to provide host-specific PXE config like in https://gitlab.suse.de/OPS-Service/salt/-/merge_requests/3233/diffs but this was also not effective. Please help to make sure that we end up with a working solution, either where Eng-Infra provides the service or we do it on our own but we should half-baked solution without access.
Acceptance criteria¶
- AC1: Machines in the new domain qe.nue2.suse.org can execute bare-metal openQA tests
- AC2: QE employees can self-investigate issues with PXE booting
Suggestions¶
I think the best option is if experts from Eng-Infra like Georg Pfützenreuter and Martin Caj sit together in an online session with the SUSE QE Tools expert Nick Singer (of course others can join as well) to find the best solution, either on an Eng-Infra maintained VM where we have access to try out and debug on our own or (less preferred) a VM that we maintain or other solutions based on what you come up with.
Next to working with Eng-Infra to get a custom QE PXE working or our own PXE server different ideas to explore:
- Follow-up with https://gitlab.suse.de/OPS-Service/salt/-/merge_requests/3234 , e.g. test how DHCP with an HTTP url behaves with container+VM without needing any custom rule matching
- Find other tickets and add relations about "semi-automatic installation of openQA workers" because in the end we want the same for production hardware as well as bare-metal test hosts which is to have a common solution to deploy specific configurations of SLE/Leap/Tumbleweed, etc.
- Reconsider how we install bare-metal from network for tests and get in contact with test squads about that, e.g. just find the correct tickets
- An alternative that can be solved completely from os-autoinst-distri-opensuse perspective without needing any changes to infrastructure or backend would be to use the Eng-Infra supplied PXE boot menu and just boot an older version of the SLES installer (either older build or service pack) and conduct a remote installation of the current build from there. If that is not possible due to kernel mismatch between "linux" file and remote repo content then I suggest to boot an older version of SLES and update to the current build.
Updated by okurz over 1 year ago
- Assignee changed from nicksinger to okurz
Eng-Infra changed the PXE server advertise on the DHCP server with https://gitlab.suse.de/OPS-Service/salt/-/commit/050e95ece73f2fc79a7195a15a5cd1877d1b9241 to point to "qa-jump (new)". We will setup PXE on qa-jump (new) for now. Once the setup is done we can think if/how we can integrate this into Eng-Infra maintained salt salt.
as root on qa-jump.qe.nue2.suse.org
ssh-keygen -t ed25519
copied over the public key to qanet:/root/.ssh/authorized_keys
Then with nicksinger mount points in /etc/fstab:
dist.suse.de:/dist /mnt/dist nfs4 defaults 0 1
openqa.suse.de:/var/lib/openqa/share/factory /mnt/openqa nfs ro,defaults 0 0
/mounts /srv/tftpboot/mounts none defaults,bind 0 0
/mnt/openqa /srv/tftpboot/mnt/openqa none defaults,bind 0 0
and copied from qanet:/srv/tftp/pxegen.sh and execute that script within that folder and add what is necessary to to make the script happy.
Trying to mount NFS seems to be blocked by firewall. We commented in https://sd.suse.com/servicedesk/customer/portal/1/SD-113832 and also in https://suse.slack.com/archives/C029APBKLGK/p1677749667949229
Updated by okurz over 1 year ago
- Project changed from 46 to QA
- Category deleted (
Infrastructure)
Updated by okurz over 1 year ago
- Assignee changed from okurz to nicksinger
We provided what we could in https://sd.suse.com/servicedesk/customer/portal/1/SD-113832 and were asked to refrain from further communication in chat and rather use the ticket. That's obviously making it harder for others to follow hence we must provide a status here. nicksinger is trying out some things regarding loading from tftp due to the urgency of the ticket but we are running out of options and basically need to wait for Eng-Infra personell to help us with one of the many requests, e.g. either provide us more access like root access to walter1.qe.nue2.suse.org and switch access or fix the actual problems
Updated by okurz over 1 year ago
- Subject changed from Move QA labs NUE-2.2.14-B to Frankencampus labs - bare-metal openQA workers to Move QA labs NUE-2.2.14-B to Frankencampus labs - bare-metal openQA workers size:M
- Description updated (diff)
Updated by okurz over 1 year ago
I created https://gitlab.suse.de/openqa/salt-pillars-openqa/-/merge_requests/503 to add the specific target machines for easier openQA job triggering.
Updated by okurz over 1 year ago
- Copied to action #125519: version control PXE stuff on qa-jump added
Updated by okurz over 1 year ago
for i in kermit scooter gonzo amd-zen3-gpu-sut1; do openqa-clone-job --skip-chained-deps --within-instance https://openqa.suse.de/tests/10565133 TEST=okurz_investigation_ipmi_workers_poo119551_$i BUILD=okurz_investigation_ipmi_workers_poo119551 _GROUP=0 WORKER_CLASS=$i;done
Created job #10636248: sle-15-SP5-Online-x86_64-Build73.2-guided_btrfs@64bit-ipmi -> https://openqa.suse.de/t10636248
Created job #10636249: sle-15-SP5-Online-x86_64-Build73.2-guided_btrfs@64bit-ipmi -> https://openqa.suse.de/t10636249
Created job #10636250: sle-15-SP5-Online-x86_64-Build73.2-guided_btrfs@64bit-ipmi -> https://openqa.suse.de/t10636250
Created job #10636251: sle-15-SP5-Online-x86_64-Build73.2-guided_btrfs@64bit-ipmi -> https://openqa.suse.de/t10636251
Updated by nicksinger over 1 year ago
We had to change the SUT_NETDEVICE variable for two hosts (https://gitlab.suse.de/openqa/salt-pillars-openqa/-/compare/10134f09...master?from_project_id=746&straight=true) so the installer could find and access its files. Now we reach a common-ground on all machines where something (worker?) fails to connect to something else (yast in installer?) see https://openqa.suse.de/tests/overview?version=15-SP5&build=okurz_investigation_ipmi_workers_poo119551&distri=sle . A first quick nmap from my personal workstation showed the port of the SUT (inside FC LAB) as "open" so not sure if this is some firewall blocking traffic. As next step we should pause the test right after "setup_libyui" and maybe investigate manually if the connection is blocked from the worker. It might make also sense to involve the yast squad for additional information.
Updated by okurz over 1 year ago
Actually I have seen the same error in the production qemu tests so I would even go as far as saying that we reached the same level as other tests and we are good to enable the workers for production again, see my draft MR, and resolve
Updated by mgriessmeier over 1 year ago
okurz wrote:
Actually I have seen the same error in the production qemu tests so I would even go as far as saying that we reached the same level as other tests and we are good to enable the workers for production again, see my draft MR, and resolve
do you have a reference (ticket/job) for this? I couldn't find one - if we can link it to an open issue, I am fine with it - otherwise I'd really like to see a job that is either passing or not failing on a potential network issue - wdyt?
Updated by okurz over 1 year ago
- One example is https://openqa.suse.de/t10562907 on ppc64le showing "Connection timed out" in the YaST installer trying to access the self-update repo from 13 days ago in SLE 15 SP5 build 73.2. Apparently nobody cares to review those tests
- Please check on holmes, we have missed that yesterday in the for-loop
Updated by nicksinger over 1 year ago
https://gitlab.suse.de/openqa/salt-pillars-openqa/-/merge_requests/506 to enable kermit, scooter and zen3.
I manually tested holmes and the machine was able to display a PXE menu. While doing so I realized (and vaguely remembered) that this machine needs two interfaces connected (https://gitlab.suse.de/OPS-Service/salt/-/blob/production/pillar/domain/qe_nue2_suse_org/hosts.yaml#L125-132) which we didn't do so for the sake of moving forward I already enabled 3/4
Updated by okurz over 1 year ago
Updated by mkittler over 1 year ago
Looks like the corresponding reload unit couldn't be stopped cleanly triggering the systemd services alert:
martchus@worker2:~> sudo systemctl status openqa-reload-worker-auto-restart@54
× openqa-reload-worker-auto-restart@54.service - Restarts openqa-worker-auto-restart@54.service as soon as possible without interrupting jobs
Loaded: loaded (/usr/lib/systemd/system/openqa-reload-worker-auto-restart@.service; static)
Active: failed (Result: exit-code) since Wed 2023-03-08 20:29:17 CET; 16h ago
Main PID: 10271 (code=exited, status=1/FAILURE)
Mar 08 20:29:16 worker2 systemd[1]: Starting Restarts openqa-worker-auto-restart@54.service as soon as possible without interrupting jobs...
Mar 08 20:29:17 worker2 systemctl[10271]: Job for openqa-worker-auto-restart@54.service canceled.
Mar 08 20:29:17 worker2 systemd[1]: openqa-reload-worker-auto-restart@54.service: Main process exited, code=exited, status=1/FAILURE
Mar 08 20:29:17 worker2 systemd[1]: openqa-reload-worker-auto-restart@54.service: Failed with result 'exit-code'.
Mar 08 20:29:17 worker2 systemd[1]: Failed to start Restarts openqa-worker-auto-restart@54.service as soon as possible without interrupting jobs.
martchus@worker2:~> sudo systemctl status openqa-worker-auto-restart@54
○ openqa-worker-auto-restart@54.service - openQA Worker #54
Loaded: loaded (/usr/lib/systemd/system/openqa-worker-auto-restart@.service; disabled; vendor preset: disabled)
Drop-In: /etc/systemd/system/openqa-worker-auto-restart@.service.d
└─20-nvme-autoformat.conf, 30-openqa-max-inactive-caching-downloads.conf
Active: inactive (dead) since Wed 2023-03-08 20:29:18 CET; 16h ago
Main PID: 30231 (code=exited, status=0/SUCCESS)
Mar 08 12:23:29 worker2 worker[30231]: [info] [pid:30231] Registering with openQA openqa.suse.de
Mar 08 12:23:29 worker2 worker[30231]: [info] [pid:30231] Establishing ws connection via ws://openqa.suse.de/api/v1/ws/2131
Mar 08 12:23:29 worker2 worker[30231]: [info] [pid:30231] Registered and connected via websockets with openQA host openqa.suse.de and worker ID 2131
Mar 08 17:15:22 worker2 worker[30231]: [warn] [pid:30231] Worker cache not available via http://127.0.0.1:9530: Cache service queue already full (10) - checking again for web UI 'openqa.suse.de' in 100.00 s
Mar 08 17:17:02 worker2 worker[30231]: [warn] [pid:30231] Worker cache not available via http://127.0.0.1:9530: Cache service queue already full (10) - checking again for web UI 'openqa.suse.de' in 100.00 s
Mar 08 20:29:18 worker2 worker[30231]: [info] [pid:30231] Received signal TERM
Mar 08 20:29:18 worker2 worker[30231]: [debug] [pid:30231] Informing openqa.suse.de that we are going offline
Mar 08 20:29:18 worker2 systemd[1]: Stopping openQA Worker #54...
Mar 08 20:29:18 worker2 systemd[1]: openqa-worker-auto-restart@54.service: Deactivated successfully.
Mar 08 20:29:18 worker2 systemd[1]: Stopped openQA Worker #54.
I've just reset the unit. Not sure whether this is a general problem we have when reducing the number of worker slots. (It seems more exceptional to me.)
Updated by Julie_CAO over 1 year ago
Some workers failed to get PXE menu due to tftp error, such as grenache-1:12 & grenache-1:15
Updated by waynechen55 over 1 year ago
Julie_CAO wrote:
Some workers failed to get PXE menu due to tftp error, such as grenache-1:12 & grenache-1:15
Also grenache-1:19
https://openqa.suse.de/tests/10652807#step/boot_from_pxe/22

Updated by xlai over 1 year ago
@okurz @nicksinger Hello guys, virt team checks all the 4 newly enabled workers in FC lab, namely
amd-zen3-gpu-sut1.qa.suse.de
gonzo.qa.suse.de
scooter.qa.suse.de
kermit.qa.suse.de
Based on all historical jobs triggered yesterday, no successful job and all fail at boot_from_pxe. Just as Julie and Wayne shared, likely root cause is on the tftp server used by pxe. This may need your further help.
In addition, for the other newly enabled machine, holmes, there is no job triggered there, so no reference at all.
@jstehlik FYI.
Updated by openqa_review over 1 year ago
Setting due date based on mean cycle time of SUSE QE Tools
Updated by okurz over 1 year ago
- Related to action #125735: [openQA][infra][pxe] Some machines can not boot from pxe due to "TFTP open timeout" added
Updated by okurz over 1 year ago
- Priority changed from Normal to Urgent
- % Done changed from 100 to 0
back to urgent after changing #125735 to not be a subtask
Updated by okurz over 1 year ago
I looked into this shortly with mgriessmeier and it looks like the systemd unit tftp.socket wasn't activated on qa-jump so I called systemctl enable --now tftp.socket and also for a persistent journal mkdir -p /var/log/journal. Then soon after journalctl -f showed tftpd processes showing up and serving requests. I opened some openQA jobs on the according worker instances and monitoring them.
Jobs like the following look promising:
- https://openqa.suse.de/tests/10653273 grenache:12 kermit
- https://openqa.suse.de/tests/10653281 grenache:13 gonzo
- https://openqa.suse.de/tests/10653225 grenache:14 fozzie
- https://openqa.suse.de/tests/10653276 grenache:15 scooter
https://openqa.suse.de/tests/10652010 grenache:19 amd-zen3-gpu-sut1
TODO @nicksinger please find, label and retrigger all according affected tests
Updated by Julie_CAO over 1 year ago
Thank you for the quick fix, Oliver. We will retrigger tests on our own.
Updated by nicksinger over 1 year ago
- Assignee changed from nicksinger to okurz
@okurz please check that both ofthese interfaces are connected to holmes when you visit the office next Monday.
You can assign back so I can check if the rest of the setup works with this machine.
Updated by openqa_review over 1 year ago
- Due date set to 2023-03-25
Setting due date based on mean cycle time of SUSE QE Tools
Updated by waynechen55 over 1 year ago
- Related to action #125810: [openqa][infra] Some SUT machines can not upload logs to worker machine size:S added
Updated by nicksinger over 1 year ago
@okurz connected the fourth interface of holmes. We where able to open a PXE menu and start into a leap15.4 installer. Triggered verification openQA job with:
openqa-clone-job --skip-chained-deps --within-instance https://openqa.suse.de/tests/10493728 TEST=okurz_investigation_ipmi_workers_poo119551_holmes BUILD=okurz_investigation_ipmi_workers_poo119551 _GROUP=0 WORKER_CLASS=holmes --apikey XXX --apisecret XXX
Created job #10679705: sle-15-SP5-Online-x86_64-Build72.1-guided_btrfs@64bit-ipmi -> https://openqa.suse.de/t10679705
Updated by okurz over 1 year ago
- Tags changed from infra, next-office-day, frankencampus to infra, frankencampus
- Status changed from In Progress to Blocked
- Assignee changed from okurz to nicksinger
Updated by okurz over 1 year ago
- Status changed from Blocked to In Progress
Firewall was unblocked, SD ticket closed.
Updated by okurz over 1 year ago
Please clone the latest ok jobs which were running on that specific worker instance https://openqa.suse.de/admin/workers/1264 and check if they work on holmes. It might be that the other generic scenarios can not run on holmes for whatever reason we do not need to care about.
Updated by okurz over 1 year ago
holmes seems to be the only worker reserved for "64bit-ipmi-nvdimm" and apparently no jobs were scheduled within the past two months that would match here. I looked around for longer but the best I could find is those 2 month old jobs so I cloned one of those overwriting the INCIDENT_REPO as otherwise we would get a warning because the incident repo is long gone. Anyway, it should at least show us how far the initial booting can go.
openqa-clone-job --within-instance https://openqa.suse.de/tests/10297800 _GROUP=0 BUILD= TEST+=-okurz-poo119551 WORKER_CLASS=holmes INCIDENT_REPO=
Created job #10706998: sle-15-SP3-Server-DVD-SAP-Incidents-x86_64-Build:27344:php7-qam-sles4sap_online_dvd_gnome_hana_nvdimm@64bit-ipmi-nvdimm -> https://openqa.suse.de/t10706998
EDIT: this showed "Unable to locate configuration file" so same as what we have already sen
@nicksinger I suggest we follow the logs from tftpd and restart job boot attempts to follow what happens exactly.
Updated by nicksinger over 1 year ago
Cross-referencing #125810 here as we saw issues with the PXE config generation script which got fixed with https://gitlab.suse.de/qa-sle/qa-jump-configs/-/merge_requests/3
Updated by okurz over 1 year ago
- Description updated (diff)
For now for investigation I masked a worker service so that we can check:
systemctl mask --now openqa-worker-auto-restart@13
https://openqa.suse.de/tests/10707348#step/reboot_and_wait_up_normal/14 shows that we login over ssh but name resolution in the curl command fails. We checked manually in a SoL session to gonzo-1, machine is still up from https://openqa.suse.de/tests/10707348 and dig grenache-1.qa.suse.de works fine. We assume that as soon as the openQA test logged in over ssh to gonzo-1 network was simply not fully up yet. The test is making wrong assumptions. This is something which should be changed within os-autoinst-distri-opensuse. @nicksinger I suggest you create a specific ticket for that. What we can also do is check the system journal on gonzo-1 and compare network related log messages to what the autoinst-log.txt from https://openqa.suse.de/tests/10707348 says to check when openQA logged in and when the network was actually reported to be up in journalctl.
Updated by waynechen55 over 1 year ago
One more thing is ipmi sol connection can not be established to grenache-1:16/ix64ph1075:
[2023-03-16T13:10:45.311924+01:00] [info] [pid:491202] ::: backend::baseclass::die_handler: Backend process died, backend errors are reported below in the following lines:
ipmitool -I lanplus -H xxx -U xxx -P [masked] mc guid: Error: Unable to establish IPMI v2 / RMCP+ session at /usr/lib/os-autoinst/backend/ipmi.pm line 45.
All test run assigned to this worker failed due to the same reason as above, for example, https://openqa.suse.de/tests/10707853.
Updated by xguo over 1 year ago
waynechen55 wrote:
One more thing is ipmi sol connection can not be established to grenache-1:16/ix64ph1075:
[2023-03-16T13:10:45.311924+01:00] [info] [pid:491202] ::: backend::baseclass::die_handler: Backend process died, backend errors are reported below in the following lines:
ipmitool -I lanplus -H xxx -U xxx -P [masked] mc guid: Error: Unable to establish IPMI v2 / RMCP+ session at /usr/lib/os-autoinst/backend/ipmi.pm line 45.All test run assigned to this worker failed due to the same reason as above, for example, https://openqa.suse.de/tests/10707853.
Quick update, Assigned worker: grenache-1:16 still have boot_from_pxe test failure on our OSD with the latest 15-SP5 build80.5.
Please refer to the following osd test url for getting more details:
https://openqa.suse.de/tests/10709006#step/boot_from_pxe/22
https://openqa.suse.de/tests/10709149#step/boot_from_pxe/9
Meanwhile, or refer to https://openqa.suse.de/admin/workers/1247
Updated by xlai over 1 year ago
Thanks for the effort on this, guys.
I observe that after yesterday's final change, for the 3 machines, namely amd-zen3-gpu-sut1, gonzo, scooter, the boot_from_pxe succeed at acceptable ratio.
But on kermit, the success ratio is not high enough, see https://openqa.suse.de/admin/workers/1243. Recent 3 jobs all failed at https://openqa.suse.de/tests/10707383#step/boot_from_pxe/7, while the earlier 3 passed. Would you please have a look?
Updated by cachen over 1 year ago
xlai wrote:
Thanks for the effort on this, guys.
I observe that after yesterday's final change, for the 3 machines, namely amd-zen3-gpu-sut1, gonzo, scooter, the boot_from_pxe succeed at acceptable ratio.
But on kermit, the success ratio is not high enough, see https://openqa.suse.de/admin/workers/1243. Recent 3 jobs all failed at https://openqa.suse.de/tests/10707383#step/boot_from_pxe/7, while the earlier 3 passed. Would you please have a look?
Many test failed in 'could not find kernel image', I checked all the type string is correct, assuming it's still caused by the unstable or problem network connect from kermit to pxe/tftp server?
Updated by okurz over 1 year ago
Please try to separate concerns and provide more details in your messages.
It's important to distinguish errors that happen in all cases, like 100% error rate and sporadic timeouts and such as you noted about.
Also referencing openQA jobs is good but even better is to explain what jobs those are, where they ran, what problem they show and what you expect instead. Can be all in a simple sentence, does not have to be fancy.
Updated by waynechen55 over 1 year ago
okurz wrote:
Please try to separate concerns and provide more details in your messages.
It's important to distinguish errors that happen in all cases, like 100% error rate and sporadic timeouts and such as you noted about.
Also referencing openQA jobs is good but even better is to explain what jobs those are, where they ran, what problem they show and what you expect instead. Can be all in a simple sentence, does not have to be fancy.
Now the most obvious problem is these four machines:
grenache-1:12/kermit
grenache-1:13/gonzo
grenache-1:15/scooter
grenache-1:19/amd-zen3
can not do host installation from pxe/tftp.
Steps to reproduce:
- Establish ipmi sol session to one of the above machines
- Press 'esc' at pxe menu
- "boot:" prompts
- Enter the following to install 15-SP5 Build80.5: /mnt/openqa/repo/SLE-15-SP5-Online-x86_64-Build80.5-Media1/boot/x86_64/loader/linux initrd=/mnt/openqa/repo/SLE-15-SP5-Online-x86_64-Build80.5-Media1/boot/x86_64/loader/initrd install=http://openqa.suse.de/assets/repo/SLE-15-SP5-Online-x86_64-Build80.5-Media1?device=eth0 ifcfg=eth0=dhcp4 plymouth.enable=0 /mnt/openqa/repo/SLE-15-SP5-Online-x86_64-Build80.5-Media1/boot/x86_64/loader/linux initrd=/mnt/openqa/repo/SLE-15-SP5-Online-x86_64-Build80.5-Media1/boot/x86_64/loader/initrd install=http://openqa.suse.de/assets/repo/SLE-15-SP5-Online-x86_64-Build80.5-Media1?device=eth0 ifcfg=eth0=dhcp4 plymouth.enable=0 ssh=1 sshpassword=xxxxxx regurl=http://all-80.5.proxy.scc.suse.de kernel.softlockup_panic=1 vt.color=0x07
- Press "enter" to start loading linux/initrd
But unfortunately, linux/initrd downloading never started. The machine hangs there. Please refer to the following screenshot:
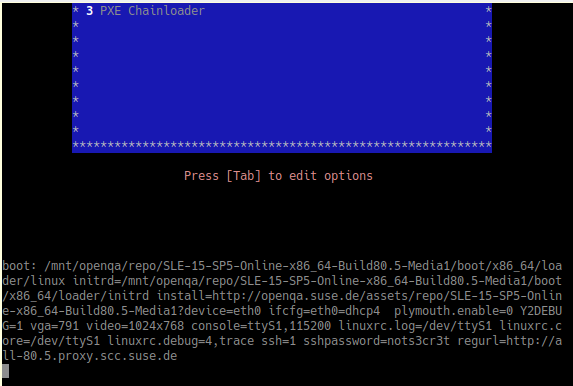
Please also refer to openQA jobs:
kermit https://openqa.suse.de/tests/10707383#step/boot_from_pxe/7
scooter https://openqa.suse.de/tests/10713350#step/boot_from_pxe/7
amd-zen3 https://openqa.suse.de/tests/10713345#step/boot_from_pxe/7
I also reproduced this issue manually with gonzo. Looks like it has 100% reproducibility.
Updated by waynechen55 over 1 year ago
One more screenshot from video record of job 10707383 in #119551#note-81. It reported explicitly that it can not find image:
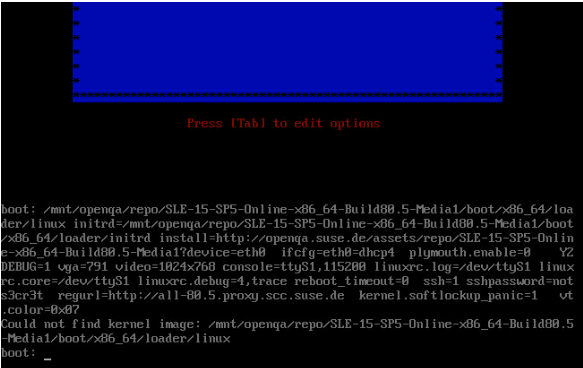
So I think my manual reproduce with gonzo should has the same issue.
Updated by nicksinger over 1 year ago
I can confirm that the NFS share on the tftp-server pointing to openqa.suse.de hangs. Most likely a unstable connection. Will check how we can recovery and how we can rectify the problem long term
Updated by nicksinger over 1 year ago
dmesg shows that the machine failed to reach OSD starting yesterday, 20:34 CET:
[Mar16 20:34] nfs: server openqa.suse.de not responding, still trying
[ +0.001777] nfs: server openqa.suse.de not responding, still trying
[Mar16 21:16] nfs: server openqa.suse.de not responding, still trying
[ +0.155986] nfs: server openqa.suse.de not responding, still trying
[Mar16 21:17] nfs: server openqa.suse.de not responding, still trying
[ +0.001621] nfs: server openqa.suse.de not responding, still trying
[Mar16 21:19] nfs: server openqa.suse.de not responding, still trying
[ +0.001601] nfs: server openqa.suse.de not responding, still trying
[Mar16 21:22] nfs: server openqa.suse.de not responding, still trying
[ +0.001568] nfs: server openqa.suse.de not responding, still trying
[Mar16 21:24] nfs: server openqa.suse.de not responding, still trying
[ +0.001573] nfs: server openqa.suse.de not responding, still trying
the retries lasted till now despite osd being reachable over ping as well as showing the NFS port(s) in nmap. umount -l followed by mount -a hangs again so I might have a reproducer right now
Updated by nicksinger over 1 year ago
nfs-server logs on OSD show no noteworthy entries. Listing mounts from qa-jump works:
qa-jump:~ # showmount --exports openqa.suse.de
Export list for openqa.suse.de:
/var/lib/openqa/share *
Updated by nicksinger over 1 year ago
https://www.suse.com/support/kb/doc/?id=000019722 mentions: "The unique scenario described above happens because many firewalls and smart routers will detect and block TCP connection reuse, even though connection reuse is a valid practice and NFS has traditionally relied upon it." - this sounds like a realistic assumption. We also see the described phenomenon on qa-jump:
qa-jump:~ # ss -nt | grep :2049
ESTAB 0 0 10.168.192.10:783 10.137.50.100:2049
SYN-SENT 0 1 10.168.192.10:765 10.160.0.207:2049
Checking mount -v I can see that apparently we fallback to NFSv3:
qa-jump:~ # /sbin/mount.nfs4 -v openqa.suse.de:/var/lib/openqa/share/factory /mnt/openqa -o ro
mount.nfs4: timeout set for Fri Mar 17 09:04:19 2023
mount.nfs4: trying text-based options 'vers=4.2,addr=10.160.0.207,clientaddr=10.168.192.10'
mount.nfs4: mount(2): No such file or directory
mount.nfs4: trying text-based options 'addr=10.160.0.207'
mount.nfs4: prog 100003, trying vers=3, prot=6
mount.nfs4: trying 10.160.0.207 prog 100003 vers 3 prot TCP port 2049
mount.nfs4: prog 100005, trying vers=3, prot=17
mount.nfs4: trying 10.160.0.207 prog 100005 vers 3 prot UDP port 20048
Terminated
Dist was mounted with v4 and survived for a longer time. I think a valid workaround could be to mount OSD with the following command:
/sbin/mount.nfs4 -v openqa.suse.de:/ /mnt/openqa -o ro,nfsvers=4,minorversion=2
I just did this manually but need to find out how to persist it. Afterwards a ticket needs to be opened to inform eng-infra about this shortcoming and ask, if they are aware. Next we have to check if it actually helps with our problem in the long-run.
Updated by okurz over 1 year ago
Discussed in SUSE QE Tools weekly meeting 2023-03-17: The NFS mount on qa-jump was fixed. nicksinger retriggered openQA jobs and will monitor those. If no further problems are found then
Please handle in separate tickets any sporadic issues or any potential firewall related issues for anything later than the openQA test modules "installation/welcome".
Updated by okurz over 1 year ago
xguo wrote:
[…]
Quick update, Assigned worker: grenache-1:16 still have boot_from_pxe test failure on our OSD with the latest 15-SP5 build80.5.
Please be aware that grenache-1:16 is ix64ph1075 which is NUE1-SRV2 so not affected by move to FC Basement. Also the problem happened during the Eng-Infra maintenance window. We can't rule out that as an effect which is unfortunate but means if you can reproduce that problem then please bring it up in a separate progress ticket and an according linked Eng-Infra ticket as well.
Updated by nicksinger over 1 year ago
I changed the mountpoint to the following in /etc/fstab:
openqa.suse.de:/factory /mnt/openqa nfs4 ro,defaults 0 0 # this mounts /var/lib/openqa/share/factory from OSD
Updated by okurz over 1 year ago
- Description updated (diff)
Unmasked and started grenache-1 openqa-worker-auto-restart@13 aka. gonzo again.
Created https://gitlab.suse.de/openqa/salt-pillars-openqa/-/merge_requests/513 to include qa-jump and others in our availability check monitoring.
After the latest change in NFS mount jobs look good again:
- grenache-1:10 openqaipmi5 https://openqa.suse.de/tests/10716021
- grenache-1:12 kermit https://openqa.suse.de/tests/10716022
- grenache-1:13 gonzo (no jobs currently)
- grenache-1:14 fozzie https://openqa.suse.de/tests/10715932
- grenache-1:15 scooter
- grenache-1:19 amd-zen3-gpu-sut1 https://openqa.suse.de/tests/10713369
Updated by nicksinger over 1 year ago
- Status changed from In Progress to Resolved
I checked all mentioned machines and all runs over the weekend passed the PXE menu and look working. I think with that we can consider this task done