action #152389
closedcoordination #112862: [saga][epic] Future ideas for easy multi-machine handling: MM-tests as first-class citizens
coordination #111929: [epic] Stable multi-machine tests covering multiple physical workers
significant increase in MM-test failure ratio 2023-12-11: test fails in multipath_iscsi and other multi-machine scenarios due to MTU size auto_review:"ping with packet size 1350 failed, problems with MTU" size:M
Description
Observation¶
openQA test in scenario sle-15-SP5-Server-DVD-Updates-x86_64-qam_kernel_multipath@64bit fails in
multipath_iscsi
Test suite description¶
Testsuite maintained at https://gitlab.suse.de/qa-maintenance/qam-openqa-yml. Maintainer: jpupava on 15sp1 is problem missing python-xml package
Reproducible¶
Fails since (at least) Build 20231210-1 (current job)
Expected result¶
Last good: 20231208-1 (or more recent)
Acceptance criteria¶
- AC1: failed+parallel_failed on https://monitor.qa.suse.de/d/nRDab3Jiz/openqa-jobs-test?orgId=1&viewPanel=24 is significantly below 20% again
- AC2: same as AC1 but also after the next weekend and worker host reboots
- AC3: Steps are planned to ensure we do not run into similar problems again, e.g. follow-up tickets regarding enablement of cross-location TAP worker connections
Problem¶
Pinging (as of certain sizes via -s parameter) and certain traffic (e.g. SSH) hangs when using via GRE tunnels (the MM test setup).
H1 -> E1-1 take a look into openQA investigate results -> O1-1-1 openqa-investigate in job $url proves no changes in product
Problem¶
-
H1 REJECTED The product has changed -> unlikely because it happened accross all products at the same time
-
H2 Fails because of changes in test setup
-
H2.1 REJECTED Recent changes of the MTU size on the bridge on worker hosts made a difference
-> E2.1-1 Revert changes from https://gitlab.suse.de/openqa/salt-states-openqa/-/merge_requests/1061 manually -> O2.1-1-1 reverting manually on two worker hosts didn't make any difference
-> E2.1-2 Explicitly set back MTU to default value with ovs-vsctl -> #152389#note-26 -
H2.2 ACCEPTED The network behaves differently -> considering the testing with tracepath in #152557 the network definitely behaves in an unexpected way when it comes to routing and it most likely was not always like that
- H2.2.1 Issue #152557 means that there might now be additional hops that lower the physical MTU size leading to the problem we see -> E2.2.1-1 wait until the SD ticket has been resolved and see if it works after that as before -> The routing is to be expected as between PRG1/NUE2 and PRG2 there is an ipsec tunnel involved which most likely impacts the effective MTU limit in the observed ways, E2.2.1-2 check whether lowering the MTU would help (as that might indicate that the physical MTU size is indeed reduced) -> lowering the MTU size within the VM helps indeed, see #152389#note-25
-
H2.3 The automatic reboot of machines in our Sunday maintenance window had an impact
-> E2.3-1 First check if workers actually rebooted -> O2.3-1-1sudo salt -C 'G@roles:worker' cmd.run 'w'shows that all workers rebooted on last Sunday so there was a reboot
-> E2.3-2 Implement #152095 for better investigation -
H2.4 REJECTED Scenarios failing now were actually never tested as part of https://progress.opensuse.org/issues/151310 -> the scenario https://openqa.suse.de/tests/13018864 was passing at the time when #151310 was resolved and queries for failing MM jobs done in #151310 didn't the many failures we see now
-
H2.5 ACCEPTED There is something wrong in the combination of GRE tunnels with more than 2 physical hosts (#152389-10) -> E2.5-1 Run a multi-machine cluster between two non-production hosts with only GRE tunnels between those two enabled -> with just 2 physical hosts the problem is indeed no longer reproducible, see #152389#note-29
-
H2.5.1 ACCEPTED Only a specific worker host (or the way it is connected) is problematic -> E2.5.1 Add further hosts step by step -> it seems that adding
qesapworker-prg4.qa.suse.czto the cluster causes the problem (but not similar workers likeqesapworker-prg5.qa.suse.cz), see #152389#note-32 and #152389#note-35
-
H2.5.1 ACCEPTED Only a specific worker host (or the way it is connected) is problematic -> E2.5.1 Add further hosts step by step -> it seems that adding
-
H3 REJECTED Fails because of changes in test infrastructure software, e.g. os-autoinst, openQA
-> O3-1-1 Comparing "first bad" https://openqa.suse.de/tests/13018864/logfile?filename=autoinst-log.txt os-autoinst version 4.6.1702036503.3b9f3a2 and "last good" 4.6.1701963272.58c0dd5 yielding
$ git log1 --no-merges 58c0dd5..3b9f3a2
fdf5f064 Improve `sudo`-usage in `t/20-openqa-isotovideo-utils.t`
2f9d913a Consider code as generally uncoverable when testing relies on `sudo`
also no relevant changes in openQA at all
- H4 REJECTED Fails because of changes in test management configuration, e.g. openQA database settings -> O4-1-1 no relevant changes, see https://openqa.suse.de/tests/13018864#investigation
- H5 REJECTED Fails because of changes in the test software itself (the test plan in source code as well as needles) -> no changes, see e.g. https://openqa.suse.de/tests/13018864#investigation
- H6 REJECTED Sporadic issue, i.e. the root problem is already hidden in the system for a long time but does not show symptoms every time -> O6-1-1 https://monitor.qa.suse.de/d/nRDab3Jiz/openqa-jobs-test?orgId=1&viewPanel=24&from=1701825350155&to=1702376526900 shows a clear regression by statistic
Suggestions¶
Debug in VMs (using the developer mode or by creating VMs manually) as we have already started in #152389#note-10 an subsequent comments.
The mentioned scenario is an easy reproducer but not the only affected scenario. Use e.g.
select distinct count(jobs.id), array_agg(jobs.id), (select name from job_groups where id = group_id), (array_agg(test))[1] as example_test from jobs left join job_dependencies on (id = child_job_id or id = parent_job_id) where dependency = 2 and t_finished >= '2023-12-05T18:00' and result in ('failed', 'incomplete') and test not like '%:investigate:%' group by group_id order by count(jobs.id) desc;
to find possibly also affected and relevant scenarios.
- Lower the MTU, but keep in mind minimums for IPv6? according to dheidler referencing wikipedia minimum would be 1280 bytes
- Use more hosts in different locations and see if those work more reliably in production
- Ensure tap is not used by machines that don't work since that would still affect the gre setup
- Make the use of MTU in os-autoinst-distri-opensuse configurable, i.e. the value that the support_server sets as well as the ping_size_check
- DONE Use the minimum MTU in both os-autoinst-distri-opensuse as well as https://gitlab.suse.de/openqa/salt-states-openqa/-/blob/master/openqa/openvswitch.sls to be "on the safe side" for across-location tunneled GRE configurations -> https://github.com/os-autoinst/os-autoinst-distri-opensuse/pull/18351 (merged)
- DONE Only enable "tap" in our workerconf.sls within one location per one architecture, e.g. only ppc64le tap in NUE2, only x86_64 tap in PRG2 -> https://gitlab.suse.de/openqa/salt-pillars-openqa/-/merge_requests/701 (merged) and https://gitlab.suse.de/openqa/salt-pillars-openqa/-/merge_requests/702 (merged)
- Change https://gitlab.suse.de/openqa/salt-states-openqa/-/blob/master/openqa/openvswitch.sls to only enable GRE tunnels on machines within the same datacenter, e.g. "location-prg" and rename accordingly in https://gitlab.suse.de/openqa/salt-pillars-openqa/-/blob/master/openqa/workerconf.sls
- Follow #152737 regarding scheduling limited to individual zone
Rollback steps¶
- Revert https://gitlab.suse.de/openqa/salt-pillars-openqa/-/merge_requests/693 disabling all tap classes except one x86_64 worker hosts
- Revert https://gitlab.suse.de/openqa/salt-pillars-openqa/-/commit/4be80b2c720f6023b20355c9f4ac71096dc0aee4
- Remove silence from https://monitor.qa.suse.de/alerting/silences "alertname=Ratio of multi-machine tests by result alert"
Further details¶
Always latest result in this scenario: latest
Files
Updated by okurz over 1 year ago
- Related to action #138698: significant increase in multi-machine test failures on OSD since 2023-10-25, e.g. test fails in support_server/setup size:M added
Updated by okurz over 1 year ago
- Subject changed from significant increase in MM-test failure ratio 2023-12-11: test fails in multipath_iscsi and other multi-machine scenarios due to MTU size to significant increase in MM-test failure ratio 2023-12-11: test fails in multipath_iscsi and other multi-machine scenarios due to MTU size auto_review:"ping with packet size 1350 failed, problems with MTU":retry
Updated by okurz over 1 year ago
- Related to coordination #111929: [epic] Stable multi-machine tests covering multiple physical workers added
Updated by okurz over 1 year ago
- Related to deleted (coordination #111929: [epic] Stable multi-machine tests covering multiple physical workers)
Updated by okurz over 1 year ago
- Related to action #136154: multimachine tests restarted by RETRY test variable end up without the proper dependency size:M added
Updated by okurz over 1 year ago
- Subject changed from significant increase in MM-test failure ratio 2023-12-11: test fails in multipath_iscsi and other multi-machine scenarios due to MTU size auto_review:"ping with packet size 1350 failed, problems with MTU":retry to significant increase in MM-test failure ratio 2023-12-11: test fails in multipath_iscsi and other multi-machine scenarios due to MTU size auto_review:"ping with packet size 1350 failed, problems with MTU"
Updated by livdywan over 1 year ago
scheme=http host=openqa.suse.de ./openqa-label-known-issues http://openqa.suse.de/tests/1301886
Updated by okurz over 1 year ago · Edited
openqa-clone-job --skip-chained-deps --parental-inheritance --within-instance https://openqa.suse.de/tests/13018864 _GROUP=0 BUILD=poo152389 TEST+=-152389-okurz
=> sle-15-SP5-Server-DVD-Updates-x86_64-Build20231210-1-qam_kernel_multipath@64bit -> https://openqa.suse.de/tests/13037796
failed reproducibly the same.
negligible change in os-autoinst according to
$ git log1 --no-merges 58c0dd5..3b9f3a2
fdf5f064 Improve `sudo`-usage in `t/20-openqa-isotovideo-utils.t`
2f9d913a Consider code as generally uncoverable when testing relies on `sudo`
diffing between last good https://openqa.suse.de/tests/13010854 and first bad https://openqa.suse.de/tests/13018864 . https://openqa.suse.de/tests/13018864#investigation shows no significant change in test distribution, settings, needles, etc.
From https://openqa.suse.de/tests/13018864/file/multipath_iscsi-ip-addr-show.log I see mtu 1458, so … is that bad?
Using salt I looked up if the MTU size on openvswitch is still set:
sudo salt -C 'G@roles:worker' cmd.run 'sudo ovs-vsctl get int br1 mtu_request'
openqaworker18.qa.suse.cz:
1460
…
same on all machines. So that setting is still active, seems persistent. I reran my investigation job https://openqa.suse.de/tests/13037796 and paused at the failing module, logged in interactively and could confirm that ping -M do -s 1350 -c 1 10.0.2.1 worked fine if both jobs of the cluster are running on the same machine (w30+w30) but failed when running on different machines like in https://openqa.suse.de/tests/13037991 on w36, support_server on w35
I ran tcpdump -l -i br1 icmp on both w35+w36 and could see ICMP echo requests going in and out up to a requested size of 1336 bytes but not above. Then only the echo request is written on the outgoing physical host w36 but not received on w35.
A ping between w35+w36 work up to ping -4 -M do -s 1458 worker36.oqa.prg2.suse.org where tcpdump shows length 1466. Then I ran sudo tcpdump -l -i any 'proto gre' | grep --line-buffered 'worker35.*ICMP echo' and could see
15:13:22.753275 eth0 Out IP worker36.oqa.prg2.suse.org > worker35.oqa.prg2.suse.org: GREv0, length 1386: IP 10.0.2.15 > 10.0.2.1: ICMP ech request, id 14, seq 277, length 1344
15:13:22.756001 eth0 Out IP worker36.oqa.prg2.suse.org > worker35.oqa.prg2.suse.org: GREv0, length 1386: IP 10.0.2.1 > 10.0.2.15: ICMP ech reply, id 14, seq 277, length 1344
so outgoing and ingoing requests tunneled over GRE for requested size of 1336 bytes which is 1344 within GRE and 1386 bytes on the outer layer. Also we can see the reply with same parameters. For a requested size of 1337 when there is no response I see
15:13:32.656890 eth0 Out IP worker36.oqa.prg2.suse.org > worker35.oqa.prg2.suse.org: GREv0, length 1387: IP 10.0.2.15 > 10.0.2.1: ICMP ech request, id 15, seq 1, length 1345
What I don't understand is why on w35 the request comes from qesapworker-prg4.qa.suse.cz instead of the expected w36 and also goes back to there. sudo tcpdump -n -l -i any 'proto gre' | grep --line-buffered 'ICMP echo' actually shows that the same request goes to all GRE connected devices
15:25:16.440214 eth0 In IP 10.145.10.9 > 10.145.10.8: GREv0, length 1386: IP 10.0.2.15 > 10.0.2.1: ICMP echo request, id 20, seq 1, length 1344
15:25:16.441741 eth0 In IP 10.100.101.74 > 10.145.10.8: GREv0, length 1386: IP 10.0.2.15 > 10.0.2.1: ICMP echo request, id 20, seq 1, length 1344
15:25:16.442250 eth0 Out IP 10.145.10.8 > 10.168.192.252: GREv0, length 1386: IP 10.0.2.15 > 10.0.2.1: ICMP echo request, id 20, seq 1, length 1344
15:25:16.442258 eth0 Out IP 10.145.10.8 > 10.168.192.108: GREv0, length 1386: IP 10.0.2.15 > 10.0.2.1: ICMP echo request, id 20, seq 1, length 1344
15:25:16.442264 eth0 Out IP 10.145.10.8 > 10.168.192.254: GREv0, length 1386: IP 10.0.2.15 > 10.0.2.1: ICMP echo request, id 20, seq 1, length 1344
15:25:16.442270 eth0 Out IP 10.145.10.8 > 10.100.101.76: GREv0, length 1386: IP 10.0.2.15 > 10.0.2.1: ICMP echo request, id 20, seq 1, length 1344
15:25:16.442275 eth0 Out IP 10.145.10.8 > 10.100.101.78: GREv0, length 1386: IP 10.0.2.15 > 10.0.2.1: ICMP echo request, id 20, seq 1, length 1344
15:25:16.442281 eth0 Out IP 10.145.10.8 > 10.100.101.80: GREv0, length 1386: IP 10.0.2.15 > 10.0.2.1: ICMP echo request, id 20, seq 1, length 1344
15:25:16.442287 eth0 Out IP 10.145.10.8 > 10.145.10.33: GREv0, length 1386: IP 10.0.2.15 > 10.0.2.1: ICMP echo request, id 20, seq 1, length 1344
15:25:16.442293 eth0 Out IP 10.145.10.8 > 10.145.10.34: GREv0, length 1386: IP 10.0.2.15 > 10.0.2.1: ICMP echo request, id 20, seq 1, length 1344
15:25:16.442298 eth0 Out IP 10.145.10.8 > 10.145.10.2: GREv0, length 1386: IP 10.0.2.15 > 10.0.2.1: ICMP echo request, id 20, seq 1, length 1344
15:25:16.442304 eth0 Out IP 10.145.10.8 > 10.145.10.3: GREv0, length 1386: IP 10.0.2.15 > 10.0.2.1: ICMP echo request, id 20, seq 1, length 1344
15:25:16.442309 eth0 Out IP 10.145.10.8 > 10.145.10.4: GREv0, length 1386: IP 10.0.2.15 > 10.0.2.1: ICMP echo request, id 20, seq 1, length 1344
15:25:16.442314 eth0 Out IP 10.145.10.8 > 10.145.10.5: GREv0, length 1386: IP 10.0.2.15 > 10.0.2.1: ICMP echo request, id 20, seq 1, length 1344
15:25:16.442319 eth0 Out IP 10.145.10.8 > 10.145.10.6: GREv0, length 1386: IP 10.0.2.15 > 10.0.2.1: ICMP echo request, id 20, seq 1, length 1344
15:25:16.442325 eth0 Out IP 10.145.10.8 > 10.145.10.10: GREv0, length 1386: IP 10.0.2.15 > 10.0.2.1: ICMP echo request, id 20, seq 1, length 1344
15:25:16.442331 eth0 Out IP 10.145.10.8 > 10.145.10.11: GREv0, length 1386: IP 10.0.2.15 > 10.0.2.1: ICMP echo request, id 20, seq 1, length 1344
15:25:16.442335 eth0 Out IP 10.145.10.8 > 10.145.10.12: GREv0, length 1386: IP 10.0.2.15 > 10.0.2.1: ICMP echo request, id 20, seq 1, length 1344
15:25:16.442341 eth0 Out IP 10.145.10.8 > 10.145.10.13: GREv0, length 1386: IP 10.0.2.15 > 10.0.2.1: ICMP echo request, id 20, seq 1, length 1344
15:25:16.442515 eth0 Out IP 10.145.10.8 > 10.100.101.74: GREv0, length 1386: IP 10.0.2.1 > 10.0.2.15: ICMP echo reply, id 20, seq 1, length 1344
so it seems the request is sent over all GRE connections, the response only sent over one.
View from w36:
15:29:02.942767 eth0 Out IP 10.145.10.9 > 10.100.101.74: GREv0, length 1386: IP 10.0.2.15 > 10.0.2.1: ICMP echo request, id 23, seq 1, length 1344
15:29:02.946608 eth0 In IP 10.100.101.74 > 10.145.10.9: GREv0, length 1386: IP 10.0.2.1 > 10.0.2.15: ICMP echo reply, id 23, seq 1, length 1344
with 10.100.101.74 being qesapworker-prg4.qa.suse.cz. That's confusing.
Updated by okurz over 1 year ago
- Related to action #151310: [regression] significant increase of parallel_failed+failed since 2023-11-21 size:M added
Updated by okurz over 1 year ago
- Related to action #151612: [kernel][tools] test fails in suseconnect_scc - SUT times out trying to reach https://scc.suse.com added
Updated by okurz over 1 year ago
- Description updated (diff)
- Status changed from New to In Progress
https://gitlab.suse.de/openqa/salt-pillars-openqa/-/merge_requests/693 merged, added rollback step and retriggering jobs with
env host=openqa.suse.de result="result='parallel_failed'" failed_since="2023-12-10" comment="https://progress.opensuse.org/issues/152389" openqa-advanced-retrigger-jobs
retriggering about 1k jobs.
Updated by mkittler over 1 year ago · Edited
From https://openqa.suse.de/tests/13018864/file/multipath_iscsi-ip-addr-show.log I see mtu 1458, so … is that bad?
I would say it is not as it is lower than or equal to what we have set on the bridge (1460).
We created https://openqa.suse.de/tests/13037796#step/multipath_iscsi/20 which ran on w40 (and support server on w39) where the ping test ping -M do -s 1350 -c 1 10.0.2.1; failed with:
PING 10.0.2.1 (10.0.2.1) 1350(1378) bytes of data.
--- 10.0.2.1 ping statistics ---
1 packets transmitted, 0 received, 100% packet loss, time 0ms
I setup two test VMs on w39 and w40 manually (according to https://github.com/os-autoinst/openQA/pull/5394) where I could also reproduce the issue in both directions.
It works just fine up to -s 1340 but as of -s 1341 it fails. It is notable that when dropping -M do it still fails. Normally I'd expected that it would still work (using fragmentation).
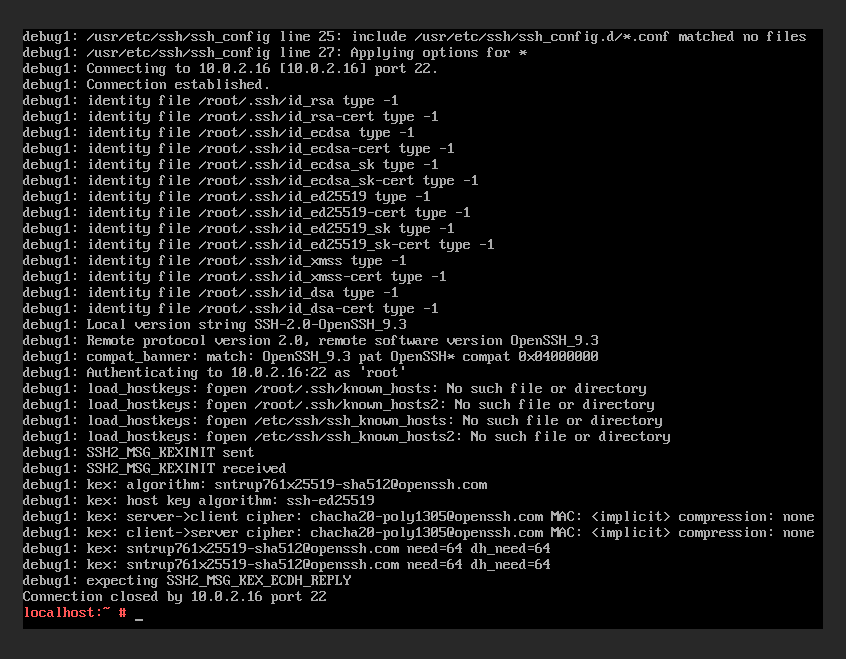
Note that HTTP traffic works as well but SSH already does not (see screenshot with output of ssh -v …; the final connection close there only happened after awaiting a timeout). I guess SSH not working as well is definitely showing the real problem here (as opposed to the rather artificial ping call).
The boundary of 1340 is actually different than the one @okurz mentioned before:
so outgoing and ingoing requests tunneled over GRE for requested size of 1336 bytes which is 1344 within GRE and 1386 bytes on the outer layer. Also we can see the reply with same parameters. For a requested size of 1337 when there is no response I see
I assume the difference between out experiments is that @okurz pinged a worker host from the VM and I pinged another VM from the VM. I couldn't reproduce the behavior exactly, though.
I tried to ping w40 from the VM on w39 via ping -M do -s 1430 -c1 10.145.10.13 and it still worked. Only ping -M do -s 1431 -c1 10.145.10.13 failed but with the very explicit error "ping: local error: message too long, mtu=1458". If I drop -M do to allow fragmentation then the ping works just fine as well (then also e.g. -s 10000 works just fine). It is exactly the same the other way around. Note that SSH traffic from a VM to just another worker host works as well.
I'm going to debug this further with tcpdump tomorrow. We're probably having the issue of fragments being dropped. The VM-to-VM traffic seems mainly affected (not the VM-to-whatever traffic).
Updated by okurz over 1 year ago · Edited
- Description updated (diff)
mkittler wrote in #note-14:
I assume the difference between out experiments is that @okurz pinged a worker host from the VM and I pinged another VM from the VM. I couldn't reproduce the behavior exactly, though.
No, it was actually VM to VM, so VM on worker36 over GRE tunnels to VM on worker35.
I found that my mitigation to disable the tap class was incomplete due to outdated local git workspace so I added
https://gitlab.suse.de/openqa/salt-pillars-openqa/-/commit/4be80b2c720f6023b20355c9f4ac71096dc0aee4 to also disable tap on w35+w36 and retriggered tests accordingly.
https://openqa.suse.de/tests/13042194 from the original scenario is passed so mitigation is effective.
Updated by mkittler over 1 year ago
By the way, I also had a look at MAC addresses because I had to pick ones for my VMs that don't conflict with what we use for our normal VMs.
I exported relevant worker IDs via
\copy ( select distinct workers.id from workers join worker_properties on workers.id = worker_properties.worker_id where worker_properties.key = 'WORKER_CLASS' and worker_properties.value like '%tap%' ) to '/tmp/tap_workers' csv;
and computed the MAC addresses we'd assign to our VMs via
perl -e 'use Mojo::File qw(path); print(map { $workerid = $_; map { sprintf("52:54:00:12:%02x:%02x\n", int($workerid / 256) + $_ * 64, $workerid % 256) } (1..3) } split("\n", path("/hdd//tmp/tap_workers")->slurp))'
according to code in os-autoinst/backend/qemu.pm to check whether we'd create invalid MAC addressed. At this point we don't create any (and there are also no duplicates). I guess we also have lots of room as the highest worker ID until we'd create invalid IDs would be 16320 (0x40 * 0xFF).
Updated by mkittler over 1 year ago
No, it was actually VM to VM, so VM on worker36 over GRE tunnels to VM on worker35.
Strange, so depending on the particular workers we get different results (w35/36 vs. w39/40). But I guess it is the same problem nevertheless.
Updated by openqa_review over 1 year ago
- Due date set to 2023-12-26
Setting due date based on mean cycle time of SUSE QE Tools
Updated by okurz over 1 year ago
- Related to action #152461: [core][tools] test fails in various s390x-kvm tests with "s390x-kvm[\S\s]*(command 'zypper -n in[^\n]*timed out|sh install_k3s.sh[^\n]*failed)" added
Updated by okurz over 1 year ago
I think it's likely that #152461 could also be related to this.
Updated by okurz over 1 year ago
@mkittler I also suggest to extend the ticket description with https://progress.opensuse.org/projects/openqav3/wiki/#Further-decision-steps-working-on-test-issues
Updated by mkittler over 1 year ago · Edited
Setting the MTU on the bridge back to 1450 on both workers via sudo ovs-vsctl set int br1 mtu_request=1450 did not change anything. So the recent bump from 1450 to 1460 is not responsible. Reverting the MTU on the bridge back to the supposed default of 1500 changed nothing as well.
Lowering the MTU to 1000 on both bridges and to 1000 also within the VMs actually helps. Likely one doesn't have to go that low; I still have to figure out the boundary. When keeping the MTU on the VMs at 1458 it would not help. However, it seems the MTU can be higher than 1000 within the VMs. Of course this is now without -M do because otherwise we'd of course run into "message too long, mtu=1000" again. But before it also got stuck without -M do so lowering the MTU on the bridge further definitely improves the situation. This way it is also possible to establish an SSH connection between the machines which timed out before as well.
EDIT: It looks like that lowering the MTU to 1367 in the VMs and keeping the bridges on 1460 is actually sufficient. This still means -M do does not work (1367 is bigger than 1350 what we use in the ping command but with the overhead it apparently exceeds 1367). But SSH and probably other applications we actually care about do. So at least as a mitigation we could:
- Lower the MTU within the SUTs from 1458 to 1367 (or maybe go even a little bit lower than the exact boundary).
- Change the ping test from
ping -M do -s 1350 …toping -M do -s 1339 …(or again go a little bit lower than the exact boundary).
Updated by mkittler over 1 year ago
I now retried reverting our MTU changes again as in the previous comment but now via sudo ovs-vsctl set int br1 mtu_request=[] which will actually restore open vSwitch's default behavior (as documented on https://docs.openvswitch.org/en/latest/faq/issues). However, that doesn't seem to change any of the various cases and behaviors mentioned in my last comment.
Updated by okurz over 1 year ago
- Related to action #152095: [spike solution][timeboxed:8h] Ping over GRE tunnels and TAP devices and openvswitch outside a VM with differing packet sizes size:S added
Updated by mkittler over 1 year ago
When only connecting w39 and w40 with each other then ping -M do -s 1350 … works after setting the MTU on the worker hosts back to 1458. (With the current MTU limit of 1460 on the bridge and also using 1460 in the VM a ping with no fragmentation up to 1432 via ping -M do -s 1432 … is possible.)
Note that I did the following for just connecting those two hosts:
for i in {1..21}; do sudo ovs-vsctl del-port br1 gre$i ; done # on both hosts
sudo ovs-vsctl add-port br1 gre1 -- set interface gre1 type=gre options:remote_ip=10.145.10.12 # on w40
sudo ovs-vsctl add-port br1 gre1 -- set interface gre1 type=gre options:remote_ip=10.145.10.13 # on w39
Updated by mkittler over 1 year ago · Edited
After #152389#note-29 it works and executing
sudo ovs-vsctl --may-exist add-port br1 gre5 -- set interface gre5 type=gre options:remote_ip=10.100.101.74 # qesapworker-prg4.qa.suse.cz
on w39/w40 breaks it again.
After
sudo ovs-vsctl del-port br1 gre5
and waiting shortly it works again.
When adding worker38.oqa.prg2.suse.org and worker-arm1.oqa.prg2.suse.org one after another it keeps working. I noticed that when adding another host the ping is shortly getting stuck and "Destination Host Unreachable" may be repeated a few times. However, then the situation is resolving itself. So I re-conducted the test from before adding qesapworker-prg4.qa.suse.cz again and waited 5 minutes. Even then the situation was not resolving itself. So adding this host is definitely problematic (and I was not just too impatient). It also keeps working after adding qesapworker-prg5.qa.suse.cz so the qesapworker-prgX.qa.suse.cz workers are not generally problematic.
Updated by okurz over 1 year ago
- Copied to action #152557: unexpected routing between PRG1/NUE2+PRG2 added
Updated by mkittler over 1 year ago
After scheduling MM jobs only on one worker the fail ratio declined a bit but not much: https://monitor.qa.suse.de/d/nRDab3Jiz/openqa-jobs-test?orgId=1&viewPanel=24&from=1702227764694&to=1702464789789
So I executed host=openqa.suse.de result="result='parallel_failed'" failed_since="2023-12-12" comment="https://progress.opensuse.org/issues/152389" ./openqa-advanced-retrigger-jobs to restart MM failures that haven't been restarted yet.
Not sure whether we should limit the execution of MM jobs also for ARM workers. They currently have definitely a quite high fail ratio:
openqa=> select distinct count(jobs.id) as total, sum(case when jobs.result in ('failed', 'incomplete') then 1 else 0 end) * 100. / count(jobs.id) as fail_rate_percent, host from jobs left join job_dependencies on (id = child_job_id or id = parent_job_id) join workers on jobs.assigned_worker_id = workers.id where dependency = 2 and t_finished >= '2023-12-12' group by host having count(jobs.id) > 50 order by fail_rate_percent desc;
total | fail_rate_percent | host
-------+---------------------+-------------
144 | 29.1666666666666667 | worker-arm2
138 | 20.2898550724637681 | worker-arm1
2442 | 6.2653562653562654 | worker38
(3 rows)
Updated by mkittler over 1 year ago · Edited
- Description updated (diff)
Setting the MTU on the bridge to something very low (e.g. sudo ovs-vsctl set int br1 mtu_request=1000) doesn't help and actually doesn't change anything.
I re-conducted my tests from #152389#note-32 but this time attempting an ssh connection instead of the rather artificial ping. The result is the same. So I updated H2.5.1 to be accepted.
Maybe the routing problem (#152557 / https://sd.suse.com/servicedesk/customer/portal/1/SD-142223) is also the culprit here. I've been updating the hypotheses accordingly.
So I guess I'm mainly waiting on #152557 then. I'll nevertheless keep the ticket in progress as I'm still monitoring the situation and maybe do a few experiments when I have an idea.
Updated by livdywan over 1 year ago
- Subject changed from significant increase in MM-test failure ratio 2023-12-11: test fails in multipath_iscsi and other multi-machine scenarios due to MTU size auto_review:"ping with packet size 1350 failed, problems with MTU" to significant increase in MM-test failure ratio 2023-12-11: test fails in multipath_iscsi and other multi-machine scenarios due to MTU size auto_review:"ping with packet size 1350 failed, problems with MTU" size:M
- Description updated (diff)
Updated by mkittler over 1 year ago · Edited
MR for removing problematic hosts from the GRE network: https://gitlab.suse.de/openqa/salt-pillars-openqa/-/merge_requests/700
I removed the problematic hosts from the GRE network non-persistently as mentioned in the MR and scheduled some test jobs:
for i in 29 31 33 35 37 39 ; do sudo openqa-clone-job --skip-download --skip-chained-deps --within-instance http://openqa.suse.de/tests/13066500 WORKER_CLASS:qam_kernel_multipath=qemu_x86_64,worker$i WORKER_CLASS:qam_kernel_multipath_supportserver=qemu_x86_64,worker$((i + 1)) {BUILD,TEST}+=-poo152389 _GROUP=0 ; done
Cloning parents of sle-15-SP5-Server-DVD-Updates-x86_64-Build20231213-1-qam_kernel_multipath@64bit
Cloning parents of sle-15-SP5-Server-DVD-Updates-x86_64-Build20231213-1-qam_kernel_multipath_supportserver@64bit
Cloning children of sle-15-SP5-Server-DVD-Updates-x86_64-Build20231213-1-qam_kernel_multipath_supportserver@64bit
2 jobs have been created:
- sle-15-SP5-Server-DVD-Updates-x86_64-Build20231213-1-qam_kernel_multipath_supportserver@64bit -> http://openqa.suse.de/tests/13072417
- sle-15-SP5-Server-DVD-Updates-x86_64-Build20231213-1-qam_kernel_multipath@64bit -> http://openqa.suse.de/tests/13072416
Cloning parents of sle-15-SP5-Server-DVD-Updates-x86_64-Build20231213-1-qam_kernel_multipath@64bit
Cloning parents of sle-15-SP5-Server-DVD-Updates-x86_64-Build20231213-1-qam_kernel_multipath_supportserver@64bit
Cloning children of sle-15-SP5-Server-DVD-Updates-x86_64-Build20231213-1-qam_kernel_multipath_supportserver@64bit
2 jobs have been created:
- sle-15-SP5-Server-DVD-Updates-x86_64-Build20231213-1-qam_kernel_multipath_supportserver@64bit -> http://openqa.suse.de/tests/13072419
- sle-15-SP5-Server-DVD-Updates-x86_64-Build20231213-1-qam_kernel_multipath@64bit -> http://openqa.suse.de/tests/13072418
Cloning parents of sle-15-SP5-Server-DVD-Updates-x86_64-Build20231213-1-qam_kernel_multipath@64bit
Cloning parents of sle-15-SP5-Server-DVD-Updates-x86_64-Build20231213-1-qam_kernel_multipath_supportserver@64bit
Cloning children of sle-15-SP5-Server-DVD-Updates-x86_64-Build20231213-1-qam_kernel_multipath_supportserver@64bit
2 jobs have been created:
- sle-15-SP5-Server-DVD-Updates-x86_64-Build20231213-1-qam_kernel_multipath_supportserver@64bit -> http://openqa.suse.de/tests/13072420
- sle-15-SP5-Server-DVD-Updates-x86_64-Build20231213-1-qam_kernel_multipath@64bit -> http://openqa.suse.de/tests/13072421
Cloning parents of sle-15-SP5-Server-DVD-Updates-x86_64-Build20231213-1-qam_kernel_multipath@64bit
Cloning parents of sle-15-SP5-Server-DVD-Updates-x86_64-Build20231213-1-qam_kernel_multipath_supportserver@64bit
Cloning children of sle-15-SP5-Server-DVD-Updates-x86_64-Build20231213-1-qam_kernel_multipath_supportserver@64bit
2 jobs have been created:
- sle-15-SP5-Server-DVD-Updates-x86_64-Build20231213-1-qam_kernel_multipath_supportserver@64bit -> http://openqa.suse.de/tests/13072423
- sle-15-SP5-Server-DVD-Updates-x86_64-Build20231213-1-qam_kernel_multipath@64bit -> http://openqa.suse.de/tests/13072422
Cloning parents of sle-15-SP5-Server-DVD-Updates-x86_64-Build20231213-1-qam_kernel_multipath@64bit
Cloning parents of sle-15-SP5-Server-DVD-Updates-x86_64-Build20231213-1-qam_kernel_multipath_supportserver@64bit
Cloning children of sle-15-SP5-Server-DVD-Updates-x86_64-Build20231213-1-qam_kernel_multipath_supportserver@64bit
2 jobs have been created:
- sle-15-SP5-Server-DVD-Updates-x86_64-Build20231213-1-qam_kernel_multipath_supportserver@64bit -> http://openqa.suse.de/tests/13072424
- sle-15-SP5-Server-DVD-Updates-x86_64-Build20231213-1-qam_kernel_multipath@64bit -> http://openqa.suse.de/tests/13072425
Cloning parents of sle-15-SP5-Server-DVD-Updates-x86_64-Build20231213-1-qam_kernel_multipath@64bit
Cloning parents of sle-15-SP5-Server-DVD-Updates-x86_64-Build20231213-1-qam_kernel_multipath_supportserver@64bit
Cloning children of sle-15-SP5-Server-DVD-Updates-x86_64-Build20231213-1-qam_kernel_multipath_supportserver@64bit
2 jobs have been created:
- sle-15-SP5-Server-DVD-Updates-x86_64-Build20231213-1-qam_kernel_multipath_supportserver@64bit -> http://openqa.suse.de/tests/13072426
- sle-15-SP5-Server-DVD-Updates-x86_64-Build20231213-1-qam_kernel_multipath@64bit -> http://openqa.suse.de/tests/13072427
EDIT: All tests have passed: https://openqa.suse.de/tests/13072427#next_previous
Within my VMs SSH is also still working and ping with even higher sizes (still keeping -M do). So from my side we could go on with merging the MR.
Updated by mkittler over 1 year ago
- Priority changed from Urgent to High
I'm lowering the priority as it already looks better. The fail ratio on https://monitor.qa.suse.de/d/nRDab3Jiz/openqa-jobs-test?orgId=1&viewPanel=24&from=now-7d&to=now is not below 20 % but judging from the failures I briefly had a look at I'd say that there might also be problems that have nothing to do with the MTU/ping problem. The ping test issues and timeouts on TLS connections seem to be gone at least, e.g. the scenario mentioned in the ticket description passes now despite jobs being scheduled on different workers (https://openqa.suse.de/tests/13076014).
Updated by pcervinka over 1 year ago
There is another round of MTU issues https://openqa.suse.de/tests/13093924#step/multipath_iscsi/26
Updated by mkittler over 1 year ago · Edited
I can also reproduce it in test VMs with my usual test setup. This time a size of 1350 actually works but 1400 is too much. SSH also doesn't work again.
I don't see the workers I previously found problematic and removed via https://gitlab.suse.de/openqa/salt-pillars-openqa/-/merge_requests/700 anymore (sudo salt -C 'G@roles:worker' cmd.run 'grep "10.100.101" /etc/wicked/scripts/gre_tunnel_preup.sh' shows no results). So that means it is not just that the removal of these workers was not persistent.
Updated by okurz over 1 year ago
Both merged. I executed now
env host=openqa.suse.de result="result='parallel_failed'" failed_since="2023-12-17" comment="label:https://progress.opensuse.org/issues/152389" openqa-advanced-retrigger-jobs
Updated by okurz over 1 year ago
mkittler missed some workers. Now did https://gitlab.suse.de/openqa/salt-pillars-openqa/-/merge_requests/702
and retriggered again failed tests. Monitoring, e.g. on https://monitor.qa.suse.de/d/nRDab3Jiz/openqa-jobs-test?orgId=1&from=now-2d&to=now&viewPanel=24
Updated by okurz over 1 year ago · Edited
Regarding the original problem it seems like the following. We have all openQA workers connected with GRE tunnels with point to point. With that all are inter-connected, also across locations, using GRE tunnels. Using STP to prevent loops that apparently causes inefficient routes like worker38 in PRG2 going over a FC Basement worker back to PRG2 which also means that we are limited with the maximum MTU that we can support. So my suggestions are the following
- DONE via https://github.com/os-autoinst/os-autoinst-distri-opensuse/pull/18353 Make the use of MTU in os-autoinst-distri-opensuse configurable, i.e. the value that the support_server sets as well as the ping_size_check
-
REJECTED Use the minimum MTU in both os-autoinst-distri-opensuse as well as https://gitlab.suse.de/openqa/salt-states-openqa/-/blob/master/openqa/openvswitch.sls to be "on the safe side" for across-location tunneled GRE configurations
- Likely not very useful because that MTU might be too low for certain test scenarios (e.g. Wireguard tunnel). So I guess there's rather a "safe middle" (and not a "safe side").
-
REJECTED Only enable "tap" in our workerconf.sls within one location per one architecture, e.g. only ppc64le tap in NUE2, only x86_64 tap in PRG2
- We already have that which I've just double-checked. However, that is not very helpful because thanks to our network topology relying on STP the shortest route might not be taken so traffic between ppc64le hosts might still go though an x86_64 host on a different site.
- Change https://gitlab.suse.de/openqa/salt-states-openqa/-/blob/master/openqa/openvswitch.sls to only enable GRE tunnels on machines within the same datacenter, e.g. "location-prg" and rename accordingly in https://gitlab.suse.de/openqa/salt-pillars-openqa/-/blob/master/openqa/workerconf.sls
- Follow #152737 regarding scheduling limited to individual zone
Updated by dheidler over 1 year ago
I did some package dumps using tcpdump and wireshark and checked the overhead of the tunnel.
We are adding 20 Bytes of IP header, 4 Bytes of GRE header and 14 Bytes of the inner Ethernet header.
So in totel we have 38 Bytes of overhead.
So if there are two workers in the same network and are using an MTU of 1500 on their ethernet interfaces with the path mtu being 1500 as well,
we have left an MTU of 1462 according to my calculation. Currently we seem to set it to 1458 by default in lib/mm_network.pm.
This makes sense if we take the 4 Byte VLAN tag into our calculation.
Updated by okurz over 1 year ago
- Related to action #152755: [tools] test fails in scc_registration - SCC not reachable despite not running multi-machine tests? size:M added
Updated by dheidler over 1 year ago
As I described in https://sd.suse.com/servicedesk/customer/portal/1/SD-142688 we seem to have a path MTU of 1422 between NUE2 and PRG2.
So the infra maintained VPN tunnel between that locations produces 78 Bytes of overhead.
Our own GRE tunnel produces 42 Bytes of overhead if we want to use VLANs within our tunnel.
So if we would use an MTU of 1380 in our SUT VMs, we shouldn't run into issues even with inter location links.
(That is true at least as long as we use ipv4 to transport our GRE packets.)
Also 1380 is still enough to use IPv6 within our gre tunnel (IPv6 requires 1280 at least).
Updated by mkittler over 1 year ago
- Status changed from In Progress to Feedback
Just for the record, the fail ratio is getting better (with the current mitigations in place): https://monitor.qa.suse.de/d/nRDab3Jiz/openqa-jobs-test?orgId=1&viewPanel=24
I will not do any further changes before the Christmas break. If someone wants to try something, e.g. following up on the first points of #152389#note-45 (using the MTU size mentioned in #152389#note-48) feel free to take over.
Updated by dheidler over 1 year ago
Updated by okurz over 1 year ago
- Description updated (diff)
- Due date changed from 2023-12-26 to 2024-01-19
- Priority changed from High to Normal
I put the suggestions from #152389-45 into the description.
https://github.com/os-autoinst/os-autoinst-distri-opensuse/pull/18351 merged.
From
https://monitor.qa.suse.de/d/nRDab3Jiz/openqa-jobs-test?orgId=1&from=now-2d&to=now&viewPanel=24
we see a significant improvement with parallel_failed+failed below 10% so we can monitor over the next week with lower prio.
In the meantime the open suggestions can still be executed.
Updated by mkittler over 1 year ago
PR for suggestion 1. from #152389#note-45: https://github.com/os-autoinst/os-autoinst-distri-opensuse/pull/18353
Updated by mkittler over 1 year ago
The PR has been merged.
The test scenario mentioned specifically in the ticket description (https://openqa.suse.de/tests/latest?arch=x86_64&distri=sle&flavor=Server-DVD-Updates&machine=64bit&test=qam_kernel_multipath&version=15-SP5) looks good. However, parallel_failed+failed on https://monitor.qa.suse.de/d/nRDab3Jiz/openqa-jobs-test?orgId=1&from=now-2d&to=now&viewPanel=24 is only slightly below 20 % right now.
I suppose I'll have to investigate what the remaining issues are and we can decide in the next infra call on further steps.
Updated by mkittler over 1 year ago
Looks like many jobs were just failing because the cache queue on the server was full. However, those jobs were also restarted/cloned and usually passed eventually. (Yes, those jobs end up as incomplete which we don't consider here. However, other jobs in the cluster might end up as parallel failed (depending on timing it can also be skipped), see e.g. https://openqa.suse.de/tests/13205056#dependencies.)
Some jobs were also just retried via RETRY=1 which in fact worked.
So I ran the query behind the graph manually filtering out jobs that have been cloned:
openqa=> with mm_jobs as (select distinct id, result from jobs left join job_dependencies on (id = child_job_id or id = parent_job_id) where t_created >= (select timezone('UTC', now()) - interval '24 hour') and result != 'none' and dependency = 2 and clone_id is null) select result, round(count(id) * 100. / (select count(id) from mm_jobs), 2)::numeric(5,2)::float as ratio_mm from mm_jobs group by mm_jobs.result;
result | ratio_mm
------------------+----------
user_cancelled | 0.21
softfailed | 12.42
passed | 69.49
skipped | 3.53
timeout_exceeded | 0.21
failed | 3.1
incomplete | 2.25
parallel_failed | 8.78
With this we're actually significantly below 20 % again.
Suggestion for changing the graph's query to exclude cloned jobs: https://gitlab.suse.de/openqa/salt-states-openqa/-/merge_requests/1075
Updated by mkittler over 1 year ago
This way the list of failing tests since the last few days isn't that long anymore:
openqa=> select distinct count(jobs.id), array_agg(jobs.id), (select name from job_groups where id = group_id), (array_agg(test))[1] as example_test from jobs left join job_dependencies on (id = child_job_id or id = parent_job_id) and clone_id is null where dependency = 2 and t_finished >= '2024-01-05' and result in ('failed', 'incomplete') and test not like '%:investigate:%' group by group_id order by count(jobs.id) desc;
count | array_agg | name | ex
ample_test
-------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------------------------------------+--------------------
----------------------------
27 | {13207621,13212384,13212409,13212411,13212413,13212391,13212393,13212382,13207606,13207619,13202969,13202997,13202986,13202989,13207617,13207593,13207600,13212395,13207626,13202976,13202971,13202993,13207589,13212379,13207624,13202995,13202982} | YaST Maintenance Updates - Development | mru-iscsi_client_no
rmal_auth_backstore_hdd_dev
8 | {13207688,13207685,13203162,13198611,13203166,13198614,13212493,13212496} | Test Security | fips_tests_xrdp_rem
ote-desktop-supportserver4
6 | {13212364,13205300,13212387,13202921,13205457,13200618} | SAP/HA Maintenance Updates | qam_ha_rolling_upgr
ade_migration_node01
5 | {13216762,13217139,13215349,13215148,13217143} | Maintenance - QR - SLE15SP5-SAP | sles4sap_hana_node0
1
3 | {13200538,13205121,13209956} | JeOS: Development | jeos-nfs-client
3 | {13215098,13214992,13215064} | Maintenance - QR - SLE15SP5-Security | fips_ker_stunnel_se
rver
1 | {13217096} | | ha_hawk_haproxy_nod
e01
1 | {13217531} | HA Development | ha_zalpha_node2_pub
lish
(8 rows)
I'll look into those tests tomorrow.
Updated by mkittler over 1 year ago
The remaining failures are about missing assets and other non-networking-related issues. The only exception is the test module patch_and_reboot, e.g. https://openqa.suse.de/tests/13212384 (https://openqa.suse.de/tests/latest?arch=x86_64&distri=sle&flavor=Server-DVD-Updates&machine=64bit&test=mru-iscsi_client_normal_auth_backstore_lvm_dev&version=12-SP5). But this module seems broken since months.
Updated by okurz over 1 year ago · Edited
https://monitor.qa.suse.de/d/nRDab3Jiz/openqa-jobs-test?orgId=1&viewPanel=24&from=1704964971248&to=1704966378145 shows a good decrease of incomplete+failed+parallel_failed so we are at 1+7+19=27% so that part is covered.
@mkittler I suggest to look into the open points of #152389-45 again
Updated by mkittler over 1 year ago · Edited
- Status changed from Feedback to In Progress
I updated #152389#note-45. The only remaining points are 4 and 5 and 5 is already just a reference to a follow-up ticket. So I'll try to implement 4 if it isn't difficult (and otherwise create a separate ticket for it).
EDIT: Drafts for 4: https://gitlab.suse.de/openqa/salt-states-openqa/-/merge_requests/1079, https://gitlab.suse.de/openqa/salt-pillars-openqa/-/merge_requests/705
If this is wanted I can continue with it. (The Jinja code probably doesn't work that way and I'll need to refactor it. However, the current draft should give an idea of it'll look like.)
Updated by mkittler over 1 year ago
I guess https://gitlab.suse.de/openqa/salt-states-openqa/-/merge_requests/1079 worked as intended but there are some remarks:
- Now tap_poo… worker classes are no longer considered when creating the setup script for the GRE tunnel connections. So /etc/wicked/scripts/gre_tunnel_preup.sh only exists on worker38 and arm1 anymore at this point. The other aspects of the setup (e.g. creation of tap devices) are not affected, though. I think that's actually a good/acceptable change. Currently GRE tunnels are completely disabled anyways (see next point) so this change currently doesn't affect us at all anyway.
- Maybe we could remove the "# Disabling GRE tunnels due to https://progress.opensuse.org/issues/152389" workaround to try with the split and thus now smaller GRE networks. Due to the previous point we currently only had one GRE network between arm-1 and worker38 as both are on the same location and both are the only workers with the production tap worker class. It would of course gain us not much as our MM capacity wouldn't go up.
- There's no GRE network/config for PowerPC workers at all because mania is the only PowerPC worker with production tap class and also the only tap worker in general on its site. So also in this edge case the configuration (or rather absence of it) looks good.
Updated by mkittler over 1 year ago
- Status changed from In Progress to Feedback
MRs for rollback steps:
- https://gitlab.suse.de/openqa/salt-states-openqa/-/merge_requests/1083
- https://gitlab.suse.de/openqa/salt-pillars-openqa/-/merge_requests/707
I removed the silence as the alerts would not fire anymore right now anyway and it would be good to be alerted in case merging the above changes caused problems.
@livdywan mentioned it would make sense to split these roll back steps into a separate ticket which makes sense considering how long this ticket has already been in progress. We can discuss that in tomorrow's infra daily.
Updated by okurz over 1 year ago
mkittler wrote in #note-60:
@livdywan mentioned it would make sense to split these roll back steps into a separate ticket which makes sense considering how long this ticket has already been in progress. We can discuss that in tomorrow's infra daily.
Well, considering that you already created the merge requests to revert and as you already removed the silence I suggest to give it a go and merge both MRs at your covenience but closely monitor today+tomorrow. If there is any problem then revert again and plan the rollbacks in separate ticket(s).
Updated by okurz over 1 year ago
- Status changed from Feedback to In Progress
- Priority changed from Normal to Urgent
https://openqa.suse.de/tests/13263418#step/iscsi_client/32 shows problematic. I suggest to revert your latest changes and please fix the according test failures.
Updated by okurz over 1 year ago · Edited
mkittler triggered a reboot for all OSD workers and now I did
env host=openqa.suse.de result="result='parallel_failed'" failed_since="2024-01-16 12:00Z" comment="label:poo#152389" ./openqa-advanced-retrigger-jobs
which retriggered about 300 jobs
EDIT: Jobs like https://openqa.suse.de/tests/13263920 look ok again as well as https://monitor.qa.suse.de/d/nRDab3Jiz/openqa-jobs-test?orgId=1&from=now-3h&to=now&viewPanel=24
@mkittler as you already assumed that a reboot would fix the issue maybe we can come up with a better approach to ensure the according network parts are actively reloaded/restarted to prevent a similar issue in the future?
Updated by mkittler over 1 year ago · Edited
- Priority changed from Urgent to Normal
Yes, the jobs look good again - despite being scheduled across multiple workers. So I'm lowering the priority again.
maybe we can come up with a better approach to ensure the according network parts are actively reloaded/restarted to prevent a similar issue in the future?
It would have already helped to re-run the setup script again, e.g. sudo salt -C 'G@roles:worker' cmd.run '/etc/wicked/scripts/gre_tunnel_preup.sh update br1'. We could automate this of course by adding an according salt state that runs whenever that script changes. The script already deletes all existing ports before adding new ones so this shouldn't be problematic. It may still disrupt tests, though. At least when I did experiments like #152389#note-32 I always had to wait shortly until everything worked again after deleting/adding ports. (That's probably because STP needs to do its job which doesn't happen instantly.)
Updated by okurz over 1 year ago
cat /etc/wicked/scripts/gre_tunnel_preup.sh update br1? are you missing a pipe?
Updated by mkittler over 1 year ago
No, but I had a cat too much :-)
(I edited the comment. I only copied that from the history where I used cat to check the file contents.)
Updated by mkittler over 1 year ago
- Status changed from In Progress to Resolved
I followed all rollback steps and the fail ratio looks acceptable. I created #153769 as a follow-up for the problem mentioned in previous comments.
Updated by mkittler over 1 year ago
- Related to action #153769: Better handle changes in GRE tunnel configuration size:M added
Updated by okurz over 1 year ago
- Copied to action #153880: https://openqa.suse.de/tests/13277880#step/patterns/96 not being able to resolve download.suse.de, likely DNS problems in PRG1 added
Updated by okurz over 1 year ago
- Related to action #154552: [ppc64le] test fails in iscsi_client - zypper reports Error Message: Could not resolve host: openqa.suse.de added
Updated by okurz about 1 year ago
- Copied to action #160652: Secondary TAP worker class in different zones size:S added