action #120651
open[openQA][infra][ipmi][worker][api] The expected pattern CMD_FINISHED-xxxxx returned but did not show up in serial log (wait_serial timed out) size:M
0%
Description
Observation¶
Recently, I found some new failures share the same symptom and failed due to the same reason, for example:
test 9968639 worker2:18 wait_serial timed out after waiting for more than 10 hours.
test 9962611 worker2:18 wait_serial timed out after waiting for more than 10 hours.
These two 9973067 worker2:18 and 9975435 worker2:19 are about to fail as well due to the same reason.
But, actually, all guests were successfully installed by the failed module:
fozzie-1:~ # virsh list --all
Id Name State
--------------------------------------------
0 Domain-0 running
- sles-12-sp5-64-fv-def-net shut off
- sles-12-sp5-64-pv-def-net shut off
fozzie-1:~ #
fozzie-1:~ # virsh start sles-12-sp5-64-fv-def-net
Domain sles-12-sp5-64-fv-def-net started
fozzie-1:~ # virsh start sles-12-sp5-64-pv-def-net
Domain sles-12-sp5-64-pv-def-net started
fozzie-1:~ #
fozzie-1:~ # virsh list --all
Id Name State
-------------------------------------------
0 Domain-0 running
22 sles-12-sp5-64-fv-def-net running
23 sles-12-sp5-64-pv-def-net running
fozzie-1:~ #
--- 192.168.123.10 ping statistics ---
5 packets transmitted, 0 received, +5 errors, 100% packet loss, time 4088ms
pipe 4
fozzie-1:~ # ping -c5 192.168.123.10
PING 192.168.123.10 (192.168.123.10) 56(84) bytes of data.
64 bytes from 192.168.123.10: icmp_seq=1 ttl=64 time=2315 ms
64 bytes from 192.168.123.10: icmp_seq=2 ttl=64 time=1294 ms
64 bytes from 192.168.123.10: icmp_seq=3 ttl=64 time=270 ms
64 bytes from 192.168.123.10: icmp_seq=4 ttl=64 time=0.314 ms
64 bytes from 192.168.123.10: icmp_seq=5 ttl=64 time=0.285 ms
--- 192.168.123.10 ping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 4060ms
rtt min/avg/max/mdev = 0.285/776.139/2315.106/905.173 ms, pipe 3
fozzie-1:~ # ping -c5 192.168.123.11
PING 192.168.123.11 (192.168.123.11) 56(84) bytes of data.
64 bytes from 192.168.123.11: icmp_seq=1 ttl=64 time=0.352 ms
64 bytes from 192.168.123.11: icmp_seq=2 ttl=64 time=0.239 ms
64 bytes from 192.168.123.11: icmp_seq=3 ttl=64 time=0.217 ms
64 bytes from 192.168.123.11: icmp_seq=4 ttl=64 time=0.213 ms
64 bytes from 192.168.123.11: icmp_seq=5 ttl=64 time=0.227 ms
--- 192.168.123.11 ping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 4083ms
rtt min/avg/max/mdev = 0.213/0.249/0.352/0.054 ms
fozzie-1:~ # ssh 192.168.123.10
Warning: Permanently added '192.168.123.10' (ECDSA) to the list of known hosts.
Password:
linux:~ #
linux:~ # cat /etc/os-release
.bash_history .cache/ .dbus/ .gnupg/ .kbd/ bin/ inst-sys/
linux:~ # cat /etc/os-release
NAME="SLES"
VERSION="12-SP5"
VERSION_ID="12.5"
PRETTY_NAME="SUSE Linux Enterprise Server 12 SP5"
ID="sles"
ANSI_COLOR="0;32"
CPE_NAME="cpe:/o:suse:sles:12:sp5"
linux:~ # exit
logout
Connection to 192.168.123.10 closed.
fozzie-1:~ # ssh 192.168.123.11
Warning: Permanently added '192.168.123.11' (ECDSA) to the list of known hosts.
Password:
linux:~ # cat /etc/os-release
NAME="SLES"
VERSION="12-SP5"
VERSION_ID="12.5"
PRETTY_NAME="SUSE Linux Enterprise Server 12 SP5"
ID="sles"
ANSI_COLOR="0;32"
CPE_NAME="cpe:/o:suse:sles:12:sp5"
And the entered cmd as below (wait_serial had been waiting for its return) already returned before wait_serial timed out, namely failed test run:
(rm /var/log/qa/old* /var/log/qa/ctcs2/* -r;/usr/share/qa/tools/test-VH-Upgrade-std-xen-sles12sp5-sles15sp5-run 02; echo CMD_FINISHED-339853) 2>&1 | tee -a /dev/sshserial\n
This can also been seen clearly from screenshot below:
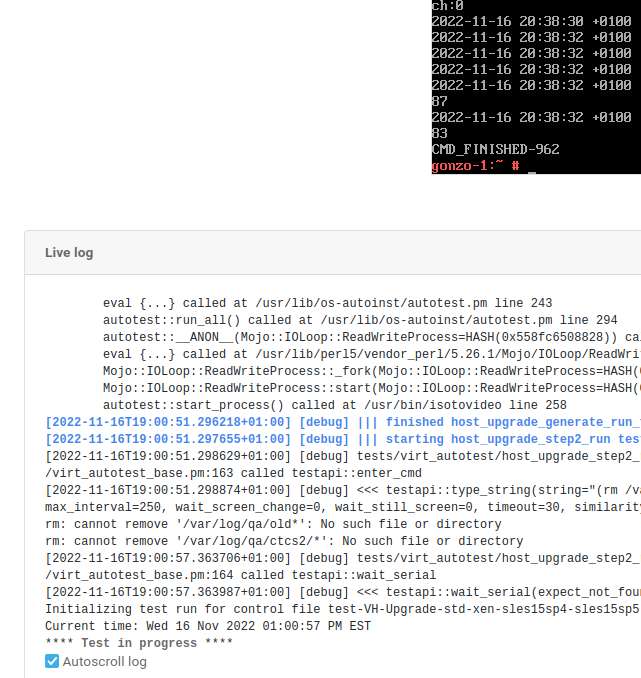
These tests has been keeping failing to pass since Build40.1. Sometimes they can pass this module and go further, for example, this one. But they failed most times. Fortunately some other tests, which use and run the same test module in the same way, can pass completely, for example, passed 1 worker2:20 and passed 2 worker2:19. There is no such problem being spotted in earlier days.
Probably there is something wrong with openQA infra recently.
Steps to reproduce¶
- Use reproducer mentioned in #120651#note-45
- Trigger test run with openQA for tests prj2_host_upgrade_sles12sp5_to_developing_xen or prj2_host_upgrade_sles12sp5_to_developing_xen on a worker slot on openqaworker2 (note that slots have been moved to grenache-1 by https://gitlab.suse.de/openqa/salt-pillars-openqa/-/merge_requests/465 so supposedly at least one slot needed to be moved back to openqaworker2)
- Wait for results of whether they fail at wait_serial time-out at step host_upgrade_step2_run
Impact¶
This affects overall virtualization test run efficiency and prevents test results from being generated in a timely manner, because we have to re-run many times and, at the same time, investigate the issue.
Problem¶
Looks like problem with openQA infra, including networking connection, worker2 performance and os-autoinst engine.
Acceprance criteria¶
- AC1: No more test timeouts
Suggestion¶
- Look into openQA infra connection and network performance
- Look into worker2 healthy status
- Look into os-autoinst engine
Workaround¶
None
Files
| prj2_step2_wait_serial.png (113 KB) prj2_step2_wait_serial.png | |||
| dev_sshserial_feed_01.png (96.7 KB) dev_sshserial_feed_01.png | |||
| dev_sshserial_feed_02.png (63.4 KB) dev_sshserial_feed_02.png |
Updated by waynechen55 over 2 years ago
- Subject changed from [openQA][infra][ipmi][worker][api] The expected pattenr CMD_FINISHED-xxxxx returned but did not show up in serial log to [openQA][infra][ipmi][worker][api] The expected pattenr CMD_FINISHED-xxxxx returned but did not show up in serial log (wait_serial timed out)
Updated by okurz over 2 years ago
- Target version set to future
We don't have the capacity to investigate this further within the tools team right now
Updated by Julie_CAO over 2 years ago
these tests failed in 'wait_serial' too. The $cmd output can be found in redirected log files on the SUT. It indicates that the problem is nothing to do with the $cmd itself.
my $pattern = "CMD_FINISHED-" . int(rand(999999));
enter_cmd "(" . $cmd . "; echo $pattern) 2>&1 | tee -a /dev/$serialdev";
$self->{script_output} = wait_serial($pattern, 10);
https://openqa.suse.de/tests/9968784/logfile?filename=autoinst-log.txt
https://openqa.suse.de/tests/9949100/logfile?filename=autoinst-log.txt
https://openqa.suse.de/tests/9951737/logfile?filename=autoinst-log.txt
[2022-11-16T03:58:42.390729+01:00] [debug] <<< testapi::wait_serial(timeout=20970, no_regex=0, buffer_size=undef, record_output=undef, expect_not_found=0, quiet=undef, regexp="CMD_FINISHED-566583")
Initializing test run for control file test_virtualization-guest-migrate-xen.tcf...
Current time: Tue 15 Nov 2022 09:58:42 PM EST
**** Test in progress ****
XIO: fatal IO error 11 (Resource temporarily unavailable) on X server ":46527"
after 28847 requests (28847 known processed) with 0 events remaining.
XIO: fatal IO error 11 (Resource temporarily unavailable) on X server ":56017"
XIO: fatal IO error 11 (Resource temporarily unavailable) on X server ":51767"
after 28856 requests (28856 known processed) with 0 events remaining.
after 28691 requests (28691 known processed) with 0 events remaining.
XIO: fatal IO error 11 (Resource temporarily unavailable) on X server ":52645"
after 28853 requests (28853 known processed) with 0 events remaining.
[2022-11-16T07:21:29.218227+01:00] [debug] autotest received signal TERM, saving results of current test before exiting
[2022-11-16T07:21:29.218269+01:00] [debug] isotovideo received signal TERM
[2022-11-16T07:21:29.218418+01:00] [debug] backend got TERM
Updated by waynechen55 over 2 years ago
I did some investigation further on this issue. I think this might be related to openQA infra and it worth having a look.
Because I found the /dev/sshserial device died and had no response to anything feed into it, so serial log can not be updated. This is the root cause.
I also did some experiments look like below:
gonzo-1:~ # (for i in seq 21 30; do echo -e "test$i" | tee -a /dev/sshserial;done)
This command hang for good. It never returned.
As product QA we never use /dev/sshserial and do not know too much about it. It is being used by openQA automation infra to capture serial output.
Could you or someone else help have a look at this issue ? @okurz
Updated by okurz over 2 years ago
waynechen55 wrote:
As product QA we never use /dev/sshserial and do not know too much about it. It is being used by openQA automation infra to capture serial output.
Not sure what you mean with "As product QA we never use /dev/sshserial". "sshserial" is only defined within https://github.com/os-autoinst/os-autoinst-distri-opensuse/search?q=sshserial.
I suggest to look into the "Investigation" information on https://openqa.suse.de/tests/9968639#investigation
Your team opted to not have automatically triggered openqa-investigate jobs, see https://gitlab.suse.de/openqa/salt-states-openqa/-/blob/master/openqa/server.sls#L81 . So I suggest if not sure about the source of this regression trigger those tests manually following https://github.com/os-autoinst/scripts/blob/master/README.md#openqa-investigate---automatic-investigation-jobs-with-failure-analysis-in-openqa
As your test involves cross-network communication, e.g. from the openQA worker to the SUT, in case of worker2:18 it's "gonzo.qa.suse.de", and also a qadb host might be involved – not sure about that – please closely check the communication paths and if machines can reach each other over the necessary network protocols. If you identify a problem please ping "@Lazaros Haleplidis" in #eng-testing or #discusse-qe-new-security-zones about this.
Updated by okurz over 2 years ago
- Status changed from New to In Progress
- Assignee set to okurz
- Target version changed from future to Ready
I will try to help with that. This seems related to https://suse.slack.com/archives/C0488BZNA5S/p1668720128410659
Updated by okurz over 2 years ago
I reminded Lazaros Haleplidis in https://suse.slack.com/archives/C0488BZNA5S/p1668765124910939?thread_ts=1668720128.410659&cid=C0488BZNA5S
@Lazaros Haleplidis as stated earlier: Please see all traffic going to machines within the domain .qa.suse.de as legit. For example the rack https://racktables.nue.suse.com/index.php?page=rack&rack_id=18106
Updated by waynechen55 over 2 years ago
- Assignee deleted (
okurz) - Target version deleted (
Ready)
okurz wrote:
waynechen55 wrote:
As product QA we never use /dev/sshserial and do not know too much about it. It is being used by openQA automation infra to capture serial output.
Not sure what you mean with "As product QA we never use /dev/sshserial". "sshserial" is only defined within https://github.com/os-autoinst/os-autoinst-distri-opensuse/search?q=sshserial.
I suggest to look into the "Investigation" information on https://openqa.suse.de/tests/9968639#investigation
Your team opted to not have automatically triggered openqa-investigate jobs, see https://gitlab.suse.de/openqa/salt-states-openqa/-/blob/master/openqa/server.sls#L81 . So I suggest if not sure about the source of this regression trigger those tests manually following https://github.com/os-autoinst/scripts/blob/master/README.md#openqa-investigate---automatic-investigation-jobs-with-failure-analysis-in-openqa
As your test involves cross-network communication, e.g. from the openQA worker to the SUT, in case of worker2:18 it's "gonzo.qa.suse.de", and also a qadb host might be involved – not sure about that – please closely check the communication paths and if machines can reach each other over the necessary network protocols. If you identify a problem please ping "@Lazaros Haleplidis" in #eng-testing or #discusse-qe-new-security-zones about this.
I will following these instructions to look into this issue further. One thing I can confirm is gonzo can ping worker2 and OSD successfully during test run.
Updated by waynechen55 over 2 years ago
- Assignee set to okurz
- Target version set to Ready
Updated by waynechen55 over 2 years ago
- File dev_sshserial_feed_01.png dev_sshserial_feed_01.png added
- File dev_sshserial_feed_02.png dev_sshserial_feed_02.png added
After I looked into this issue further, I think there is something very wrong with openQA worker2(and associated SUT machines). Let me lay current situation out as below step by step:
In order to exclude noise from affecting test results, I re-ran those two problematic test suites at weekend. Both of them were assigned to grenache-1:10 which successfully executed test runs. They passed. Please refer to passed test run 1 with grenache-1:10 and passed test run 2 with grenache-1:10.
On the contrast, another failed test run also happened at weekend with worker2:18 still failed. The test suite behind this failed test run is the same as one behind passed test run 2 with grenache-1:10.
All above test runs performed with the latest Build42.5. Although I do not think it is very necessary to do any bisect, I still did it on the failed test run. Please refer to the result. I do not think there is something relevant in the investigation result. But I do think some lines of code in os-autoinst should be paid more attention to, for example, Net2::SSH2 connect and VIDEO_ENCODER_BLOCKING_PIPE.
Back to the failed test runs, they failed due to the same reason in comment#5. For the normal test run, the root-ssh console is added and activated as below:
Firstly, add console as per https://github.com/os-autoinst/os-autoinst-distri-opensuse/blob/baaae06b73af1e2d6bae3dd4fde237d1a47cbf7b/lib/susedistribution.pm#L506
Secondly, connect ssh as per https://github.com/os-autoinst/os-autoinst/blob/17a0b01efc6fce2619a58150ebf28e492eb37c51/backend/baseclass.pm#L1170
Finally, activate ssh as per https://github.com/os-autoinst/os-autoinst/blob/17a0b01efc6fce2619a58150ebf28e492eb37c51/consoles/sshXtermVt.pm#L12
So for normal test run, if you log into the SUT machine via ssh, you should see this with "ps aux | grep sshserial":root 2849 0.0 0.0 15284 3740 pts/0 Ss+ 12:24 0:00 bash -c rm -f /dev/sshserial; mkfifo /dev/sshserial; chmod 666 /dev/sshserial; while true; do cat /dev/sshserial; doneAnything feed into /dev/sshserial will be shown up in autoinst-log and serial0, for example, (for i in
seq 1 10; do echo -e "test$i" | tee -a /dev/sshserial;done) will generate follow outputs:

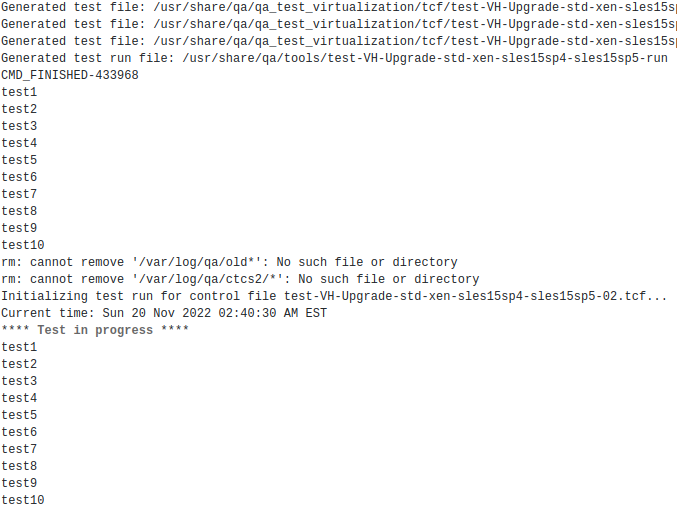
By the contrast, it seems that the background process:
root 2849 0.0 0.0 15284 3740 pts/0 Ss+ 12:24 0:00 bash -c rm -f /dev/sshserial; mkfifo /dev/sshserial; chmod 666 /dev/sshserial; while true; do cat /dev/sshserial; donedid not exist for the failed test run, so there is no way for the test run output to show up in autoinst-log and serial0 which leads to wait_serial timed out. It looks like the background run process exited or crashed around one hour after test run started ((rm /var/log/qa/old* /var/log/qa/ctcs2/* -r;/usr/share/qa/tools/test-VH-Upgrade-std-xen-sles12sp5-sles15sp5-run 02; echo CMD_FINISHED-339853) 2>&1 | tee -a /dev/sshserial\n). Initially, I thought it might be related to the timeout setting for ssh connection as per Net2::SSH2 connect. But host_upgrade_step2_run in passed test run 1 with grenache-1:10 and passed test run 2 with grenache-1:10 also exceeded the given time-out value, so it is a little bit confusing. Additionally, I am not very sure whether it has something to do with this change VIDEO_ENCODER_BLOCKING_PIPE.
Additionally, I do not have access to openQA worker machine, so I can not do more investigation on worker side. I can not tell whether there is some kind of crashes happened there that can also lead to this issue. At least, there were no errors/warnings/crashes reported on SUT machine. Actually, this background process:rm -f /dev/sshserial; mkfifo /dev/sshserial; chmod 666 /dev/sshserial; while true; do cat /dev/sshserial; doneis run by backend/console ssh instance on worker's local ssh terminal. So it is very likely a worker2/backend/console issue from my POV. IMHO.
All in all, the same test suite passed with grenache-1:10 but constantly failed with worker2:x, which also means the same release and version of operating system and background process run very well with openqaimip5 machine but failed with gonzo-1 machine. It seems all these results point to unknown environment issue that might be related to recent openQA migration and security zone change activity(generally speaking). To be specific, there might be something wrong with worker2.
@okurz I think this may worth looking into deeper both on your and my sides. I think you should give worker2 a very careful scrutiny on os-autoinst engine, backend/console and also worker2 itself healthy status.
Updated by waynechen55 over 2 years ago
I also did additional experiment only on SUT machines, gonzo-1 and amd-zen3-gpu-sut1-1, which are associated with worker2:x. They run 15-SP4 and 12-SP5 Xen which are the same OS as those problematic test suites where failures happened.
- Open ssh session 1 to these machines
- Run following command:
bash -c "rm -f /dev/sshserial; mkfifo /dev/sshserial; chmod 666 /dev/sshserial; while true; do cat /dev/sshserial; done"
- Open ssh session 2 to these machines
- Run following command:
ps axu | grep ssheserial
- Keep monitoring whether the executed command still exists on these machines after 1 hour.
- Also try to type in in ssh session 2:
(for i in `seq 1 10`;do echo -e "test$i" | tee -a /dev/sshserial;done)
and to see corresponding output at ssh session 1.
The result is the executed command still existed on these machines after 1 hour or even longer and echo messages can go through the pipe without problem. So there is nothing wrong with the SUT machine and operating systems. My conclusion is there is something wrong with the worker2 machine or worker2 process. IMHO.
Updated by okurz over 2 years ago
- Due date set to 2022-12-02
waynechen55 wrote:
[…] So there is nothing wrong with the SUT machine and operating systems. My conclusion is there is something wrong with the worker2 machine or worker2 process. IMHO.
Yes, I assume so as well. The difference to grenache-1.qa.suse.de is that worker2 is already in the new security zone hence traffic might be blocked.
Now traffic between .oqa.suse.de and .qa.suse.de unblocked, see #120264#note-9
https://openqa.suse.de/tests/10002485#live is currently running but it was started before the latest firewall change was applied so this might still fail. Will need to retrigger in that case and check again.
EDIT: Monitor https://openqa.suse.de/tests/10004844
Updated by waynechen55 over 2 years ago
okurz wrote:
waynechen55 wrote:
[…] So there is nothing wrong with the SUT machine and operating systems. My conclusion is there is something wrong with the worker2 machine or worker2 process. IMHO.
Yes, I assume so as well. The difference to grenache-1.qa.suse.de is that worker2 is already in the new security zone hence traffic might be blocked.
Now traffic between .oqa.suse.de and .qa.suse.de unblocked, see #120264#note-9
https://openqa.suse.de/tests/10002485#live is currently running but it was started before the latest firewall change was applied so this might still fail. Will need to retrigger in that case and check again.
EDIT: Monitor https://openqa.suse.de/tests/10004844
All worker2:x failed due to
[2022-11-21T21:05:29.827996+01:00] [debug] loaded 11779 needles
Need variable WORKER_HOSTNAME at /usr/lib/os-autoinst/backend/ipmi.pm line 14.
backend::ipmi::new("backend::ipmi") called at /usr/lib/os-autoinst/backend/driver.pm line 34
backend::driver::new("backend::driver", "ipmi") called at /usr/lib/os-autoinst/OpenQA/Isotovideo/Backend.pm line 14
OpenQA::Isotovideo::Backend::new("OpenQA::Isotovideo::Backend") called at /usr/bin/isotovideo line 260
[2022-11-21T21:05:29.875786+01:00] [debug] stopping command server 9895 because test execution ended through exception
[2022-11-21T21:05:30.076511+01:00] [debug] done with command server
[2022-11-21T21:05:30.076589+01:00] [debug] stopping autotest process 9905
[2022-11-21T21:05:30.277176+01:00] [debug] done with autotest process
9889: EXIT 1
[2022-11-21T21:05:30.341373+01:00] [info] [pid:9819] Isotovideo exit status: 1
[2022-11-21T21:05:30.384309+01:00] [info] [pid:9819] +++ worker notes +++
[2022-11-21T21:05:30.384465+01:00] [info] [pid:9819] End time: 2022-11-21 20:05:30
[2022-11-21T21:05:30.384622+01:00] [info] [pid:9819] Result: died
[2022-11-21T21:05:30.390995+01:00] [info] [pid:9967] Uploading vars.json
[2022-11-21T21:05:30.427263+01:00] [info] [pid:9967] Uploading autoinst-log.txt
Updated by okurz over 2 years ago
@mkittler can you please look into
Need variable WORKER_HOSTNAME at /usr/lib/os-autoinst/backend/ipmi.pm line 14
Looks like we need to save the auto-discovered worker hostname into the vars
Updated by mkittler over 2 years ago
- Status changed from Feedback to Resolved
- Assignee changed from mkittler to okurz
Looks like we need to save the auto-discovered worker hostname into the vars
We already do. Whether the setting is auto-detected or read from the INI file shouldn't influence how it is further passed down at all. The job mentioned in one of the recent comments here was running on worker2, likely on an outdated version of the worker (see #120261#note-32 for details). So I'd refrain from reopening this ticket and handle the problem in #120261 (so comments about the same problem aren't spread over multiple tickets).
Updated by waynechen55 over 2 years ago
I need to have a look whether the original reported issue have been fixed. I do not think so at the moment. But I will have a look and will re-open this ticket if not.
Updated by waynechen55 over 2 years ago
- Status changed from Resolved to Workable
- Priority changed from High to Urgent
waynechen55 wrote:
I need to have a look whether the original reported issue have been fixed. I do not think so at the moment. But I will have a look and will re-open this ticket if not.
Unfortunately, the original issue has not been fixed. Hope you do not mind I pushing up the priority a bit, because it affects multiple test scenarios and some of these test scenarios can only run with affected workers, for example, this one.
The root cause had already been explained very clearly in comment#15 and comment#16.
Updated by okurz over 2 years ago
- Due date deleted (
2022-12-02) - Assignee deleted (
okurz)
Updated by mkittler over 2 years ago
- Status changed from Workable to Feedback
- Assignee set to mkittler
Additionally, I do not have access to openQA worker machine, so I can not do more investigation on worker side.
You can add your ssh key by adding it to https://gitlab.suse.de/openqa/salt-pillars-openqa/-/blob/master/sshd/users.sls via a MR.
Note that none of the mentioned tests had a wrong/missing WORKER_HOSTNAME. So this issue is happening despite a correct WORKER_HOSTNAME and completely unrelated to #120651#note-18.
The most recent jobs I've found that failed with host_upgrade_step2_run are from 4 days ago. All more recent jobs failed in earlier or later modules. So I'm not sure whether it is still reproducible.
Can you check whether the issue is still happening and if it does what traffic needs to be unblocked specifically? (I'm not familiar with your test scenario so it is better that you check yourself.) But I can also not help directly with unblocking any traffic as I don't have access to the firewall. You can reach people who can help you with that directly via the Slack channel #discuss-qe-new-security-zones so don't hesitate to ask there.
Updated by waynechen55 over 2 years ago
- Assignee changed from mkittler to okurz
- Priority changed from Urgent to High
mkittler wrote:
Additionally, I do not have access to openQA worker machine, so I can not do more investigation on worker side.
You can add your ssh key by adding it to https://gitlab.suse.de/openqa/salt-pillars-openqa/-/blob/master/sshd/users.sls via a MR.
Note that none of the mentioned tests had a wrong/missing
WORKER_HOSTNAME. So this issue is happening despite a correctWORKER_HOSTNAMEand completely unrelated to #120651#note-18.
The most recent jobs I've found that failed with
host_upgrade_step2_runare from 4 days ago. All more recent jobs failed in earlier or later modules. So I'm not sure whether it is still reproducible.Can you check whether the issue is still happening and if it does what traffic needs to be unblocked specifically? (I'm not familiar with your test scenario so it is better that you check yourself.) But I can also not help directly with unblocking any traffic as I don't have access to the firewall. You can reach people who can help you with that directly via the Slack channel #discuss-qe-new-security-zones so don't hesitate to ask there.
The issue can be reproduced, please refer to the latest run started 4 hours ago. The test command already returned but not shown up in serial log. So it will fail after time out. I can not come up anything about what kind of specific traffic is involved at the moment. We do need your help as well.
Updated by waynechen55 over 2 years ago
I think the correct step to take to tackle the issue is to look what has been changed to worker2 compared with gernache-1. Because the same test run can pass with grenache-1, for example , this one. I think you can help provide more information about what has been changed before and after security zone change or between worker2 and grenache-1. So we can have a overall cognition. We can not proceed without knowing too much about the change itself.
Updated by mkittler over 2 years ago
- Assignee changed from okurz to mkittler
- Priority changed from High to Urgent
I think the correct step to take to tackle the issue is to look what has been changed to worker2 compared with gernache-1.
The obvious change is that worker2 has been moved to a separate "security zone" so traffic might be blocked. Unfortunately I have no further insights as well because this change isn't handled by our team and we don't have access to relevant systems. Besides the security zone move no other changes come to my mind except that we're now using an FQDN instead of an IP for WORKER_HOSTNAME. However, setting WORKER_HOSTNAME that way works now. And besides, that change was also made on grenache-1 so it cannot be the culprit considering it works there. In fact, all other changes I can think of were also conducted on grenache-1. This really leaves only the security zone move of which I don't have much insights.
I suppose we need to find out what traffic is being blocked. I've just tested curl http://qadb2.suse.de on worker2 and it works. Likely the problem then happens on the upload (so the IPMI host sp.gonzo.qa.suse.de cannot reach back to worker2).
Updated by mkittler over 2 years ago
I can reach the command server of the currently running test from OSD so what I've wrote in the last paragraph of my last comment is likely not correct:
martchus@openqa:~> curl http://worker2.oqa.suse.de:20203/__91iqDX54nDADlw
<!DOCTYPE html>
…
Of course it might be different on the IPMI host sp.gonzo.qa.suse.de. Note that I cannot connect to the IPMI host via SSH (to check from there):
ssh sp.gonzo.qa.suse.de
Unable to negotiate with 10.162.3.50 port 22: no matching host key type found. Their offer: ssh-rsa,ssh-dss
When HostKeyAlgorithms +ssh-rsa,ssh-dss I can connect as ADMIN with the password from the worker config. However, this system is very strange and I have no idea how I'd do an HTTP request from there.
Maybe you can do further debugging following my example? If you want to test whether the command server is reachable from the SUT you can simply try to do a request like I did on OSD. The URL is always different for different jobs but can be found in autoinst-log.txt in the pool directory (/var/lib/openqa/pool/X) of the running job on worker2.oqa.suse.de.
Updated by mkittler over 2 years ago
Apparently the host scooter-1 is involved as well. In fact, that's the SUT and likely more relevant than the IPMI host. From there I can also reach back to the command server on worker2:
scooter-1:~ # curl http://worker2.oqa.suse.de:20203/__91iqDX54nDADlw
<!DOCTYPE html>
Not sure what else to try.
I'm also wondering what this test is waiting for. The last lines in the serial log are:
nJW_3-1-
qvxX0-0-
Generated test file: /usr/share/qa/qa_test_virtualization/tcf/test-VH-Upgrade-std-xen-sles15sp4-sles15sp5-01.tcf, link to /usr/share/qa/tcf/test-VH-Upgrade-std-xen-sles15sp4-sles15sp5-01.tcf
Generated test file: /usr/share/qa/qa_test_virtualization/tcf/test-VH-Upgrade-std-xen-sles15sp4-sles15sp5-02.tcf, link to /usr/share/qa/tcf/test-VH-Upgrade-std-xen-sles15sp4-sles15sp5-02.tcf
Generated test file: /usr/share/qa/qa_test_virtualization/tcf/test-VH-Upgrade-std-xen-sles15sp4-sles15sp5-03.tcf, link to /usr/share/qa/tcf/test-VH-Upgrade-std-xen-sles15sp4-sles15sp5-03.tcf
Generated test run file: /usr/share/qa/tools/test-VH-Upgrade-std-xen-sles15sp4-sles15sp5-run
CMD_FINISHED-123757
nJW_3-1-
qvxX0-0-
rm: cannot remove '/var/log/qa/old*': No such file or directory
rm: cannot remove '/var/log/qa/ctcs2/*': No such file or directory
Initializing test run for control file test-VH-Upgrade-std-xen-sles15sp4-sles15sp5-02.tcf...
Current time: Wed 23 Nov 2022 03:09:02 AM EST
**** Test in progress ****
But what's actually supposed to happen here?
Updated by waynechen55 over 2 years ago
- Assignee changed from mkittler to okurz
- Priority changed from Urgent to High
mkittler wrote:
Apparently the host
scooter-1is involved as well. In fact, that's the SUT and likely more relevant than the IPMI host. From there I can also reach back to the command server on worker2:scooter-1:~ # curl http://worker2.oqa.suse.de:20203/__91iqDX54nDADlw <!DOCTYPE html>Not sure what else to try.
I'm also wondering what this test is waiting for. The last lines in the serial log are:
nJW_3-1- qvxX0-0- Generated test file: /usr/share/qa/qa_test_virtualization/tcf/test-VH-Upgrade-std-xen-sles15sp4-sles15sp5-01.tcf, link to /usr/share/qa/tcf/test-VH-Upgrade-std-xen-sles15sp4-sles15sp5-01.tcf Generated test file: /usr/share/qa/qa_test_virtualization/tcf/test-VH-Upgrade-std-xen-sles15sp4-sles15sp5-02.tcf, link to /usr/share/qa/tcf/test-VH-Upgrade-std-xen-sles15sp4-sles15sp5-02.tcf Generated test file: /usr/share/qa/qa_test_virtualization/tcf/test-VH-Upgrade-std-xen-sles15sp4-sles15sp5-03.tcf, link to /usr/share/qa/tcf/test-VH-Upgrade-std-xen-sles15sp4-sles15sp5-03.tcf Generated test run file: /usr/share/qa/tools/test-VH-Upgrade-std-xen-sles15sp4-sles15sp5-run CMD_FINISHED-123757 nJW_3-1- qvxX0-0- rm: cannot remove '/var/log/qa/old*': No such file or directory rm: cannot remove '/var/log/qa/ctcs2/*': No such file or directory Initializing test run for control file test-VH-Upgrade-std-xen-sles15sp4-sles15sp5-02.tcf... Current time: Wed 23 Nov 2022 03:09:02 AM EST **** Test in progress ****But what's actually supposed to happen here?
Firstly:¶
The test output from ((rm /var/log/qa/old* /var/log/qa/ctcs2/* -r;/usr/share/qa/tools/test-VH-Upgrade-std-xen-sles12sp5-sles15sp5-run 02; echo CMD_FINISHED-339853) 2>&1 | tee -a /dev/sshserial\n) is supposed to be put there. The most relevant part of the test is (/usr/share/qa/tools/test-VH-Upgrade-std-xen-sles12sp5-sles15sp5-run 02; echo CMD_FINISHED-339853) 2>&1 | tee -a /dev/sshserial\n. The test output from script /usr/share/qa/tools/test-VH-Upgrade-std-xen-sles12sp5-sles15sp5-run is appended to /dev/sshserial. The /dev/sshserial is a device added by openQA automation (Not added by me or my group. It is added by distribution base module).
Quoting from #120651#note-15:¶
Back to the failed test runs, they failed due to the same reason in comment#5. For the normal test run, the root-ssh console is added and activated as below:
Firstly, add console as per https://github.com/os-autoinst/os-autoinst-distri-opensuse/blob/baaae06b73af1e2d6bae3dd4fde237d1a47cbf7b/lib/susedistribution.pm#L506
Secondly, connect ssh as per https://github.com/os-autoinst/os-autoinst/blob/17a0b01efc6fce2619a58150ebf28e492eb37c51/backend/baseclass.pm#L1170
Finally, activate ssh as per https://github.com/os-autoinst/os-autoinst/blob/17a0b01efc6fce2619a58150ebf28e492eb37c51/consoles/sshXtermVt.pm#L12
So for normal test run, if you log into the SUT machine via ssh, you should see this with "ps aux | grep sshserial":root 2849 0.0 0.0 15284 3740 pts/0 Ss+ 12:24 0:00 bash -c rm -f /dev/sshserial; mkfifo /dev/sshserial; chmod 666 /dev/sshserial; while true; do cat /dev/sshserial; doneAnything feed into /dev/sshserial will be shown up in autoinst-log and serial0, for example, (for i in
seq 1 10; do echo -e "test$i" | tee -a /dev/sshserial;done) will generate follow outputs:
By the contrast, it seems that the background process:
root 2849 0.0 0.0 15284 3740 pts/0 Ss+ 12:24 0:00 bash -c rm -f /dev/sshserial; mkfifo /dev/sshserial; chmod 666 /dev/sshserial; while true; do cat /dev/sshserial; donedid not exist for the failed test run, so there is no way for the test run output to show up in autoinst-log and serial0 which leads to wait_serial timed out. It looks like the background run process exited or crashed around one hour after test run started ((rm /var/log/qa/old* /var/log/qa/ctcs2/* -r;/usr/share/qa/tools/test-VH-Upgrade-std-xen-sles12sp5-sles15sp5-run 02; echo CMD_FINISHED-339853) 2>&1 | tee -a /dev/sshserial\n). Initially, I thought it might be related to the timeout setting for ssh connection as per Net2::SSH2 connect. But host_upgrade_step2_run in passed test run 1 with grenache-1:10 and passed test run 2 with grenache-1:10 also exceeded the given time-out value, so it is a little bit confusing. Additionally, I am not very sure whether it has something to do with this change VIDEO_ENCODER_BLOCKING_PIPE.
Additionally, I do not have access to openQA worker machine, so I can not do more investigation on worker side. I can not tell whether there is some kind of crashes happened there that can also lead to this issue. At least, there were no errors/warnings/crashes reported on SUT machine. Actually, this background process:rm -f /dev/sshserial; mkfifo /dev/sshserial; chmod 666 /dev/sshserial; while true; do cat /dev/sshserial; doneis run by backend/console ssh instance on worker's local ssh terminal. So it is very likely a worker2/backend/console issue from my POV. IMHO.
Quoting from #120651#note-16:¶
I also did additional experiment only on SUT machines, gonzo-1 and amd-zen3-gpu-sut1-1, which are associated with worker2:x. They run 15-SP4 and 12-SP5 Xen which are the same OS as those problematic test suites where failures happened.
- Open ssh session 1 to these machines
- Run following command:
bash -c "rm -f /dev/sshserial; mkfifo /dev/sshserial; chmod 666 /dev/sshserial; while true; do cat /dev/sshserial; done"
- Open ssh session 2 to these machines
- Run following command:
ps axu | grep ssheserial
- Keep monitoring whether the executed command still exists on these machines after 1 hour.
- Also try to type in in ssh session 2:
(for i in `seq 1 10`;do echo -e "test$i" | tee -a /dev/sshserial;done)
and to see corresponding output at ssh session 1.
The result is the executed command still existed on these machines after 1 hour or even longer and echo messages can go through the pipe without problem. So there is nothing wrong with the SUT machine and operating systems. My conclusion is there is something wrong with the worker2 machine or worker2 process. IMHO.
At the last:¶
The worker process starts a ssh connection to SUT machine. The worker ssh connection process runs
bash -c "rm -f /dev/sshserial; mkfifo /dev/sshserial; chmod 666 /dev/sshserial; while true; do cat /dev/sshserial; done".
But
bash -c "rm -f /dev/sshserial; mkfifo /dev/sshserial; chmod 666 /dev/sshserial; while true; do cat /dev/sshserial; done"
exited and disappeared unexpectedly during test run
(/usr/share/qa/tools/test-VH-Upgrade-std-xen-sles12sp5-sles15sp5-run 02; echo CMD_FINISHED-339853) 2>&1 | tee -a /dev/sshserial\n
so test output will not be put in serial and autoinst-log.
Updated by waynechen55 over 2 years ago
I proposed a temporary workaround solution to remove the roadblocker: https://gitlab.suse.de/openqa/salt-pillars-openqa/-/merge_requests/465 @mkittler @okurz
Updated by livdywan over 2 years ago
- Subject changed from [openQA][infra][ipmi][worker][api] The expected pattenr CMD_FINISHED-xxxxx returned but did not show up in serial log (wait_serial timed out) to [openQA][infra][ipmi][worker][api] The expected pattenr CMD_FINISHED-xxxxx returned but did not show up in serial log (wait_serial timed out) size:M
- Assignee changed from okurz to mkittler
@waynechen55 Please try and avoid changing the assignee. Maybe you simply had an old tab open ;-)
Updated by waynechen55 over 2 years ago
- Assignee changed from mkittler to okurz
cdywan wrote:
@waynechen55 Please try and avoid changing the assignee. Maybe you simply had an old tab open ;-)
Maybe. Thanks for reminding.
Updated by waynechen55 over 2 years ago
- Assignee changed from okurz to mkittler
Updated by waynechen55 over 2 years ago
- Priority changed from High to Urgent
I pushed up the priority a bit. It seems that I lowered the priority mistakenly by myself after I pushed it up for the first time. The reason is still the same, it affects and blocks multiple test scenarios, some of which can only run with affected worker2:x.
I logged into grenache-1 and worker2 and lingered there for a while. I found I can not do too much because I am not root. I just filtered out some processes relating to SUT machine which look normal and at the same time, can not obtain more information from them.
Until now, there are 3 kinds of symptoms. I believe the root cause is the same one.
Firstly, test run 1 returned fully and completely on live view. But the returned output did not show up in serial and autoinst-log
Secondly, test run 2 did not even returned fully and completely. Only banners "Test in progress" and "Test run complete"
Thirdly, the same screenshot/autoinst-log/serial0 with "Firstly" but the background process(/usr/share/qa/tools/test-VH-Upgrade-std-xen-sles12sp5-sles15sp5-run 02; echo CMD_FINISHED-339853) 2>&1 | tee -a /dev/sshserial\nstayed longer and exited after test run returned fully and completely but still before wait_serial timed out (namely test suite is still running and ssh console is still open and intact).
Updated by mkittler over 2 years ago
I found I can not do too much because I am not root.
You can use sudo (without needing a password).
I've now merged your workaround PR.
I gather that the "test command" /usr/share/qa/tools/test-VH-Upgrade-std-xen-sles12sp5-sles15sp5-run 02 is the command that is invoked in the SUT which is affected here. Does that test run within the SUT as expected when you invoke it without any additional piping for SSH/serial handling? Will other things show up in the serial console when you pipe then to /dev/sshserial from within the SUT? I'm just wondering whether /dev/sshserial is the culprit here or the "test command" itself. (Maybe your previous comments already state that but I'm not completely sure.)
Updated by waynechen55 over 2 years ago
mkittler wrote:
I found I can not do too much because I am not root.
You can use sudo (without needing a password).
I've now merged your workaround PR.
I gather that the "test command"
/usr/share/qa/tools/test-VH-Upgrade-std-xen-sles12sp5-sles15sp5-run 02is the command that is invoked in the SUT which is affected here. Does that test run within the SUT as expected when you invoke it without any additional piping for SSH/serial handling? Will other things show up in the serial console when you pipe then to/dev/sshserialfrom within the SUT? I'm just wondering whether/dev/sshserialis the culprit here or the "test command" itself. (Maybe your previous comments already state that but I'm not completely sure.)
@mkittler After moved all workers to grenache-1, all affected test suites passed.
I am answering your questions as below:
1) Test run is normal and can return successfully and as expected without additional piping.
2) Yes. Anything feed into /dev/sshserial will show up in serial logs. As long as
bash -c "rm -f /dev/sshserial; mkfifo /dev/sshserial; chmod 666 /dev/sshserial; while true; do cat /dev/sshserial; done"
exist on SUT machine.
All my previous debugging results are all that I can do at that moment. They are also the direct symptoms that I can see till now. I also understand and respect your opinions, namely something to do with security zone changes. I think you can follow your pathway to look into this issue deeper and at the same time, take my findings into consideration as well. It is still not very clear how all these things interplay, but interplay will definitely make the situation complex and the issue difficult to fix.
Updated by mkittler over 2 years ago
- Blocks action #120270: Conduct the migration of SUSE openQA systems IPMI from Nbg SRV1 to new security zones size:M added
Updated by mkittler over 2 years ago
Ok, so the code under test is not the problem. It is presumably the SSH connection used to provide the serial console. Considering it works again when you restore it manually it seems to be a temporary problem. I'm wondering why the security zone move would lead to an SSH connection (that is generally allowed/possible) being interrupted at some point. Maybe some Firewall pokes with the SSH connection as it appears idling/inactive for too long? It seems rather unlikely but I don't know the Firewall (and possibly other networking infrastructure) that's present in the background.
Updated by mkittler over 2 years ago
- Assignee deleted (
mkittler)
Nobody replied when I've asked about what I've wrote in the previous comment in the security zone channel.
I'm unassigning because I'm on vacation and will only be back on Tuesday.
Updated by waynechen55 over 2 years ago
I simplified steps to reproduce the problem and also created reproducer. I think you can also use the reproducer to reproduce the problem steadily. So we do not reply on openQA automation framework, just put everything down to perl scripts which do not include any special traffic (just ssh connection). I do not give my conclusion here at the beginning, please read through following steps one by one in the first place, then I think you can also have clue about what is wrong.
- The reproducer-worker-machine should run on worker machine, for example, worker2 or grenahce-1.
reproducer-worker-machine:
#!/usr/bin/perl
use Net::SSH2;
my $ssh = Net::SSH2->new(timeout => (300 // 5 * 3600) * 1000);
my $counter = 5;
my $con_pretty = "root\@sut-machine-fqdn";
while ($counter > 0) {
if ($ssh->connect('sut-machine-fqdn', 22)) {
$ssh->auth(username => 'username', password => 'password');
print "SSH connection to $con_pretty established" if $ssh->auth_ok;
last;
}
else {
print "Could not connect to $con_pretty, Retrying after some seconds...";
sleep(10);
$counter--;
next;
}
}
my $chan = $ssh->channel() or $ssh->die_with_error;
$chan->blocking(0);
$chan->pty(1);
$chan->ext_data('merge');
$ssh->blocking(1);
if (!$chan->exec('rm -f /dev/sshserial; mkfifo /dev/sshserial; chmod 666 /dev/sshserial; while true; do cat /dev/sshserial; done')) {
print "Can not grab serial console";
}
$ssh->blocking(0);
my $buffer;
my $start_time = time();
while (1) {
while (defined(my $bytes_read = $chan->read($buffer, 4096))) {
return 1 unless $bytes_read > 0;
print $buffer;
open(my $serial, '>>', 'serial0.txt');
print $serial $buffer;
close($serial);
}
last if (time() - $start_time > 28800);
}
- The reproducer-sut-machine-part1 and reproducer-sut-machine-part2 should run on SUT machine (they are just text files that resemble the output from real test script
/usr/share/qa/tools/test-VH-Upgrade-std-xen-sles12sp5-sles15sp5-run 02, you can put any other texts in them as you want).
reproducer-sut-machine-part1:
rm: cannot remove '/var/log/qa/old*': No such file or directory
rm: cannot remove '/var/log/qa/ctcs2/*': No such file or directory
Initializing test run for control file test-VH-Upgrade-std-xen-sles12sp5-sles15sp5-02.tcf...
Current time: Thu Dec 1 01:16:01 EST 2022
**** Test in progress ****
reproducer-sut-machine-part2:
vhPrepAndUpdate ... ... PASSED (1h49m1s)
**** Test run complete ****
Current time: Thu Dec 1 03:05:02 EST 2022
Exiting test run..
Displaying report...
Total test time: 1h49m1s
Tests passed:
vhPrepAndUpdate
**** Test run completed successfully ****
rm: cannot remove '/tmp/virt_screenshot.tar.bz2': No such file or directory
tar: Removing leading `/' from member names
tar: Removing leading `/' from member names
/var/log/libvirt/
/var/log/libvirt/libxl/
/var/log/libvirt/libxl/libxl-driver.log
/var/log/libvirt/libxl/Domain-0.log
/var/log/libvirt/libxl/sles-12-sp5-64-fv-def-net.log
/var/log/libvirt/libxl/sles-12-sp5-64-pv-def-net.log
/var/log/libvirt/lxc/
/var/log/libvirt/qemu/
/var/log/libvirt/libvirtd.log
tar: Removing leading `/' from member names
/var/log/messages
/usr/share/qa/tools/test-VH-Upgrade-std-xen-sles12sp5-sles15sp5-run: line 71: xm: command not found
tar: Removing leading `/' from member names
/var/log/xen/
/var/log/xen/console/
/var/log/xen/xen-boot.prev.log
/var/log/xen/xen-boot.log
/var/log/xen/xen-hotplug.log
/var/log/xen/qemu-dm-sles-12-sp5-64-fv-def-net.log.9
/var/log/xen/qemu-dm-sles-12-sp5-64-fv-def-net.log.8
/var/log/xen/qemu-dm-sles-12-sp5-64-fv-def-net.log.7
/var/log/xen/qemu-dm-sles-12-sp5-64-fv-def-net.log.6
/var/log/xen/qemu-dm-sles-12-sp5-64-fv-def-net.log.5
/var/log/xen/qemu-dm-sles-12-sp5-64-fv-def-net.log.4
/var/log/xen/qemu-dm-sles-12-sp5-64-fv-def-net.log.3
/var/log/xen/qemu-dm-sles-12-sp5-64-fv-def-net.log.2
/var/log/xen/qemu-dm-sles-12-sp5-64-fv-def-net.log.1
/var/log/xen/qemu-dm-sles-12-sp5-64-fv-def-net.log
/var/log/xen/xl-sles-12-sp5-64-fv-def-net.log.2
/var/log/xen/xl-sles-12-sp5-64-fv-def-net.log.1
/var/log/xen/xl-sles-12-sp5-64-fv-def-net.log
/var/log/xen/qemu-dm-sles-12-sp5-64-pv-def-net.log.9
/var/log/xen/qemu-dm-sles-12-sp5-64-pv-def-net.log.8
/var/log/xen/qemu-dm-sles-12-sp5-64-pv-def-net.log.7
/var/log/xen/qemu-dm-sles-12-sp5-64-pv-def-net.log.6
/var/log/xen/qemu-dm-sles-12-sp5-64-pv-def-net.log.5
/var/log/xen/qemu-dm-sles-12-sp5-64-pv-def-net.log.4
/var/log/xen/qemu-dm-sles-12-sp5-64-pv-def-net.log.3
/var/log/xen/qemu-dm-sles-12-sp5-64-pv-def-net.log.2
/var/log/xen/qemu-dm-sles-12-sp5-64-pv-def-net.log.1
/var/log/xen/qemu-dm-sles-12-sp5-64-pv-def-net.log
/var/log/xen/xl-sles-12-sp5-64-pv-def-net.log.2
/var/log/xen/xl-sles-12-sp5-64-pv-def-net.log.1
/var/log/xen/xl-sles-12-sp5-64-pv-def-net.log
tar: Removing leading `/' from member names
/var/lib/xen/dump/
tar: Removing leading `/' from member names
/var/lib/systemd/coredump/
tar: Removing leading `/' from member names
/tmp/vm_backup/vm-config-xmls/
/tmp/vm_backup/vm-config-xmls/sles-12-sp5-64-fv-def-net.xml
/tmp/vm_backup/vm-config-xmls/sles-12-sp5-64-pv-def-net.xml
tar: Removing leading `/' from member names
/usr/share/qa/qa_test_virtualization/tcf/test-VH-Upgrade-std-xen-sles12sp5-sles15sp5-01.tcf
/usr/share/qa/qa_test_virtualization/tcf/test-VH-Upgrade-std-xen-sles12sp5-sles15sp5-02.tcf
/usr/share/qa/qa_test_virtualization/tcf/test-VH-Upgrade-std-xen-sles12sp5-sles15sp5-03.tcf
2022-12-01 03:05:18 -0500 WARNING remote_qa_db_report Not able to find any build_nr.
2022-12-01 03:05:18 -0500 INFO remote_qa_db_report Autodetection results: type='SLES', version='12', subversion='5', release='GM', arch='x86_64', QADB product = 'SLES-12-SP5',Build number = ''
2022-12-01 03:05:18 -0500 INFO remote_qa_db_report Getting RPM info
2022-12-01 03:05:19 -0500 INFO remote_qa_db_report Getting hwinfo
2022-12-01 03:05:31 -0500 INFO remote_qa_db_report Getting running kernel info
2022-12-01 03:05:32 -0500 INFO remote_qa_db_report Copying files over network
Warning: Permanently added 'qadb2.suse.de,10.160.3.68' (ECDSA) to the list of known hosts.
2022-12-01 03:05:32 -0500 INFO remote_qa_db_report ssh qadb_report@qadb2.suse.de -i /usr/share/qa/keys/id_rsa /usr/share/qa/tools/qa_db_report.pl '-b -c "Test result for virtualization host upgrade step 02 test: /usr/share/qa/tcf/test-VH-Upgrade-std-xen-sles12sp5-sles15sp5-02.tcf." -a xen0-x86_64 -m fozzie-1 -p SLES-12-SP5-GM -k 4.12.14-122.139-default -f /tmp/fozzie-1-2022-12-01-03-05-18.tar.gz -L -R'
Warning: Permanently added 'qadb2.suse.de,10.160.3.68' (ECDSA) to the list of known hosts.
2022-12-01 09:05:33 +0100 INFO qa_db_report Loading parser autotest...
2022-12-01 09:05:33 +0100 INFO qa_db_report Loading subparser autotest::autotest_aiostress...
2022-12-01 09:05:33 +0100 INFO qa_db_report Loading subparser autotest::autotest_bonnie...
2022-12-01 09:05:33 +0100 INFO qa_db_report Loading subparser autotest::autotest_cerberus...
2022-12-01 09:05:33 +0100 INFO qa_db_report Loading subparser autotest::autotest_dbench...
2022-12-01 09:05:33 +0100 INFO qa_db_report Loading subparser autotest::autotest_disktest...
2022-12-01 09:05:33 +0100 INFO qa_db_report Loading subparser autotest::autotest_iozone...
2022-12-01 09:05:33 +0100 INFO qa_db_report Loading subparser autotest::autotest_posixtest...
2022-12-01 09:05:33 +0100 INFO qa_db_report Loading subparser autotest::autotest_sleeptest...
2022-12-01 09:05:33 +0100 INFO qa_db_report Loading subparser autotest::autotest_tiobench...
2022-12-01 09:05:33 +0100 INFO qa_db_report Loading subparser autotest::autotest_unixbench...
2022-12-01 09:05:33 +0100 INFO qa_db_report Loading parser cloud...
2022-12-01 09:05:33 +0100 INFO qa_db_report Loading parser ctcs2...
2022-12-01 09:05:33 +0100 INFO qa_db_report Loading subparser ctcs2::autotest_sleeptest...
2022-12-01 09:05:33 +0100 INFO qa_db_report Loading parser hazard...
2022-12-01 09:05:33 +0100 INFO qa_db_report Loading parser lsb...
2022-12-01 09:05:33 +0100 INFO qa_db_report Loading parser ooo...
2022-12-01 09:05:33 +0100 INFO qa_db_report Loading parser xfstests...
2022-12-01 09:05:33 +0100 INFO qa_db_report qadb settings (read from configuration files): host: dbproxy.suse.de, database: qadb, user: qadb_admin, password: ***undisclosed***
2022-12-01 09:05:33 +0100 INFO qa_db_report path:/tmp/fozzie-1-2022-12-01-03-05-18.tar.gz filter:<not defined>
2022-12-01 09:05:33 +0100 INFO qa_db_report type:product tester:hamsta-default verbosity:4 comment: Test result for virtualization host upgrade step 02 test: /usr/share/qa/tcf/test-VH-Upgrade-std-xen-sles12sp5-sles15sp5-02.tcf.
2022-12-01 09:05:33 +0100 INFO qa_db_report nomove:1 delete:1 nodb:0 noscp:0 batchmode:1
2022-12-01 09:05:33 +0100 INFO qa_db_report host:fozzie-1 kernel:4.12.14-122.139-default product:SLES-12-SP5 release:GM arch:xen0-x86_64 qam:0
2022-12-01 09:05:33 +0100 INFO qa_db_report set_user: Attempting to log in qadb_admin to database qadb on dbproxy.suse.de
2022-12-01 09:05:33 +0100 INFO qa_db_report Successfully logged qadb_admin into $dsn = DBI:mysql:qadb:dbproxy.suse.de
2022-12-01 09:05:33 +0100 INFO qa_db_report Using parser ctcs2...
2022-12-01 09:05:33 +0100 INFO qa_db_report Processing: VmInstall-16460-2022-12-01-01-19-36
2022-12-01 09:05:33 +0100 INFO qa_db_report Creating a new submission
2022-12-01 09:05:33 +0100 INFO qa_db_report Writing submission types for submission 3430363
Use of uninitialized value $parts[1] in pattern match (m//) at /usr/share/qa/tools/qa_db_report.pl line 686.
2022-12-01 09:05:34 +0100 INFO qa_db_report Processing: test-VH-Upgrade-std-xen-sles12sp5-sles15sp5-02-2022-12-01-01-16-01
2022-12-01 09:05:34 +0100 NOTICE qa_db_report I have submitted submissions 3430363 : product:SLES-12-SP5 release:GM arch:xen0-x86_64 hostfozzie-1 tester:hamsta-default
2022-12-01 09:05:34 +0100 NOTICE qa_db_report testcases:3 runs:3 succeeded:3 failed:0 interr:0 skipped:0 time:11059 bench:0
2022-12-01 09:05:34 +0100 INFO qa_db_report Going to store logs to the central archive via SCP
2022-12-01 09:05:36 +0100 INFO qa_db_report Submitted logs have been copied to the archive.
2022-12-01 09:05:36 +0100 INFO qa_db_report Submitted logs have been deleted
2022-12-01 09:05:36 +0100 INFO qa_db_report All done - results were submitted with following submission ID(s):
2022-12-01 09:05:36 +0100 INFO qa_db_report ID 3430363: http://qadb2.suse.de/qadb/submission.php?submission_id=3430363
- In order to reproduce the problem, run reproducers as below:
./reproducer-worker-machine &
Wait 5 seconds
(cat reproducer-sut-machine-part1 | tee -a /dev/sshserial; sleep 7200; cat reproducer-sut-machine-part2 | tee -a /dev/sshserial) &
After firing up above commands on worker and sut machine, the content of reproducer-sut-machine-part1 will show up on screens of both worker and sut machine, at the same time, 'serial0.txt' will also be updated with the same content. Both worker2 and grenahce-1 has the same result at this step.
Then wait for another 7200 seconds. When you successfully reproduce the problem for the first time by using these reproducers, you can lower the value a bit to try to reproduce with a lower value. At the moment, I can not tell the smallest value that can help reproduce the issue.
Now comes the most important step which shows the difference between worker2 and grenache-1. On grenache-1, the content of reproducer-sut-machine-part2 will show up on its screen and also the 'seria0.txt' file, but on worker2 its screen will not print out the content and 'serial0.txt' will not be updated. At the same time, on worker2
bash -c rm -f /dev/sshserial; mkfifo /dev/sshserial; chmod 666 /dev/sshserial; while true; do cat /dev/sshserial; donestill present or absent, but it will quit anyway at the last before time-out of reproducer-worker-machine (28800 seconds).These reproducers can reproduce the exact same original problem described in this ticket at the beginning. Reproducer reproducer-worker-machine contains all the exact same steps being used in openQA backend/console modules, mainly ssh connection setup and read/write. Reproducers reproducer-sut-machine-part1 nad reproducer-sut-machine-part2 are just text files that resemble the output from real test script
/usr/share/qa/tools/test-VH-Upgrade-std-xen-sles12sp5-sles15sp5-run 02, you can put any other texts in them as you want. So there are nothing special traffic involved in all these reproducers.What I stated in #120651#note-15 is still valid, this comment is the simplified version of #120651#note-15, so you can reproduce the problem without relying on openQA automation (just some scripts) which can help identify the root cause much easier.
From all the above work, it looks like the problem might not be related to traffic/port/rules. It is more likely that there is something wrong with the worker2 machine itself, for example, packages/drivers/library and etc. But as the main contact point of this ticket, I still respect your opinion if you come up with something more enlightening. I also have limited knowledge of firewall, there might be something hidden switch that I am not aware of.
Updated by mkittler over 2 years ago
Very nice that we can reproduce the issue now more easily.
It is more likely that there is something wrong with the worker2 machine itself, …
It worked on worker2 at some point, though. That means something must have change on worker2 (and not on grenache-1). I wouldn't know what that would be (and hence assumed it had something to do with the security zone move). However, I agree that it was very strange if it was related to traffic/port/rules as well considering it only breaks after waiting a certain amount of time and only SSH traffic is involved. If it was about traffic/port/rules I'd expect it to not work at all. Unfortunately nobody answered in the security zone discussion to shed more light on that aspect.
If there was a change on worker2, e.g. a package update, then it must be a change that didn't happen on grenache-1. That would be a x86_64 specific update/problem then.
About the reproducer:
- I'm wondering whether it reproduces the issue as well when setting the timeout in line
my $ssh = Net::SSH2->new(timeout => (300 // 5 * 3600) * 1000);to e.g. 0 (which would be infinity). - Maybe enabling debug output via https://metacpan.org/pod/Net::SSH2#trace1 gives more clues.
- I'm not sure what you mean with "At the same time, on worker2
bash -c rm -f /dev/sshserial; mkfifo /dev/sshserial; chmod 666 /dev/sshserial; while true; do cat /dev/sshserial; donestill present or absent, but …". Is the command still running on worker2 or not? Or do you want to say that this is not relevant?
Updated by waynechen55 over 2 years ago
mkittler wrote:
- I'm not sure what you mean with "At the same time, on worker2
bash -c rm -f /dev/sshserial; mkfifo /dev/sshserial; chmod 666 /dev/sshserial; while true; do cat /dev/sshserial; donestill present or absent, but …". Is the command still running on worker2 or not? Or do you want to say that this is not relevant?
When the original issue was reproduced and at the same time, the reproducer-worker-machine was still running, the command bash -c rm -f /dev/sshserial; mkfifo /dev/sshserial; chmod 666 /dev/sshserial might be still present or already absent. But it will definitely quit much earlier before reproducer-worker-machine which will end after 28800 seconds.
Updated by waynechen55 over 2 years ago
mkittler wrote:
- I'm wondering whether it reproduces the issue as well when setting the timeout in line
my $ssh = Net::SSH2->new(timeout => (300 // 5 * 3600) * 1000);to e.g. 0 (which would be infinity).- Maybe enabling debug output via https://metacpan.org/pod/Net::SSH2#trace1 gives more clues.
I think you can have a try. Currently all critical lines in reproducer-worker-machine are copied over from openQA console/backend modules without modifications.
Updated by okurz over 2 years ago
- Subject changed from [openQA][infra][ipmi][worker][api] The expected pattenr CMD_FINISHED-xxxxx returned but did not show up in serial log (wait_serial timed out) size:M to [openQA][infra][ipmi][worker][api] The expected pattern CMD_FINISHED-xxxxx returned but did not show up in serial log (wait_serial timed out)
- Assignee set to okurz
After discussion in weekly SUSE QE Tools meeting 2022-12-09 I am removing estimate. Seems like we don't even know how to reproduce the original problem or check if the problem is resolved
@waynechen55 due to absence and more limited capacity in our team I don't think we can look into the investigation ourselves more urgently. What help can we offer you so that you can better investigate yourself?
Please also update the original ticket description with at best a "link to latest" pointing to a scenario that reproduces the error even if it's just a sporadic issue and not always happening.
Updated by okurz over 2 years ago
- Due date set to 2022-12-23
- Status changed from Workable to Feedback
- Priority changed from Urgent to High
Updated by waynechen55 over 2 years ago
okurz wrote:
After discussion in weekly SUSE QE Tools meeting 2022-12-09 I am removing estimate. Seems like we don't even know how to reproduce the original problem or check if the problem is resolved
@waynechen55 due to absence and more limited capacity in our team I don't think we can look into the investigation ourselves more urgently. What help can we offer you so that you can better investigate yourself?
Please also update the original ticket description with at best a "link to latest" pointing to a scenario that reproduces the error even if it's just a sporadic issue and not always happening.
I can only help reproduce the problem in the future to confirm whether the issue is gone or not. But I do not think I can solve the problem from what I have known till now.
Updated by mkittler over 2 years ago
- Tags changed from reactive work, infra to reactive work
- Assignee deleted (
okurz) - Priority changed from High to Urgent
Seems like we don't even know how to reproduce the original problem or check if the problem is resolved
We have instructions to reproduce the problem without even running an openQA test. However, that would only help to verify whether the issue is gone after an attempt to fix it. The next step is finding the root cause and to fix the problem. Then we can run the reproducer again to verify the fix.
Please also update the original ticket description with at best a "link to latest" pointing to a scenario that reproduces the error even if it's just a sporadic issue and not always happening.
It is not sporadic. The relevant worker slots have been effectively disabled on worker2 so there are currently no jobs that would show the issue (see https://gitlab.suse.de/openqa/salt-pillars-openqa/-/merge_requests/465). Note that we currently rely on grenache-1 to run those jobs. So we must not move that worker to the new security zone until this issue is fixed.
Updated by mkittler over 2 years ago
- Tags changed from reactive work to reactive work, infra
- Assignee set to okurz
- Priority changed from Urgent to High
Updated by okurz over 2 years ago
- Due date changed from 2022-12-23 to 2023-01-27
- Priority changed from High to Normal
mkittler wrote:
Seems like we don't even know how to reproduce the original problem or check if the problem is resolved
We have instructions to reproduce the problem without even running an openQA test.
mkittler can you please to update the section "Steps to reproduce" to include this?
Updated by mkittler over 2 years ago
- Description updated (diff)
I've been adding a link to the relevant comment and also adjusted the existing steps to reproduce (due to https://gitlab.suse.de/openqa/salt-pillars-openqa/-/merge_requests/465).
Updated by okurz over 2 years ago
@mkittler the "steps to reproduce" are unfortunately too complicated that we could easily ask someone else, e.g. EngInfra, to run to find out where there might be a problem under their control
@wayenchen55 I suggest you put the reproducer from #120651#note-45 into something that people from SUSE-IT EngInfra can run by a single one-line-command onto worker setups, e.g. just put it into /usr/local/bin/ on worker2 with the right settings and credentials and then ask people from EngInfra to run it to see a problem.
There is still a chance that something is special about the worker but also then we should try to pinpoint at best using standard networking debugging tools, e.g. ping, nmap, mtr, etc.
Just running a simple mtr -r -c 20 openqaw9-hyperv.qa.suse.de I see a non-negligible packet loss:
HOST: worker2 Loss% Snt Last Avg Best Wrst StDev
1.|-- gateway.oqa.suse.de 5.0% 20 0.4 0.3 0.1 0.5 0.1
2.|-- 10.136.0.5 10.0% 20 1.0 0.9 0.6 1.3 0.2
3.|-- 10.162.2.106 5.0% 20 0.6 0.5 0.3 0.8 0.2
in comparison to grenache-1.qa.suse.de:
HOST: grenache-1 Loss% Snt Last Avg Best Wrst StDev
1.|-- 10.162.2.106 0.0% 20 0.3 0.3 0.3 0.7 0.1
For this specific case I created https://sd.suse.com/servicedesk/customer/portal/1/SD-107791
@mkittler what can we do to make the operation in os-autoinst more resilient, like timeout and retry without the wait_serial calls specific for the backend?
Updated by okurz over 2 years ago
- Related to action #119446: Conduct the migration of SUSE openQA+QA systems from Nbg SRV2 to new security zones added
Updated by waynechen55 over 2 years ago
Now all reproducers in /home/waynechen/bin on worker2 machine (I can not move them to any other privileged directory). They can run them as per #120651#note-45. The sut machine to be used is AMD Zen3, so please it would be better to do investigation and debug when there is no test build running.
Updated by okurz about 2 years ago
- Related to action #122302: Support SD-105827 "PowerPC often fails to boot from network with 'error: time out opening'" added
Updated by livdywan about 2 years ago
- Subject changed from [openQA][infra][ipmi][worker][api] The expected pattern CMD_FINISHED-xxxxx returned but did not show up in serial log (wait_serial timed out) to [openQA][infra][ipmi][worker][api] The expected pattern CMD_FINISHED-xxxxx returned but did not show up in serial log (wait_serial timed out) size:M
- Description updated (diff)
Updated by mkittler about 2 years ago
what can we do to make the operation in os-autoinst more resilient, like timeout and retry without the wait_serial calls specific for the backend?
This code is using somemkfifo magic I'm not familiar with. Supposedly we need to remove and recreate that in case of a retry attempt and only then try to re-establish the SSH connection. Of course that might be a bit tricky because the mkfifo command needs to be executed in the SUT and the SUT's state is likely not clear when the re-try would have to happen.
Updated by waynechen55 about 2 years ago
mkittler wrote:
what can we do to make the operation in os-autoinst more resilient, like timeout and retry without the wait_serial calls specific for the backend?
This code is using some
mkfifomagic I'm not familiar with. Supposedly we need to remove and recreate that in case of a retry attempt and only then try to re-establish the SSH connection. Of course that might be a bit tricky because themkfifocommand needs to be executed in the SUT and the SUT's state is likely not clear when the re-try would have to happen.
Here is the manpage for mkfifo.
Updated by okurz about 2 years ago
We discussed this topic in detail yesterday in the SUSE QE Tools unblock meeting 2023-01-18. Certainly the root cause for problems is that the network stability decreased and with a migration of hosts certain ports or services are still blocked. This is why I created https://sd.suse.com/servicedesk/customer/portal/1/SD-107791 . In the meantime the blocked ports should be handled and also the network stability has improved. For example I could not observe any significant packet loss when communicating between any OSD and openqaw9-hyperv.qa.suse.de.
Following https://openqa.suse.de/tests/latest?arch=x86_64&distri=sle&flavor=Online&machine=64bit-ipmi-large-mem&test=prj2_host_upgrade_sles12sp5_to_developing_xen&version=15-SP5 I could not find a more recent test result. The latest result in that scenario is already two months old.
@waynechen55 Can you reference more recent test results? Do they reproduce the problem or can you try to explicitly schedule tests on worker2 (and not grenache-1) to crosscheck?
In general we must acknowledge that the SLE virtualization tests have very strict requirements on the stability of the network which can not easily be fulfilled. The test runtime is multiple hours and the situation of having no packet loss which would lead to a connection abort is unlikely. So we really did not come to an idea how any backend behaviour could be improved.
@waynechen55 If you have a good idea then you can build in a "retry" behaviour in the code executing if necessary the complete test case again but handled within one run of an openQA job. The only next best approach is if openQA itself would retrigger the test after that which would be less efficient.
Updated by okurz about 2 years ago
- Due date deleted (
2023-01-27) - Status changed from Feedback to New
- Assignee deleted (
okurz) - Priority changed from Normal to Low
- Target version changed from Ready to future
Ok, good to hear. As unfortunately there are no concrete steps of what we can do within the tools team I will keep the ticket open but remove from the backlog
Updated by waynechen55 about 2 years ago
I can say very confidently that the issue still persists. The steps to reproduce and the issue itself is identical to #120651#note-45. The SUT machine being used for reproducing the issue is quinn. So at the moment, these workers should continue to stay with grenache-1. Moving them to worker2 will make many openQA test run impossible.
Additionally, if fixing on firewall/network side can not help solve the problem, can we try the same method used for #113528 ? I am not very sure what had been done in https://sd.suse.com/servicedesk/customer/portal/1/SD-92689 for #113528. Do you think it can also help solve this issue in this ticket ?
Updated by okurz about 2 years ago
- Blocks deleted (action #120270: Conduct the migration of SUSE openQA systems IPMI from Nbg SRV1 to new security zones size:M)
Updated by okurz about 2 years ago
- Related to action #120270: Conduct the migration of SUSE openQA systems IPMI from Nbg SRV1 to new security zones size:M added
Updated by okurz about 2 years ago
- Target version changed from future to Ready
waynechen55 wrote:
I can say very confidently that the issue still persists. The steps to reproduce and the issue itself is identical to #120651#note-45. The SUT machine being used for reproducing the issue is quinn. So at the moment, these workers should continue to stay with grenache-1. Moving them to worker2 will make many openQA test run impossible.
Understood and agreed. This is why we consider #119446 to be blocked by this ticket here. Adding this ticket to the backlog now.
Additionally, if fixing on firewall/network side can not help solve the problem, can we try the same method used for #113528 ? I am not very sure what had been done in https://sd.suse.com/servicedesk/customer/portal/1/SD-92689 for #113528. Do you think it can also help solve this issue in this ticket ?
I don't see any actual fixes or changes done in https://sd.suse.com/servicedesk/customer/portal/1/SD-92689 yet. I see only not-intrusive monitoring and investigation. Do you mean a specific change or fix attempt?
Updated by waynechen55 about 2 years ago
okurz wrote:
waynechen55 wrote:
I can say very confidently that the issue still persists. The steps to reproduce and the issue itself is identical to #120651#note-45. The SUT machine being used for reproducing the issue is quinn. So at the moment, these workers should continue to stay with grenache-1. Moving them to worker2 will make many openQA test run impossible.
Understood and agreed. This is why we consider #119446 to be blocked by this ticket here. Adding this ticket to the backlog now.
Additionally, if fixing on firewall/network side can not help solve the problem, can we try the same method used for #113528 ? I am not very sure what had been done in https://sd.suse.com/servicedesk/customer/portal/1/SD-92689 for #113528. Do you think it can also help solve this issue in this ticket ?
I don't see any actual fixes or changes done in https://sd.suse.com/servicedesk/customer/portal/1/SD-92689 yet. I see only not-intrusive monitoring and investigation. Do you mean a specific change or fix attempt?
I am fine if you think what solved problem in #113528 can not help here. And feel free to provide further information about this issue. I think I personally can help do some further investigation by adding more debugging code into reproducer-worker-machine. But this will take a period time, because I need to do this a step further a time and also need proper time slot.
Updated by okurz about 2 years ago
- Target version changed from Ready to future
waynechen55 wrote:
[…] I think I personally can help do some further investigation by adding more debugging code into reproducer-worker-machine. But this will take a period time, because I need to do this a step further a time and also need proper time slot.
ok, good. Whenever you find the time and find out something new please let us know in this ticket. In the meantime we do not plan to look further into this issue as do we don't have an easy handle. Eventually the situation will change again with new network zones and new datacenter locations which will come and we won't be able to wait for this issue to be resolved before that migration is conducted.
Updated by waynechen55 about 2 years ago
I tried again by setting timeout to 0 explicitly, which does not help. The result is still the same as #120651#note-68
my $ssh = Net::SSH2->new(timeout => 0);
Updated by nicksinger about 2 years ago
please note that I removed the test instance on worker2 and migrated your test worker class to grenache1:13
See https://gitlab.suse.de/openqa/salt-pillars-openqa/-/merge_requests/506 for details
Updated by waynechen55 about 2 years ago
nicksinger wrote:
please note that I removed the test instance on worker2 and migrated your test worker class to grenache1:13
See https://gitlab.suse.de/openqa/salt-pillars-openqa/-/merge_requests/506 for details
No problem. I am looking into the problem by using perl scripts on worker machine directly.
Updated by waynechen55 about 2 years ago
- I made a workaround to this problem which works. In order to make it work:
Run this on worker machine:
./reproducer-worker-machine &
Wait 5 seconds
Run this on SUT machine:
(cat reproducer-sut-machine-part1 | tee -a /dev/sshserial; sleep 7200; cat reproducer-sut-machine-part2 | tee -a /dev/sshserial) &
Then
(for i in `seq 1 150`;do echo -e "test\n" > /dev/sshserial;sleep 60;done) &
So the difference is
(for i in `seq 1 150`;do echo -e "test\n" > /dev/sshserial;sleep 60;done) & which always tries to keep the connection alive proactively. So after 7200s, output from cat reproducer-sut-machine-part2 | tee -a /dev/sshserial can be shown up on screen and serial0.txt on worker machine.
- Back to the test itself, I think for any test needs longer wait time, it needs to be put in a active loop instead of on idle. For example, use
script_run(xxx)to keep alive. - But all the above just workaround, I think the backend side needs to be enhanced further by employing Net::SSH2 subroutines to track connection and keep it alive proactively. This is not a network issue, nothing in the way of ssh connection, ssh connection is always intact. But it looks like something does not work perfectly, maybe either side or an element in between just drops the connection in certain way or worker machine itself behaves badly.
- I tried to fix the issue by using
Net::SSH2::keepalive_config(1, 60)to send/receive heartbeat messages periodically, but there is no success. Perl scrip with this subroutine added in always fails. It keeps telling me:no libssh2 error registered at ./reproducer-worker-machine line xxx. The code snippet is as below:
#!/usr/bin/perl
use Net::SSH2;
my $ssh = Net::SSH2->new(timeout => (300 // 5 * 3600) * 1000);
my $counter = 5;
my $con_pretty = "root\@sut-machine";
while ($counter > 0) {
if ($ssh->connect('sut-machine', 22)) {
$ssh->auth(username => 'xxxxx', password => 'xxxxx');
print "SSH connection to $con_pretty established" if $ssh->auth_ok;
last;
}
else {
print "Could not connect to $con_pretty, Retrying after some seconds...";
sleep(10);
$counter--;
next;
}
}
**$ssh->keepalive_config(1, 60) or $ssh->die_with_error;**
my $chan = $ssh->channel() or $ssh->die_with_error;
$chan->blocking(0);
$chan->pty(1);
$chan->ext_data('merge');
$ssh->blocking(1);
if (!$chan->exec('rm -f /dev/sshserial; mkfifo /dev/sshserial; chmod 666 /dev/sshserial; while true; do cat /dev/sshserial; done')) {
print "Can not grab serial console";
}
$ssh->blocking(0);
my $buffer;
my $start_time = time();
while (1) {
while (defined(my $bytes_read = $chan->read($buffer, 4096))) {
return 1 unless $bytes_read > 0;
print $buffer;
open(my $serial, '>>', 'serial0.txt');
print $serial $buffer;
close($serial);
}
last if (time() - $start_time > 28800);
}
I think there is work can be done on backend side to enhance the ssh2/channel behavior control.
Updated by MDoucha about 2 years ago
...or you could switch the tests to SSH serial terminal which is faster and more reliable:
https://openqa.suse.de/tests/10754703
Code changes: https://github.com/mdoucha/os-autoinst-distri-opensuse/commit/cda9e7aab94b66f0ee1594914232f57464d0f8f2
Updated by waynechen55 about 2 years ago
MDoucha wrote:
...or you could switch the tests to SSH serial terminal which is faster and more reliable:
https://openqa.suse.de/tests/10754703
Code changes: https://github.com/mdoucha/os-autoinst-distri-opensuse/commit/cda9e7aab94b66f0ee1594914232f57464d0f8f2
- I think $ssh->keepalive_config(1, 60) can solve the issue on backend side completely, not just for certain tests. I think such fix can help better control the ssh connection behavior.
- Actually, we already do so like this https://github.com/os-autoinst/os-autoinst/blob/fd12334c8619798e8fa3453c9e63bc8aebb545a1/consoles/localXvnc.pm#L25. I think this can help solve some problems.
- But for /dev/sshserial, the ssh connection is established the other way. So using $ssh->keepalive_config(1, 60) is an option to achieve the same effect.
- At the moment, this pull request is trying to solve the problem a bit https://github.com/os-autoinst/os-autoinst-distri-opensuse/pull/16696 by using set_ssh_console_timeout_before_use.
- Generally speaking, I think fixing on connection level is better than on test level unless there is obvious defect from my perspective.