coordination #110458
opencoordination #112862: [saga][epic] Future ideas for easy multi-machine handling: MM-tests as first-class citizens
[epic] Improve `RETRY=…`-behavior for jobs with dependencies
0%
Description
Observation¶
Jobs with RETRY=… setting are automatically restarted in case of a failure but apparently the dependency handling is not done in accordance with the normal restart behavior (you would get when e.g. clicking on the restart button in the web UI).
For instance, here the root job has been restarted multiple times but none of the children have been restarted: https://openqa.suse.de/tests/8656146#dependencies
This also leads to a not so nice graph where the multiple clones of the root job are present at the same time:
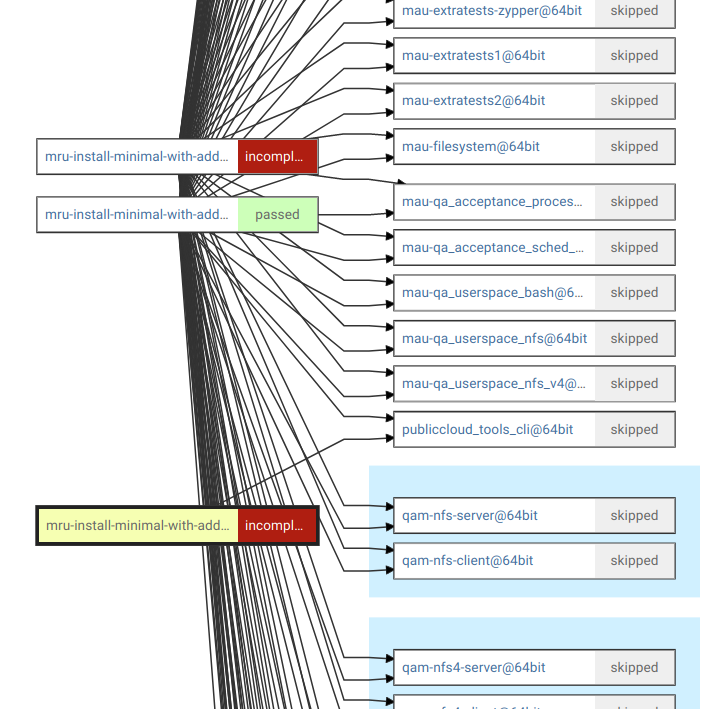
Acceptance criteria¶
- AC1: Jobs are restarted in a more sensible way¹ regarding dependencies. Likely there's not one best way but the default should at least work better in most cases.
- AC2: Potential concurrency issues which might be the culprit (or at least contribute to the overall problem) here are investigated and dealt with if needed (see #110458#note-4 for further details).
¹ What "more sensible" means exactly we have still have to define for each dependency type. Maybe it makes most sense to go with the behavior the restart API has by default.
Further ideas¶
- Allow the user to specify the retry behavior, similar to how it is already possible with the different parameters the restart API supports.
Files
{kind=link}
{kind=link}
Updated by okurz about 3 years ago
- Subject changed from Improve `RETRY=…`-behavior for jobs with dependencies to [epic] Improve `RETRY=…`-behavior for jobs with dependencies
- Priority changed from Normal to Low
- Target version set to future
Updated by mkittler almost 3 years ago
- Related to action #112256: Some children of parent job not cancelled (or later, restarted) when parent `parallel_failed` due to another child's parallel job failing added
Updated by okurz almost 3 years ago
- Parent task changed from #103962 to #112862
Move future ideas to the actual "Future ideas" tracker #112862
Updated by mkittler almost 3 years ago
The symptoms of this problem can be hard to pin down but I suppose this is another example of this issue: https://suse.slack.com/archives/C02CANHLANP/p1661763124213709
I suppose one problem is that auto_duplicate is invoked around the same time for multiple incompletes of the same parallel cluster.
After having a closer look at the code, I'm not sure whether it is buggy. Here are my thoughts:
- The code for creating clones is using a transaction but not using an isolation level that would prevent it from seeing changes committed by other transactions. Therefore I'm not sure whether the code handles this situation well.
- At least the upfront check whether there's already an existing clone can definitely not work in all situations.
- So the algorithm for determining the cluster jobs might run at some point in the middle on a cluster that has already been restarted.
- The same counts for the code that actually creates the clones and inserts dependencies.
- However, the code does some "optimistic" locking. So in case a job we want to clone "suddenly" already has a clone we abort the transaction. I'm not sure whether this kind of locking is enough, though. E.g. what would happen if:
- Process A creates a bunch of closes but hasn't committed the changes yet.
- Process B creates the same clones. Since A hasn't committed its changes yet, B will not be prevented to do so as our optimistic locking code will not even see changes from A.
- One of the processes commits first. I suppose that should succeed.
- The other process commits the changes as well. I'm not sure how it'll be handled by PostgreSQL. Either:
- It fails discarding all changes. That would be good for us because then it'll be like we only attempted to create the clones once which is what we want.
- It succeeds, partially overriding changes from the faster transaction. That would leave jobs from the faster transaction dangling. They'd not be considered clones of anything anymore (like the jobs we found today on OSD). And besides, we'd have surplus sets of jobs. Maybe the dependency creation is screwed with as well (like in the jobs we found today on OSD).
It would be interesting to check which of the options in the last point it is.
Note that looking at the timestamps supports the theory that the job cloning was done concurrently because the creation times of the jobs from the relevant "sets restarted jobs" are interleaving:
openqa=# select id, clone_id, (select id from jobs as j2 where clone_id = jobs.id) as cloned_as_id, (select count(*) from job_dependencies where parent_job_id = jobs.id or child_job_id = jobs.id) as direct_dependency_count, t_created, result from jobs where id in (9399731, 9401905, 9401919, 9401927, 9401918, 9401926, 9401944, 9401969, 9401980) order by t_created;
id | clone_id | cloned_as_id | direct_dependency_count | t_created | result
---------+----------+--------------+-------------------------+---------------------+------------------
9399731 | 9401905 | | 3 | 2022-08-27 20:33:32 | incomplete # original job, obviously the first
9401905 | | 9399731 | 3 | 2022-08-28 01:36:36 | passed # one job of the "well" restarted cluster
9401918 | 9402853 | | 0 | 2022-08-28 01:36:36 | timeout_exceeded # one of the dangling jobs that ended up without dependencies and clone-relation
9401919 | | 9399733 | 1 | 2022-08-28 01:36:36 | passed # one job of the "well" restarted cluster
9401926 | 9402854 | | 0 | 2022-08-28 01:36:37 | timeout_exceeded # one of the dangling jobs that ended up without dependencies and clone-relation
9401927 | | 9399734 | 1 | 2022-08-28 01:36:37 | passed # one job of the "well" restarted cluster
9401944 | 9402855 | | 0 | 2022-08-28 01:36:38 | timeout_exceeded # one of the dangling jobs that ended up without dependencies and clone-relation
9401969 | 9402856 | | 0 | 2022-08-28 01:36:39 | timeout_exceeded # one of the dangling jobs that ended up without dependencies and clone-relation
9401980 | 9402857 | | 0 | 2022-08-28 01:36:40 | timeout_exceeded # one of the dangling jobs that ended up without dependencies and clone-relation
(9 Zeilen)
Updated by mkittler almost 3 years ago
Note that if concurrent cloning/restarting is indeed not handled well that means this bug is actually not really specific to the RETRY=…-feature. It would theoretically also happen if a user manages to click the restart buttons of multiple jobs in the cluster simultaneously but that's of course very unlikely to happen.
Updated by kraih almost 3 years ago
- The code for creating clones is using a transaction but not using an isolation level that would prevent it from seeing changes committed by other transactions. Therefore I'm not sure whether the code handles this situation well.
- At least the upfront check whether there's already an existing clone can definitely not work in all situations.
- So the algorithm for determining the cluster jobs might run at some point in the middle on a cluster that has already been restarted.
- The same counts for the code that actually creates the clones and inserts dependencies.
- However, the code does some "optimistic" locking. So in case a job we want to clone "suddenly" already has a clone we abort the transaction. I'm not sure whether this kind of locking is enough, though. E.g. what would happen if:
- Process A creates a bunch of closes but hasn't committed the changes yet.
- Process B creates the same clones. Since A hasn't committed its changes yet, B will not be prevented to do so as our optimistic locking code will not even see changes from A.
- One of the processes commits first. I suppose that should succeed.
- The other process commits the changes as well. I'm not sure how it'll be handled by PostgreSQL. Either:
- It fails discarding all changes. That would be good for us because then it'll be like we only attempted to create the clones once which is what we want.
- It succeeds, partially overriding changes from the faster transaction. That would leave jobs from the faster transaction dangling. They'd not be considered clones of anything anymore (like the jobs we found today on OSD). And besides, we'd have surplus sets of jobs. Maybe the dependency creation is screwed with as well (like in the jobs we found today on OSD).
I've not looked at the code, but to me it sounds like both transactions should succeed and create clones, unless the data from the second transaction actually conflicts with the data from the first transaction (unique constraints on the table, or similar). And if there's a conflict the thrown exception should result in a full rollback of the whole transaction, which doesn't appear to be the case here. Perhaps a SELECT FOR UPDATE would be useful here to make sure the second transaction gets blocked early enough by the first one.
Updated by mkittler almost 3 years ago
Thanks. Maybe SELECT FOR UPDATE would be helpful, indeed. It is even supported by DBIx::Class (see https://metacpan.org/pod/DBIx::Class::ResultSet#for).
Updated by dzedro over 2 years ago
This are failures where supportserver was cloned without his dependencies since 2022-09-05.
I removed RETRY from HA group for now, it's getting too crazy.
id | test | distri | version | result
---------+------------------------------------------------+--------+---------+------------------
9555308 | qam_alpha_supportserver | sle | 15-SP4 | timeout_exceeded
9555307 | qam_alpha_supportserver | sle | 15-SP4 | timeout_exceeded
9555305 | qam_alpha_supportserver | sle | 15-SP4 | timeout_exceeded
9555304 | qam_alpha_supportserver | sle | 15-SP4 | timeout_exceeded
9555284 | qam_alpha_supportserver | sle | 15-SP4 | timeout_exceeded
9555277 | qam_alpha_supportserver | sle | 15-SP3 | timeout_exceeded
9555275 | qam_alpha_supportserver | sle | 15-SP3 | timeout_exceeded
9555274 | ha_supportserver_qdevice | sle | 15-SP3 | timeout_exceeded
9555273 | ha_supportserver_qdevice | sle | 15-SP3 | timeout_exceeded
9555272 | qam_alpha_supportserver | sle | 15-SP3 | timeout_exceeded
9555271 | ha_supportserver_qdevice | sle | 15-SP3 | timeout_exceeded
9555270 | qam_alpha_supportserver | sle | 15-SP3 | timeout_exceeded
9555269 | ha_supportserver_qdevice | sle | 15-SP3 | timeout_exceeded
9555268 | ha_supportserver_qdevice | sle | 15-SP3 | timeout_exceeded
9555265 | ha_supportserver_qdevice | sle | 15-SP3 | timeout_exceeded
9555264 | qam_alpha_supportserver | sle | 15-SP3 | timeout_exceeded
9555263 | ha_supportserver_qdevice | sle | 15-SP3 | timeout_exceeded
9555262 | ha_supportserver_qdevice | sle | 15-SP2 | timeout_exceeded
9555261 | ha_supportserver_qdevice | sle | 15-SP2 | timeout_exceeded
9555260 | ha_supportserver_qdevice | sle | 15-SP2 | timeout_exceeded
9555182 | ha_supportserver_qdevice | sle | 15-SP2 | timeout_exceeded
9555181 | ha_supportserver_qdevice | sle | 15-SP2 | timeout_exceeded
9555180 | ha_supportserver_qdevice | sle | 15-SP2 | timeout_exceeded
9555169 | ha_supportserver_qdevice | sle | 15-SP2 | timeout_exceeded
9555142 | qam_alpha_supportserver | sle | 15-SP1 | timeout_exceeded
9555133 | qam_alpha_supportserver | sle | 15-SP1 | timeout_exceeded
9555128 | ha_supportserver_qdevice | sle | 15-SP1 | timeout_exceeded
9555127 | qam_alpha_supportserver | sle | 15-SP1 | timeout_exceeded
9555126 | ha_supportserver_qdevice | sle | 15-SP1 | timeout_exceeded
9555125 | ha_supportserver_qdevice | sle | 15-SP1 | timeout_exceeded
9555124 | qam_alpha_supportserver | sle | 15-SP1 | timeout_exceeded
9555123 | ha_supportserver_qdevice | sle | 15-SP1 | timeout_exceeded
9555121 | ha_supportserver_qdevice | sle | 15-SP1 | timeout_exceeded
9555120 | ha_supportserver_qdevice | sle | 15-SP1 | timeout_exceeded
9555119 | ha_supportserver_qdevice | sle | 15-SP1 | timeout_exceeded
9555118 | qam_alpha_supportserver | sle | 15-SP1 | timeout_exceeded
9554849 | qam_alpha_supportserver | sle | 12-SP5 | timeout_exceeded
9554848 | qam_alpha_supportserver | sle | 12-SP5 | timeout_exceeded
9554847 | qam_alpha_supportserver | sle | 12-SP5 | timeout_exceeded
9554846 | qam_alpha_supportserver | sle | 12-SP5 | timeout_exceeded
9554845 | qam_alpha_supportserver | sle | 12-SP5 | timeout_exceeded
9554844 | qam_alpha_supportserver | sle | 12-SP4 | timeout_exceeded
9554843 | qam_alpha_supportserver | sle | 12-SP4 | timeout_exceeded
9554842 | qam_alpha_supportserver | sle | 12-SP4 | timeout_exceeded
9554841 | qam_alpha_supportserver | sle | 12-SP4 | timeout_exceeded
9554840 | qam_alpha_supportserver | sle | 12-SP4 | timeout_exceeded
9553743 | qam_alpha_supportserver | sle | 15-SP4 | timeout_exceeded
9553742 | qam_alpha_supportserver | sle | 15-SP4 | timeout_exceeded
9553741 | qam_alpha_supportserver | sle | 15-SP4 | timeout_exceeded
9553740 | qam_alpha_supportserver | sle | 15-SP4 | timeout_exceeded
9553735 | qam_alpha_supportserver | sle | 15-SP4 | timeout_exceeded
9553727 | qam_alpha_supportserver | sle | 15-SP3 | timeout_exceeded
9553726 | qam_alpha_supportserver | sle | 15-SP3 | timeout_exceeded
9553725 | qam_alpha_supportserver | sle | 15-SP3 | timeout_exceeded
9553724 | qam_alpha_supportserver | sle | 15-SP3 | timeout_exceeded
9553723 | ha_supportserver_qdevice | sle | 15-SP3 | timeout_exceeded
9553722 | ha_supportserver_qdevice | sle | 15-SP3 | timeout_exceeded
9553721 | ha_supportserver_qdevice | sle | 15-SP3 | timeout_exceeded
9553720 | ha_supportserver_qdevice | sle | 15-SP3 | timeout_exceeded
9553719 | ha_supportserver_qdevice | sle | 15-SP3 | timeout_exceeded
9553718 | ha_supportserver_qdevice | sle | 15-SP3 | timeout_exceeded
9553717 | qam_alpha_supportserver | sle | 15-SP3 | timeout_exceeded
9553713 | ha_supportserver_qdevice | sle | 15-SP3 | timeout_exceeded
9553708 | ha_supportserver_qdevice | sle | 15-SP2 | timeout_exceeded
9553707 | ha_supportserver_qdevice | sle | 15-SP2 | timeout_exceeded
9553706 | ha_supportserver_qdevice | sle | 15-SP2 | timeout_exceeded
9553705 | ha_supportserver_qdevice | sle | 15-SP2 | timeout_exceeded
9553704 | ha_supportserver_qdevice | sle | 15-SP2 | timeout_exceeded
9553703 | ha_supportserver_qdevice | sle | 15-SP2 | timeout_exceeded
9553702 | ha_supportserver_qdevice | sle | 15-SP2 | timeout_exceeded
9553697 | qam_alpha_supportserver | sle | 15-SP1 | timeout_exceeded
9553696 | qam_alpha_supportserver | sle | 15-SP1 | timeout_exceeded
9553695 | qam_alpha_supportserver | sle | 15-SP1 | timeout_exceeded
9553694 | qam_alpha_supportserver | sle | 15-SP1 | timeout_exceeded
9553693 | ha_supportserver_qdevice | sle | 15-SP1 | timeout_exceeded
9553692 | ha_supportserver_qdevice | sle | 15-SP1 | timeout_exceeded
9553691 | ha_supportserver_qdevice | sle | 15-SP1 | timeout_exceeded
9553690 | ha_supportserver_qdevice | sle | 15-SP1 | timeout_exceeded
9553689 | ha_supportserver_qdevice | sle | 15-SP1 | timeout_exceeded
9553688 | ha_supportserver_qdevice | sle | 15-SP1 | timeout_exceeded
9553687 | qam_alpha_supportserver | sle | 15-SP1 | timeout_exceeded
9553683 | ha_supportserver_qdevice | sle | 15-SP1 | timeout_exceeded
9553670 | qam_alpha_supportserver | sle | 12-SP5 | timeout_exceeded
9553669 | qam_alpha_supportserver | sle | 12-SP5 | timeout_exceeded
9553668 | qam_alpha_supportserver | sle | 12-SP5 | timeout_exceeded
9553667 | qam_alpha_supportserver | sle | 12-SP5 | timeout_exceeded
9553666 | qam_alpha_supportserver | sle | 12-SP5 | timeout_exceeded
9553662 | qam_alpha_supportserver | sle | 12-SP4 | timeout_exceeded
9553661 | qam_alpha_supportserver | sle | 12-SP4 | timeout_exceeded
9553660 | qam_alpha_supportserver | sle | 12-SP4 | timeout_exceeded
9553659 | qam_alpha_supportserver | sle | 12-SP4 | timeout_exceeded
9553658 | qam_alpha_supportserver | sle | 12-SP4 | timeout_exceeded
9553612 | ha_gamma_supportserver | sle | 15-SP3 | timeout_exceeded
9553611 | ha_gamma_supportserver | sle | 15-SP3 | timeout_exceeded
9553610 | ha_gamma_supportserver | sle | 15-SP3 | timeout_exceeded
9550099 | ha_supportserver_qdevice | sle | 15-SP4 | timeout_exceeded
9550098 | qam_alpha_supportserver | sle | 15-SP3 | timeout_exceeded
9549672 | qam_alpha_supportserver | sle | 15 | timeout_exceeded
9547335 | qam_alpha_supportserver | sle | 12-SP5 | timeout_exceeded
9547203 | ha_supportserver_qdevice | sle | 15 | timeout_exceeded
9547199 | qam_alpha_supportserver | sle | 12-SP5 | timeout_exceeded
9547189 | ha_supportserver_qdevice | sle | 15 | timeout_exceeded
9547181 | qam_alpha_supportserver | sle | 12-SP5 | timeout_exceeded
9547180 | qam_alpha_supportserver | sle | 12-SP5 | timeout_exceeded
9547163 | qam_alpha_supportserver | sle | 12-SP5 | timeout_exceeded
9547162 | ha_supportserver_qdevice | sle | 15-SP3 | timeout_exceeded
9547147 | qam_alpha_supportserver | sle | 15-SP4 | timeout_exceeded
9547144 | ha_supportserver_qdevice | sle | 15 | timeout_exceeded
9547139 | ha_supportserver_qdevice | sle | 15-SP3 | timeout_exceeded
9547130 | qam_alpha_supportserver | sle | 15-SP4 | timeout_exceeded
9547125 | ha_supportserver_qdevice | sle | 15-SP3 | timeout_exceeded
9547124 | qam_alpha_supportserver | sle | 15-SP4 | timeout_exceeded
9547121 | qam_alpha_supportserver | sle | 15-SP3 | timeout_exceeded
9547120 | ha_supportserver_qdevice | sle | 15-SP4 | timeout_exceeded
9547119 | qam_alpha_supportserver | sle | 15 | timeout_exceeded
9544918 | qam_alpha_supportserver | sle | 12-SP5 | timeout_exceeded
9544906 | qam_sles4sap_wmp_hana_supportserver | sle | 15-SP3 | timeout_exceeded
9544905 | ha_supportserver_qdevice | sle | 15 | timeout_exceeded
9544904 | qam_alpha_supportserver | sle | 12-SP5 | timeout_exceeded
9544903 | qam_sles4sap_wmp_hana_supportserver | sle | 15-SP3 | timeout_exceeded
9544897 | ha_supportserver_qdevice | sle | 15 | timeout_exceeded
9544882 | qam_alpha_supportserver | sle | 12-SP5 | timeout_exceeded
9544881 | qam_alpha_supportserver | sle | 12-SP5 | timeout_exceeded
9544878 | qam_sles4sap_wmp_hana_supportserver | sle | 15-SP3 | timeout_exceeded
9544874 | qam_alpha_supportserver | sle | 12-SP5 | timeout_exceeded
9544871 | ha_supportserver_qdevice | sle | 15-SP3 | timeout_exceeded
9544861 | qam_alpha_supportserver | sle | 15-SP4 | timeout_exceeded
9544858 | qam_sles4sap_wmp_hana_supportserver | sle | 15-SP2 | timeout_exceeded
9544857 | ha_supportserver_qdevice | sle | 15 | timeout_exceeded
9544856 | ha_supportserver_qdevice | sle | 15-SP3 | timeout_exceeded
9544845 | qam_alpha_supportserver | sle | 15-SP4 | timeout_exceeded
9544842 | ha_supportserver_qdevice | sle | 15-SP3 | timeout_exceeded
9544838 | qam_alpha_supportserver | sle | 15-SP4 | timeout_exceeded
9544831 | ha_supportserver_qdevice | sle | 15-SP4 | timeout_exceeded
9544829 | qam_alpha_supportserver | sle | 15-SP3 | timeout_exceeded
9544823 | qam_alpha_supportserver | sle | 15 | timeout_exceeded
9544820 | qam_sles4sap_wmp_hana_supportserver | sle | 15-SP4 | timeout_exceeded
9544804 | qam_sles4sap_wmp_hana_supportserver | sle | 15-SP4 | timeout_exceeded
9544750 | qam_sles4sap_wmp_hana_supportserver | sle | 15-SP4 | timeout_exceeded
9544746 | qam_sles4sap_wmp_hana_supportserver | sle | 15-SP3 | timeout_exceeded
9544740 | qam_sles4sap_wmp_hana_supportserver | sle | 15-SP3 | timeout_exceeded
9537900 | qam-sles4sap_hana_supportserver | sle | 15 | timeout_exceeded
9537897 | qam-sles4sap_hana_supportserver | sle | 15 | timeout_exceeded
9492983 | qam_sles4sap_wmp_hana_supportserver | sle | 15-SP4 | timeout_exceeded
9492951 | qam_sles4sap_wmp_hana_supportserver | sle | 15-SP3 | timeout_exceeded
9492931 | qam_sles4sap_wmp_hana_supportserver | sle | 15-SP3 | timeout_exceeded
9492930 | qam_sles4sap_wmp_hana_supportserver | sle | 15-SP3 | timeout_exceeded
9492146 | qam_kernel_multipath_supportserver_flaky | sle | 15-SP3 | timeout_exceeded
9491630 | qam_sles4sap_wmp_hana_supportserver | sle | 15-SP3 | timeout_exceeded
9491617 | qam_sles4sap_wmp_hana_supportserver | sle | 15-SP3 | timeout_exceeded
9491596 | qam_sles4sap_wmp_hana_supportserver | sle | 15-SP3 | timeout_exceeded
9491553 | qam_sles4sap_wmp_hana_supportserver | sle | 15-SP4 | timeout_exceeded
9491549 | qam_kernel_multipath_supportserver_flaky | sle | 15-SP3 | timeout_exceeded
9480878 | mru-install-multipath-remote_supportserver_dev | sle | 12-SP4 | timeout_exceeded
9480877 | mru-install-multipath-remote_supportserver_dev | sle | 15-SP1 | timeout_exceeded
9480694 | mru-install-multipath-remote_supportserver_dev | sle | 12-SP4 | timeout_exceeded
9480692 | mru-install-multipath-remote_supportserver_dev | sle | 15-SP1 | timeout_exceeded
9479788 | mru-install-multipath-remote_supportserver_dev | sle | 15 | timeout_exceeded
(158 rows)
Updated by dzedro over 2 years ago
RETRY is not the problem. I removed RETRY from HA job groups and it's still happening.
The jobs without dependencies have no record in audit log.
https://openqa.suse.de/tests/overview?build=%3A26117%3Awebkit2gtk3&version=15-SP1&distri=sle&groupid=236
Updated by emiura over 2 years ago
- Priority changed from Low to High
Problem now is that we have a lot of jobs scheduled without dependencies:
https://openqa.suse.de/tests/9620599
https://openqa.suse.de/tests/9622569
https://openqa.suse.de/tests/9620595
https://openqa.suse.de/tests/9620596
https://openqa.suse.de/tests/9620598
Updated by okurz over 2 years ago
Please report a separate issue otherwise this will be lost
Updated by mkittler over 2 years ago
I've checked out https://openqa.suse.de/tests/9620599 (and https://openqa.suse.de/tests/9620595 and https://openqa.suse.de/tests/9620596 and https://openqa.suse.de/tests/9620598) but the original job https://openqa.suse.de/tests/9604440 has not even dependencies. I'm wondering why you expect its restarted job to have dependencies. It is strange that this job has the START_AFTER_TEST setting but at the same time isn't scheduled as part of an ISO. Note that START_AFTER_TEST is only evaluated when scheduling an ISO. See https://open.qa/docs/#_spawning_single_new_jobs_jobs_post for the job setting to use when spawning single jobs.
I've also checked out https://openqa.suse.de/tests/9622569 and I'm not sure what's the problem. The whole chain of clones/restarts has dependencies.
Updated by dzedro over 2 years ago
mkittler wrote:
I've checked out https://openqa.suse.de/tests/9620599 (and https://openqa.suse.de/tests/9620595 and https://openqa.suse.de/tests/9620596 and https://openqa.suse.de/tests/9620598) but the original job https://openqa.suse.de/tests/9604440 has not even dependencies. I'm wondering why you expect its restarted job to have dependencies. It is strange that this job has the
START_AFTER_TESTsetting but at the same time isn't scheduled as part of an ISO. Note thatSTART_AFTER_TESTis only evaluated when scheduling an ISO. See https://open.qa/docs/#_spawning_single_new_jobs_jobs_post for the job setting to use when spawning single jobs.I've also checked out https://openqa.suse.de/tests/9622569 and I'm not sure what's the problem. The whole chain of clones/restarts has dependencies.
Man you must be joking ... there are no support_server jobs without dependencies, just for fun ...
What original job ? You don't mean the "origin job" without dependencies which was cloned or triggered by I don't know what RETRY or some other broken mechanism!
This is original e.g. https://openqa.suse.de/admin/productlog?id=984329 triggered by qa-maintenance-automation
@emiura should not add https://openqa.suse.de/tests/9622569, it's not related, I'm sure he copied it by mistake.
Updated by mkittler over 2 years ago
What original job ? You don't mean the "origin job" without dependencies which was cloned or triggered by I don't know what RETRY or some other broken mechanism!
I mean the job linked as "original job" and the job linked as "original job" there and so on. For instance the "original job" of https://openqa.suse.de/tests/9620599 would be https://openqa.suse.de/tests/9604440 and it has no dependencies.
I suppose the actual "original job" would be https://openqa.suse.de/tests/9604435#dependencies from the scheduled product you've linked. However, I'm not sure how it relates to the other jobs as it has not been restarted (which also makes sense considering it passed). In fact it is the restarted job itself (as it is the clone of https://openqa.suse.de/tests/9603287#comment-624131 and it was even restarted via RETRY). So that job shows that RETRY actually works. Supposedly the scheduled product was just an example (and not the best to show a problem).
Normally one can easily find the relevant scheduled product of the "original job" (as determined by my method) within the web UI. However, it says that https://openqa.suse.de/tests/9604440 has not been created by posting an ISO. So the question remains where it comes from considering it is wrong. Of course it could be that some data/relation is missing due to a bug. This is really a different case than the one I've mentioned in the ticket description, though.
Updated by dzedro over 2 years ago
Original job of wrongly cloned job without dependencies is not the real original job.
I guess I was looking also on the not real original job and I thought RETRY is not causing it because it was not defined.
I don't know how RETRY works, but I don't know what else is creating this broken clones if not RETRY.
where it comes from considering it is wrong.
Good question, I have no idea.
This are wrong jobs from 15.10., I don't know why was RETRY defined, I removed it again!
https://openqa.suse.de/tests/9740684
https://openqa.suse.de/tests/9740696
https://openqa.suse.de/tests/9740710
I think this is the original https://openqa.suse.de/tests/9737432 job which triggered one of the clones.
Why it happened today and this weird trigger times 21h, 1h ago ?
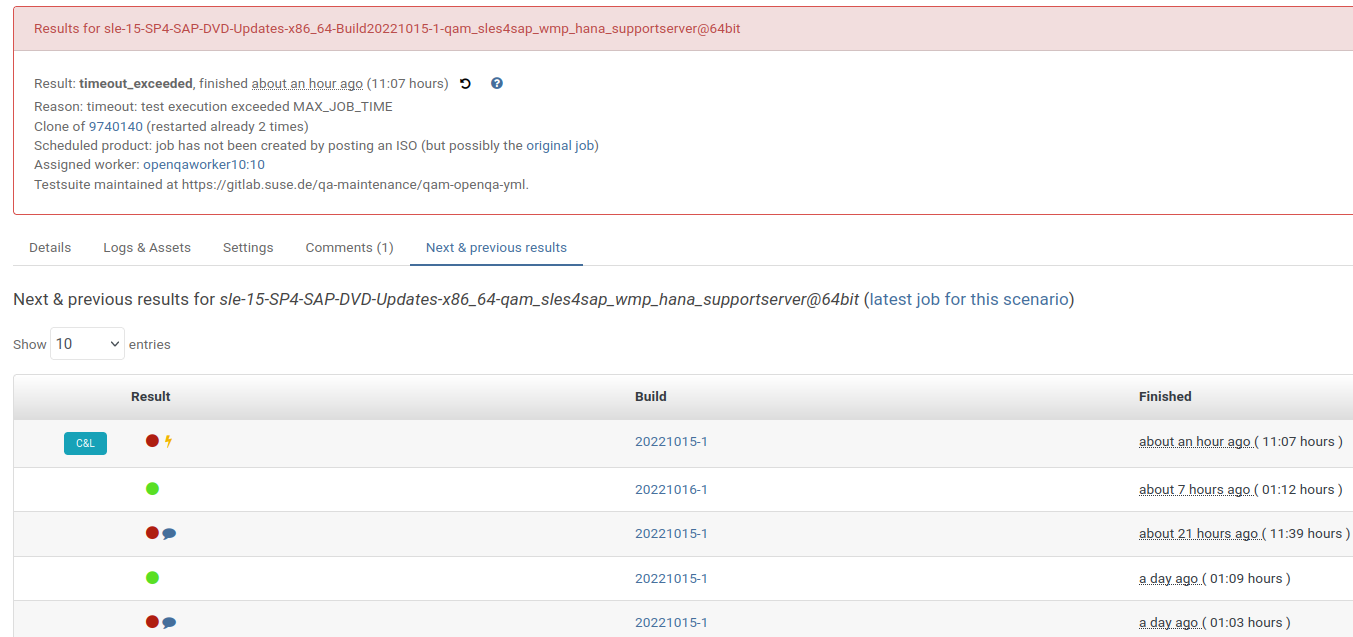
Updated by dzedro over 2 years ago
I found this original https://openqa.suse.de/tests/9678806 with wrong clones
https://openqa.suse.de/tests/9682964
https://openqa.suse.de/tests/9682966
https://openqa.suse.de/tests/9683524
RETRY is not used on this group
Also other clones
https://openqa.suse.de/tests/9683527
https://openqa.suse.de/tests/9683530
Updated by AdamWill over 2 years ago
From the issue I filed - https://progress.opensuse.org/issues/112256 - there's a fairly clear 'problematic' case, that recurs quite often on our (Fedora's) instance. Here's a recent example:
https://openqa.fedoraproject.org/tests/1653092#dependencies
as you can see, we have one parent of three child groups - it's a test that just checks Cockpit (https://github.com/cockpit-project/cockpit ) is working, then uploads its disk. Two of the child 'groups' are just single tests which test other features of Cockpit. The third child group contains tests of FreeIPA, our domain controller thing, because one of the tests in that group is 'enrol a system into the FreeIPA domain with Cockpit', so that test also wants to start from the Cockpit disk. All these tests have RETRY set.
There's an interesting timing overlap in this specific configuration, because it's possible for a job in the FreeIPA child group to fail before the parent Cockpit job is done. The 'enrol via cockpit' job in that child group has to wait for the Cockpit parent job, but none of the others do, and they can start running (and potentially fail) while the Cockpit parent job is still running. In this case, it seems that the 'enrol via command line' test failed while the Cockpit parent job was still running. As RETRY was set, the retry mechanism kicked in. openQA marked all the jobs in the FreeIPA child group as parallel_restarted and cloned them - fine. It also marked the Cockpit parent job as parallel_restarted and cloned it...but it did not include the other two child 'groups' (the individual Cockpit tests) in this.
Because they were left alone, they started immediately after the Cockpit parent job was cloned, and of course immediately failed 'incomplete' because the disk image the parent test should have uploaded did not exist. Because their parent job is still the original parent job that was marked parallel_restarted and abandoned, manually restarting these two jobs just results in an immediate incompletion again, because they still have no hard disk to use. The only way I can clean those jobs up is to reschedule the entire flavor.
I can see two ways openQA could behave better in this case. Either it should not restart the parent Cockpit job when a job in the child group fails. Maybe there's a different example scenario where doing so would make sense, but in this particular case it doesn't - the fact that one of the FreeIPA enrolment tests failed doesn't mean there's anything at all wrong with the "set up Cockpit" test. The child FreeIPA test group could just be restarted and the new "enrol via Cockpit" test given the same parent job. Or, if openQA really wants to restart the parent job, it should also restart all its other children too.
Updated by AdamWill over 2 years ago
So, the code here seems pretty complicated, but I'm trying to push through it. It's all in Schema/Result/Jobs.pm , it seems, going from auto_duplicate to duplicate to cluster_jobs and _create_clones (whew). One thing that sticks out to me: the comments above duplicate say "Rules for dependencies cloning are: ... for CHAINED dependencies: - do NOT clone parents ..." , but in my case, we do seem to be cloning the parent? I note the comment was written in 2015 but the code has been extensively poked since then. I'm having trouble figuring out if there really is still an attempt to exclude non-directly-chained parents anywhere, or if that was lost, intentionally or unintentionally. There is a comment "# normally we don't clone chained parents, but you never know" in _create_clones, but that also dates back a way, to 2018, when the code seems to have been quite different.
Updated by AdamWill over 2 years ago
Ooh, so I think I do see one clear issue in my case. Commit 15ab871362521fdd909fd31c552cadc1c4445cfd introduced the code block with the comment " # duplicate only up the chain if the parent job wasn't ok", which pulls a chained parent job into the to-be-cloned cluster if its result does not exist or is not "ok". This seems intended to catch cases where the parent job has completed and failed, but I'm not sure if it considered the possibility that the parent job may not yet have finished - in which case its result will not currently be 'ok', but that doesn't necessarily mean it needs restarting.
The comment there also notes "# notes: - We skip the children here to avoid considering "direct siblings"." I guess that means that in the example case, we don't want to go back down the chain to the other jobs in the same child group. But unfortunately this means we also don't go down the chain to jobs in other child groups, which basically get orphaned.
Obviously this is a pretty complex area :/ I can tweak the "# duplicate only up the chain if the parent job wasn't ok" to not pull in the parent job if it's still running, and I think that would make things 'right' for my specific case here, but I'm finding it hard to think about whether it might cause problems for some other case, e.g. whichever one 15ab871362521fdd909fd31c552cadc1c4445cfd was trying to fix...