Introduction¶
- Table of contents
- Introduction
- Organisational
- needling best practices
- Definition of DONE/READY
- How we work on tickets
- code contribution review checklist
- Test development instances (staging openQA instances)
- Tips for test development and issue investigation
Also see https://progress.opensuse.org/projects/openqav3/wiki
Organisational¶
ticket workflow¶
This project adheres to the ticket workflow as described on the parent project: ticket workflow
Also see the Definition-of-DONE on the use of ticket status, especially when to set Resolved.
The following issue categories are used:
- New test: Any extension of the existing test coverage, for example a new test module, a new test scenario as well as simply an addition of test steps within existing test modules
- Bugs in existing tests: Test failures that need to be investigated or obvious test failures which need fixing in the test codes or needle updates; not product bugs: Necessary adaptions to existing tests to make them usable again after acceptable product changes or to increase stability of unstable tests
- Enhancement to existing tests: Enhancements without changing the test scope, for example improvement of post_fail_hooks to gather more relevant logs, refactoring, cleanup of code, reducing duplication, make tests more stable, refactor to be easier to read, workflow related
- Infrastructure: Anything regarding the test infrastructure including workers used for o3 (openqa.opensuse.org) and osd (openqa.suse.de). Not directly related to the test code or needles but our infrastructure, e.g. worker issues, our syncing and triggering approach, etc.
- Spike/Research: Tickets that represent a timeboxed research of some sort, or also a spike with the sole intention of clarifying before spawning new tasks on a certain topic.
test organization on https://openqa.suse.de/
job group names¶
Job group names should be consistent and structured for easy (daily) review of the current status¶
template:
<product_group_short_name> <order_nr>.<product_variant>
e.g. "SLE 12 SP1 1.Server". Keep the whitespace for separation consistent, also see https://progress.opensuse.org/issues/9916
Released products should be named with a prefix 'x' to show up late in the overview page¶
This way we can keep track if tests fail even though the product does not produce new builds. This could help us crosscheck tests. E.g. "x-released SLE 12 SP1 1.Server".
lowercase "x" as all our product names start with capital letters. Sorting works regardless (or uppercase first?).
For now we do not retrigger tests on old builds automatically but any test developer may retrigger it manually, e.g. if he suspects the tests broke and he wants to confirm that local changes are not at fault.
needling best practices¶
There are also other locations where "needling best practices" can be found but we should also have the possibility to keep something on the wiki. Feel free to contact me (okurz) and tell me where it should be instead if there is a better place. Also look into openQA Pitfalls
applying "workaround" needles¶
If a test reveals a product issue of minor importance it can make sense create a needle with the property "workaround" set. This way, if the needle is matched, the test records this as a "soft-fail". To backtrack the product issue and follow on this and eventually delete the workaround needle if the product issue is fixed, the product issue should be recorded in the needle name itself and at best also in the git commit message adding the needle. If test changes are necessary the source code should have a corresponding comment referencing the issue as well as marking start and stop of the test procedure that is necessary for applying the workaround. Example for a needle name: "gdm-workaround-bsc962806-20160125" referencing bsc#962806
keep in mind:
Since gh-os-autoinst#532 workaround needles are always preferred, otherwise if two needles match, the first in alphabetical list wins. Therefore it is even more important to prevent "greedy" needles, i.e. make sure the workaround needles do not match without checking for the error condition
do not overwrite old needles because old date confuses people¶
With the needle editor a timestamp of the current day is automatically added to new needles. When updating a needle, don't overwrite a needle with the old date tag not to confuse people as it will look really weird in the needle editor.
needle indidvidual column entries in tables¶
Problem: Tables might auto-adjust column size based on content. Therefore it is unsafe to create needles covering multiple columns in a row. Failing example: https://openqa.suse.de/tests/441169#step/yast2_snapper/23
Solution: Needles support multiple areas. Use them to needle individual cells in this example.
don't include version specific content in needles¶
Problem: Creating a needle that covers version number of application or product version fails often for every update, e.g. see opensuse-42.2-DVD-x86_64-Build0112-xfce@64bit. Obviously the needle does not match because no one so far created a needle for firefox 47 on Leap42.2 on xfce.
Solution: openQA in general supports exclusion areas and even OCR but they have its flaws. For now better carefully select matching areas so that versions are not included like in the following example
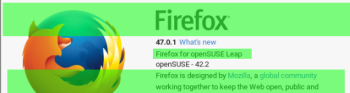 .
.
ensure prerequisites for next test steps¶
Problem: A needle looks for a part of a screen before continuing with next steps, e.g. in a wizard. It might happen that the system is seemingly "loosing" key presses as the expected actions are not triggered. For example this happened in https://progress.opensuse.org/issues/61877
Solution: Needles need to ensure that the system is ready to accept the next action, e.g. not only check for expected content in text but also that a "Next" button is not greyed out or that all dynamic content in a wizard is already shown. Also see https://github.com/os-autoinst/os-autoinst-distri-opensuse/pull/9667#discussion_r386828207
consider a lower than default "match ratio"¶
Problem: By default the openQA needle editor proposes a rather strict "match ratio" to prevent false positive matches. Many people do not know about the meaning of "match ratio" at all and just create new needles on mismatches with default parameters. As soon as there are even slight UI or rendering changes often many tests fail needing multiple needle updates which can cause a lot of work and a big overhead of needle changes which are again often created keeping the default high "match ratio".
Solution: Consider lowering the "match ratio" in all cases where slight UI or rendering changes should be acceptable and not cause test failures. For this keep in mind that bigger match areas allow bigger changes for the same match ratio so e.g. select "80%" for small size match areas, higher values for bigger areas.
Definition of DONE/READY¶
Each of the following points has to be fulfilled to regard individual contributions as DONE. Not every step has to be done by the same step. The overall completion is in responsibility of the complete team.
Definition of DONE¶
Also see http://www.allaboutagile.com/definition-of-done-10-point-checklist/ and https://www.scrumalliance.org/community/articles/2008/september/what-is-definition-of-done-%28dod%29
The following definitions are used to ensure development on individual tests has been completed covering all existing different workflows, e.g. covering "hot-fixes" on the productive instance as well as contributions by new contributors with no previous experience and no control over needle generation on productive instances.
- Code changes are made available via a pull request on the github repository
- New tests as individual test modules (i.e. files under
tests/): They are loaded in main.pm of sle and/or opensuse - "make test" works (e.g. automatic travis CI check triggered on each github PR)
- Guidelines for git commits have been followed
- Code has been reviewed (e.g. in the github PR)
- Favored, but depending on criticality/complexity/size: A local verification test has been run, e.g. post link to a local openQA machine or screenshot or logfile
- Test modules that have been touched have updated metadata, e.g. "Maintainer" and "Summary" (#13034)
- Potentially impacted product variants have been considered, e.g. openSUSE, SLE, validation tests for new product versions currently in development, maintenance tests on older product versions
- Code has been merged (either by reviewer or reviewee after 'LGTM' from others)
- Code has been deployed to osd and o3 (automatic git sync every few minutes)
- If new variables are necessary (feature toggles): A test_suite is executing the test, e.g. test_suite is created or variable is added to existing test_suite over web interface configuration on osd and/or o3
- If a new test_suite has been created:
- The test_suite is added to at least one job_group
- The test_suite has a description describing the goal of the new test + at least one maintainer. Optional: References to fate#, boo#, bsc#, poo#
- Necessary needles are made available as PR for sle and/or opensuse (depending if executed, see above for 'main.pm') or are created on the productive instance
- At least one successful test run has been observed on osd or o3 and referenced in the corresponding progress item or bugzilla bug report if one exists. There is one exception: If the test fails in a valid product bug and it is expected that a bug fix will be provided shortly the test run may also fail when labeled accordingly.
Definition of READY for new tests¶
The following points should be considered before a new test is READY to be implemented:
- Either a product bug has been discovered for which there is no automated test in openQA or a FATE request for new features exists
- A test case description exists depicting the prerequisites of the test, the steps to conduct and the expected result
- The impact and applicability for both SLE and openSUSE products has been considered
a good practice is to also add the following one after another:
- a tag in the subject line of either "[easy]", "[medium]", "[hard]" depending on how you judge the implementation of the ticket in comparison to other known examples from experience. E.g. a simple "needle update" should be "[easy]" as well as changes to only one test module. A change that would involve updating the test API, needles and test code and impacting multiple products can be "[hard]"
- add acceptance criteria (see ticket template)
- add tasks as a hint where to start
How we work on tickets¶
ticket backlog triaging¶
Also see https://progress.opensuse.org/projects/suseqa/wiki#ticket-refinement-grooming
- Categorize: Goal -> No ticket without category
- Categorize QSF-U
- Tag: Goal -> No ticket without component or responsibility tags
SLOs (service level objectives)¶
See the following as target numbers or "guideline", "should be", in priorities from top to bottom. Each query should show zero entries if objectives are met. See openQA Tests Backlog Status for an overview of all queries.
- for picking up tickets based on priority, first goal is "urgency removal":
- immediate: <1 day or <1 day for all subprojects of qa
- urgent: <1 week or <1 day for all subprojects of qa
- high: <1 month
- normal: <1 year
- low: undefined
- Within due-date: 0 (10 day threshold) . Where set, we should take due-dates serious, finish tickets fast and at the very least update tickets with an explanation why the due-date could not be hold and update to a reasonable time in the future based on usual time expectations.
- No closed tickets linked to currently failing tests: 0 (daily) . Closed tickets mean assignees assume the issue would be fixed but as long as tests still fail either the issue was not fixed or a new issue is wrongly tracked
- No unassigned tickets linked to currently failing tests: 0 (daily) . Tickets linked to currently failing tests should be prioritized, at least by following the established Maintenance QA process to unschedule false-positive tests
Process: If SLO time periods exceeded consider putting a reminder on the according ticket at the end of each SLO period. If the ticket pops up again (and the last comment was the reminder comment), de-prioritize to the next lower level (This could be automated).
Notifications: People may be watching the project in Redmine, and that's recommended for SM and PO roles. As general good practice if you're relying on someone to respond, you can also add them as a "Watcher" for an individual tickets (mentions via @ don't have that effect in Redmine).
Note: Adherence is also automatically observed by @slo-gin (SLO generic infra node) which is a bot that adds reminder comments based on queries with a "updated_on" filter defined in openSUSE/openqa-tests-backlog/queries.yaml.
Text template for update comments on outdated tickets depending on current ticket priority:
-
Immediate:
This ticket was set to "Immediate" priority but was not updated within the SLO period for "Immediate" tickets (1 day) as described on https://progress.opensuse.org/projects/openqatests/wiki/Wiki#SLOs-service-level-objectives-
first reminder:
Please consider picking up this ticket within the next day or just set the ticket to the next lower priority "Urgent" (SLO: updated within 7 days). -
second reminder:
The ticket will be set to the next lower priority "Urgent".
-
first reminder:
-
Urgent:
This ticket was set to "Urgent" priority but was not updated within the SLO period for "Urgent" tickets (7 day) as described on https://progress.opensuse.org/projects/openqatests/wiki/Wiki#SLOs-service-level-objectives-
first reminder:
Please consider picking up this ticket within the next 7 days or just set the ticket to the next lower priority "High" (SLO: updated within 30 days). -
second reminder:
The ticket will be set to the next lower priority "High".
-
first reminder:
-
High:
This ticket was set to "High" priority but was not updated within the SLO period for "High" tickets (30 days) as described on https://progress.opensuse.org/projects/openqatests/wiki/Wiki#SLOs-service-level-objectives-
first reminder:
Please consider picking up this ticket within the next 30 days or just set the ticket to the next lower priority "Normal" (SLO: updated within 365 days). -
second reminder:
The ticket will be set to the next lower priority "Normal".
-
first reminder:
-
Normal:
This ticket was set to "Normal" priority but was not updated within the SLO period for "Normal" tickets (365 days) as described on https://progress.opensuse.org/projects/openqatests/wiki/Wiki#SLOs-service-level-objectives-
first reminder:
Please consider picking up this ticket within the next 365 days or just set the ticket to the next lower priority "Low" (no SLO related time period). -
second reminder:
The ticket will be set to the next lower priority "Low".
-
first reminder:
-
Due-date exceeded:
This ticket had a due set but exceeded it already by more than 14 days. We would like to take the due date seriously so please update the ticket accordingly (resolve the ticket or update the due-date or remove the due-date). See https://progress.opensuse.org/projects/openqatests/wiki/Wiki#SLOs-service-level-objectives for details.
Note: Individual teams can apply different workflows in subprojects. Any differences in what can be expected should be documented accordingly
openqa-review reminder handling¶
- Guideline: No closed tickets with unhandled openqa-review reminder comments: 0 (daily)
- Given any resolved ticket When an openqa-review reminder comment shows up, Then reopen the ticket To ensure the test failure is reviewed and handled accordingly
- If the reopened ticket is not acted upon the same process applies as already documented on https://progress.opensuse.org/projects/openqatests/wiki#SLOs-service-level-objectives
It is important to have a process noted down so that we have an objective base and also prevent frustration among users. There is also potential for automation but it's not a necessity to implement the process in the first step.
code contribution review checklist¶
Check each pull request on https://github.com/os-autoinst/os-autoinst-distri-opensuse against the following rules
- https://github.com/os-autoinst/os-autoinst-distri-opensuse#coding-style
- DoD is adhered to
- SLE staging impact has been considered (be careful accepting changes during working days when a stable SLE staging project is expected by release managers)
Test development instances (staging openQA instances)¶
Contributors cannot afford to verify a newly developed test in all scenarios run by o3 or osd, so tests will break sometime. It would be useful to use a machine to run a subset of the scenarios run in the official instance(s) to make sure the new tests can be deployed with some degree of confidence. But: Any "staging openQA instance" would not be able to run everything which is run in production. It just does not scale. So anyway only a subset can be run and there can be always something missing. Also, we don't have the hardware capacity to cover everything twice and also consider SLE plus openSUSE. Our DOD should cover some important steps so that external contributors are motivated to test something locally first. We have a good test review process and it has to be decided by the reviewer if he accepts the risk of a new test with or without a local verification and covering which scenarios. Depending on the contributors it might make sense to setup a staging server with a subset of tests which is used by multiple test developers to share the burden of openQA setup and administration. For example the YaST team has one available: https://wiki.microfocus.net/index.php/YAST/openQA
If you want to follow this model you can watch this talk by Christopher Hofmann from the OSC16 or ask the YaST team for their experiences.
Tips for test development and issue investigation¶
Examples mentioned here write clone_job and client. Replace this by a call to the scripts within openQA installation with the corresponding name and proper arguments to provide your API key as well as the host selection, e.g. /usr/share/openqa/client --host https://openqa.opensuse.org with your API key configured in ~/.config/openqa/client.conf
Uploading image files to openqa server and run test on it¶
You can manually trigger a test job with explicit name as one-shot overriding the variables as necessary, for example:
as geekotest@openqa:
cd /var/lib/openqa/factory/hdd
wget http://<my_host>/<path>.qcow2 -O <new_image_name>.qcow2
cd /var/lib/openqa/factory/iso
/usr/share/openqa/script/client isos post --params SLE-12-SP2-Server-DVD-ppc64le-Build1651-Media1.iso.6.json HDD_1=SLE-12-Server-ppc64le-GM-gnome_with_snapper.qcow2 TEST=migration_offline_sle12_ppc BUILD=1651_<your_short_name>
why SLE-12-SP2-Server-DVD-ppc64le-Build1651-Media1.iso.6.json? I checked SLE-12-SP2-Server-DVD-ppc64le-Build1651-Media1.iso.?.json: There are …5… and …6…. …5… is for HA so I chose 6.
The job can be cleaned afterwards to tidy up the build history with:
client jobs/463859 delete
Create new HDD image with openQA¶
client jobs post DISTRI=sle VERSION=12 FLAVOR=Server-DVD ARCH=ppc64le BACKEND=qemu \
NOVIDEO=1 OFW=1 QEMUCPU=host SERIALDEV=hvc0 BUILD=okurz_poo9714 \
ISO=SLE-12-Server-DVD-ppc64le-GM-DVD1.iso INSTALLONLY=1 QEMU_COMPRESS_QCOW2=1 \
PUBLISH_HDD_1=SLES-12-GM-gnome-ppc64le_snapper_20g.qcow2 TEST=create_gm_ppc_image \
MACHINE=ppc64le WORKER_CLASS=qemu_ppc64le HDDSIZEGB=20 MAX_JOB_TIME=86400 TIMEOUT_SCALE=10
The MAX_JOB_TIME=86400 TIMEOUT_SCALE=10 allows for interactive login during the process in case you want to manually adjust or debug. Beware though that TIMEOUT_SCALE=10 also scales the waiting time on check_screen so that the whole job might take longer to execute.
To run a test but based on the new HDD image search for a good example and clone it with adjusted parameter:
clone_job 462022 HDD_1=SLES-12-GM-gnome-ppc64le_snapper_20g.qcow2
Interactive investigation¶
While a job is running one can connect to the worker (if network access is possible) using VNC. One challenge is that the test is still running and manual interaction with the system interferes with the test and vice versa.
Making the test stop for long enough to be able to connect¶
If you can change the test code, i.e. if running on a development machine, you can for example add a sleep 3600; or wait_serial 'CONTINUE'; at the point in test when you want to connect to the system and interact with it, e.g. to gather additional logs. In case of wait_serial 'CONTINUE'; you can echo 'CONTINUE' to the serial point to let the test continue, e.g. call echo 'CONTINUE' > /dev/ttyS0;.
In case you can not or do not want to change the test code or your test run is stopping anyway at a certain point with long enough timeout you can also increase timeout with TIMEOUT_SCALE, e.g. trigger it with the job variable TIMEOUT_SCALE=10. For example a script_run with default timeout of 90 seconds will wait for 900 seconds (=15 minutes) which should give enough time in most cases already.
Other possibility is to enter the interactive mode using the Interactive mode button on "Live view" tab of job run and then stop the execution. After that the qemu VM will enter debug mode.
Making VM active again¶
In case of interactive mode usage, as mentioned above, VM will get to debug mode and freeze. To make VM interactive again, we need to send the 'cont' command over qemu HMP.
To perform these activity within the o3 infrastructure, multiple steps are required:
- Request adding your ssh public key to access o3
- Connect to o3 using the following command:
ssh o3
- Now you will be able to connect as root to the worker of your choice using ssh
- Use 'ps' to find relevant qemu VM instance and get the qemu telnet monitor port. Hint: you can use the vnc port shown when cursor is on the worker's name on job page, e.g.:
ps aux | grep :91
- Connect to the VM using VNC (see next section)
- Connect to the VM monitor using telnet:
telnet localhost 20072
- Type the
contcommand to continue:
cont
NOTE: please use '^]' as escape character, detach will stop VM.
VNC port forwarding¶
After configuring the ssh profile for connection to o3, it's possible to perform port forwarding using ssh using following command:
ssh -L <local_port_number>:<worker_hostname>:<vnc_port_on_remote_host> -NT4f o3
For example:
ssh -L 5997:openqa-worker:5997 -NT4f o3
After that you can connect to this port using VNC.
Connecting over VNC¶
The VNC port is shown on the job live view as a hover text on the instance name. Make sure to use a "shared" connection in your vncviewer. krdc, the default KDE VNC viewer, as well as vinagre, default GNOME VNC viewer, do this already. For TigerVNC use for example:
vncviewer -Shared malbec.arch:91
Forwarding of special shortcuts¶
The default vncviewer in openSUSE/SUSE systems is recommended as it can also be used to forward special keyboard shortcuts. E.g. to change to text console:
Press F8 in vncviewer, select ctrl and alt in menue, exit menue, press F2.
Requesting video when by default you do not have video in your environment¶
Example:
openqa-clone-job https://openqa.opensuse.org/464665 NOVIDEO=0
Structured test issue investigation¶
In the cases of non-trivial issues it makes sense to use the "scientific method" especially because openQA tests being system tests are under influence of many moving parts. Also see https://progress.opensuse.org/projects/openqav3/wiki#Further-decision-steps-working-on-test-issues about this.
Bug Hunting and the Scientific Method is a suggested read as well as How to Fix the Hardest Bug You've Ever Seen: The Scientific Method. It is suggested to note down in tickets the hypotheses of all potential relevant problem sources, design experiments - which can be as simple as checking the logfile, collect observations, accept/reject hypotheses and therefore derive a better understanding of what is happening to eventually come to a conclusion. s390 dasdfmt fails even though command looks complete in screenshot can serve as an real-world example ticket how it can look like.
See https://progress.opensuse.org/projects/openqav3/wiki/#Further-decision-steps-working-on-test-issues for a ticket template extension.
Statistical investigation¶
In case issues appear sporadically and are therefore hard to reproduce it can help to trigger many more jobs on a production instance to gather more data first, for example the failure ratio.
You can use the "repeat" option on openqa-clone-job to trigger multiple jobs for investigation outside normal job groups so that the result of passed/jobs is counted by openQA itself on the corresponding overview page, for example:
openqa-clone-job --repeat=50 --skip-chained-deps --parental-inheritance --within-instance https://openqa.opensuse.org 123456 TEST+=-$USER_poo32242 BUILD=poo32242_investigation _GROUP=0
Or with a bash loop, example of triggering 100 jobs in the development group:
for i in {001..100} ; do openqa-clone-job --skip-chained-deps --within-instance https://openqa.opensuse.org 123456 TEST+=-$USER_poo32242_$i BUILD=poo32242_investigation _GROUP="Test Development: openSUSE Tumbleweed" ; done
Alternatively, there's another script: https://github.com/foursixnine/stunning-octo-chainsaw/blob/master/openQA/trigger-multiple-jobs
Both alternatives will make the results visible on https://openqa.opensuse.org/tests/overview?build=poo32242_investigation
okurz suggests to use https://github.com/okurz/scripts/blob/master/count_fail_ratio to get an overview about the fail ratio and confidence interval of sporadically failing applications.
Updated by okurz over 1 year ago · 62 revisions