Introduction¶
This is the organisation wiki for the openQA Project.
The source code is hosted in the os-autoinst github project, especially openQA itself and the main backend os-autoinst
If you are interested in the tests for SUSE/openSUSE products take a look into the openqatests project.
If you are looking for entry level issues to contribute to please look into the section Where to contribute
- Table of contents
- Introduction
- Organisational
- Use cases
- Thoughts about categorizing test results, issues, states within openQA
- Important ticket queries
- Proposals for uses of labels
- s390x Test Organisation
- Infrastructure setup for o3 (openqa.opensuse.org) and osd (openqa.suse.de)
- o3 (openqa.opensuse.org)
- Hotfixing
- Mitigation of boot failure or disk issues
- PPC specific configurations
- Moving worker from osd to o3
- Distribution upgrades
- openQA infrastructure needs (o3 + osd)
- Setup guide for new machines
- Take machines out of salt-controlled production
- How to use samba shares to mount ISOs as virtual CD drives with SuperMicro server/mainboards
- Bring back machines into salt-controlled production
- Access the BMC of machines in the SUSE network zones
- Using the build-in java tools of BMCs to access machines in the security zone
- Use a production host for testing backend changes locally, e.g. svirt, powerVM, IPMI bare-metal, s390x, etc.
- Dealing with XEN servers
- Dealing with PowerEdge SAP servers from Dell
- Backup
- Best practices for infrastructure work
- Automatic submission of packages
Organisational¶
ticket workflow¶
The following ticket statuses are used together and their meaning is explained:
- New: No one has worked on the ticket (e.g. the ticket has not been properly refined) or no one is feeling responsible for the work on this ticket.
- Workable: The ticket has been refined and is ready to be picked.
- In Progress: Assignee is actively working on the ticket.
- Resolved: The complete work on this issue is done and the according issue is supposed to be fixed as observed (Should be updated together with a link to a merged pull request or also a link to an production openQA showing the effect)
- Feedback: Further work on the ticket needs clarification of open points within the ticket or is awaiting feedback from others or other systems (e.g. automated tests) to proceed. Sometimes also used to ask Assignee about progress on inactivity.
- Blocked: Further work on the ticket is blocked by some external dependency (e.g. bugs, not implemented features). There should be a link to another ticket, bug, trello card, etc. where it can be seen what the ticket is blocked by.
- Rejected: The issue is considered invalid, should not be done, is considered out of scope.
- Closed: As this can be set only by administrators it is suggested to not use this status.
It is good practice to update the status together with a comment about it, e.g. a link to a pull request or a reason for reject.
ticket categories¶
- Regressions/Crashes: Regressions, crashes, error messages
- Feature requests: Ideas or wishes for extension, enhancement, improvement
- Organisational: Organisational tasks within the project(s), not directly code related
- Support: Support of users, usage problems, questions
Please avoid the use of other, deprecated categories
Suggestion by okurz: I recommend to avoid the word "bug" in our categories because of the usual "is it a bug or a feature" struggle. Instead I suggest to strictly define "Regressions & Crashes" to clearly separate "it used to work in before" from "this was never part of requirements" for Features. Any ticket of this category also means that our project processes missed something so we have points for improvements, e.g. extend things to look out for in code review.
Epics and Sagas¶
[epic]s and [saga]s belong to the "coordination" tracker, project contributors are not required to follow this convention but the tracker may be changed automagically in the future: http://mailman.suse.de/mailman/private/qa-sle/2020-October/002722.html
ticket templates¶
You can use these templates to fill in tickets and further improve them with more detail over time. Copy the code block, paste it into a new issue, replace every block marked with "<…>" with your content or delete if not appropriate.
Defects¶
Subject: <Short description, example: "openQA dies when triggering any Windows ME tests">
## Observation
<description of what can be observed and what the symptoms are, provide links to failing test results and/or put short blocks from the log output here to visualize what is happening>
## Steps to reproduce
* <do this>
* <do that>
* <observe result>
## Impact
<clearly state the impact of issues to make sure according prioritization is applied and rollbacks/downgrades can be applied>
## Problem
<problem investigation, can also include different hypotheses, should be labeled as "H1" for first hypothesis, etc.>
## Suggestions
* <what to do as a first step>
* <Fix the actual problem>
* <Consider fixing the design>
* <Consider fixing the team's process>
* <Consider to explore further>
## Workaround
<example: retrigger job>
example ticket: #10526
For tickets referencing "auto_review" see
https://github.com/os-autoinst/scripts/blob/master/README.md#auto-review---automatically-detect-known-issues-in-openqa-jobs-label-openqa-jobs-with-ticket-references-and-optionally-retrigger
for a suggested template snippet.
Feature requests¶
Subject: <Short description, example: "grub3 btrfs support" (feature)>
## User story
<As a <role>, I want to <do an action>, to <achieve which goal> >
## Acceptance criteria
* <**AC1:** the first acceptance criterion that needs to be fulfilled to do this, example: Clicking "restart button" causes restart of the job>
* <**AC2:** also think about the "not-actions", example: other jobs are not affected>
## Suggestions
* <first task to do as an easy starting point>
* <what do do next, all tasks optionally with an effort estimation in hours, e.g. "(0.5-2h)">
* <optional: mark "optional" tasks>
## Further details
<everything that does not fit into above sections>
example ticket: #10212
Other often used sections that can be considered
## Motivation
<Where this idea/request comes from, what is the context, etc.; Could be alternatively used to the user story section>
## Acceptance tests
* <**AT1-1:** the first acceptance test for AC1 (see "Acceptance criteria" above), example: "Go to https://openqa.opensuse.org/tests and confirm that the requested new button is visible">
* <**AT1-2:** the second acceptance test for AC1 (see "Acceptance criteria" above), often the counter-test, example: "Go to https://openqa.opensuse.org/tests and confirm that the requested new button is *not* visible if do_not_show_button=True is set in the server config">
## Rollback steps
* <What was implemented as workaround or temporary measure and needs to be undone before the ticket is resolved. Often added retroactively>
## Out-of-scope
* <What is explicitly decided to be *not* covered within this ticket. Often used to limit the effort on work and preventing conflicts by relating to other tickets covering those aspects>
For phrasing acceptance tests (or also acceptance criteria) consider using Cucumber Gherkin definitions following https://cucumber.io/docs/gherkin/reference/ in the format *Given* … *When* … *Then* with optional use of *And* and *Not*
Further decision steps working on test issues¶
Test issues could be one of the following sources. Feel free to use the following template in tickets as well
## Problem
* **H1** The product has changed
* **H1.1** product changed slightly but in an acceptable way without the need for communication with DEV+RM --> adapt test
* **H1.2** product changed slightly but in an acceptable way found after feedback from RM --> adapt test
* **H1.3** product changed significantly --> after approval by RM adapt test
* **H2** Fails because of changes in test setup
* **H2.1** Our test hardware equipment behaves different
* **H2.2** The network behaves different
* **H3** Fails because of changes in test infrastructure software, e.g. os-autoinst, openQA
* **H4** Fails because of changes in test management configuration, e.g. openQA database settings
* **H5** Fails because of changes in the test software itself (the test plan in source code as well as needles)
* **H6** Sporadic issue, i.e. the root problem is already hidden in the system for a long time but does not show symptoms every time
This is following the scientific method, Also read http://yellerapp.com/posts/2014-08-11-scientific-debugging.html and http://web.mit.edu/6.031/www/fa17/classes/13-debugging/. It is suggested to use the characters H (hypothesis), E (experiment), O (observation), e.g. like this
* **H3** Fails because of changes in test infrastructure software, e.g. os-autoinst, openQA
* **H3.1** **REJECTED** Fails because of changes in openQA itself
* **E3.1-1** (First experiment for hypothesis 3.1) test on an openQA server with the openQA version of "last good"
* **O3.1-1-1** (First observation for first experiment for hypothesis 3) the test failed in the same way, reject *H3.1*
Additional details needed for non-qemu issues¶
As the automatic integration tests of os-autoinst and openQA are based on qemu virtualization, for any non-qemu related requests please provide detailed manual reproduction steps, otherwise it is unlikely that any issue or feature request can be implemented.
pull request handling on github¶
As a reviewer of pull requests on github for all related repositories, e.g. https://github.com/os-autoinst/os-autoinst-distri-opensuse/pulls, apply labels in case PRs are open for a longer time and can not be merged so that we keep our backlog clean and know why PRs are blocked.
- notready: Triaged as not ready yet for merging, no (immediate) reaction by the reviewee, e.g. when tests are missing, other scenarios break, only tested for one of SLE/TW
- wip: Marked by the reviewee itself as "[WIP]" or "[DO-NOT-MERGE]" or similar
- question: Questions to the reviewee, not answered yet
Where to contribute?¶
If you want to help openQA development you can take a look into the existing issues.
You can start with
- entrance level issues
- issues tagged as easy
- issues tagged as beginner - not necessarily "easy" but more suitable for someone coming to a project with little or no domain specific knowledge
- ideas from #65271
There are also some "always valid" tasks to be working on:
- improve test coverage:
- user story: As openqa backend as well as test developer I want better test coverage of our projects to reduce technical debt
- acceptance criteria: test coverage is significantly higher than before
- suggestions: check current coverage in each individual project (os-autoinst/openQA/os-autoinst-distri-opensuse) and add tests as necessary
Use cases¶
The following use cases 1-6 have been defined within a SUSE workshop (others have been defined later) to clarify how different actors work with openQA. Some of them are covered already within openQA quite well, some others are stated as motivation for further feature development.
Use case 1¶
User: QA-Project Managment
primary actor: QA Project Manager, QA Team Leads
stakeholder: Directors, VP
trigger: product milestones, providing a daily status
user story: „As a QA project manager I want to check on a daily basis the „openQA Dashboard“ to get a summary/an overall status of the „reviewers results“ in order to take the right actions and prioritize tasks in QA accordingly.“
Use case 2¶
User: openQA-Admin
primary actor: Backend-Team
stakeholder: Qa-Prjmgr, QA-TL, openQA Tech-Lead
trigger: Bugs, features, new testcases
user story: „As an openQA admin I constantly check in the web-UI the system health and I manage its configuration to ensure smooth operation of the tool.“
Use case 3¶
User: QA-Reviewer
primary actor: QA-Team
stakeholder: QA-Prjmgr, Release-Mgmt, openQA-Admin
trigger: every new build
user story: „As an openQA-Reviewer at any point in time I review on the webpage of openQA the overall status of a build in order to track and find bugs, because I want to find bugs as early as possible and report them.“
Use case 4¶
User: Testcase-Contributor
primary actor: All development teams, Maintenance QA
stakeholder: QA-Reviewer, openQA-Admin, openQA Tech-Lead
trigger: features, new functionality, bugs, new product/package
user story: „As developer when there are new features, new functionality, bugs, new product/package in git I contribute my testcases because I want to ensure good quality submissions and smooth product integration.“
Use case 5¶
User: Release-Mgmt
primary actor: Release Manager
stakeholder: Directors, VP, PM, TAMs, Partners
trigger: Milestones
user story: „As a Release-Manager on a daily basis I check on a dashboard for the product health/build status in order to act early in case of failures and have concrete and current reports.“
Use case 6¶
User: Staging-Admin
primary actor: Staging-Manager for the products
stakeholder: Release-Mgmt, Build-Team
trigger: every single submission to projects
user story: „As a Staging-Manager I review the build status of packages with every staged submission to the „staging projects“ in the „staging dashboard“ and the test-status of the pre-integrated fixes, because I want to identify major breakage before integration to the products and provide fast feedback back to the development.“
Use case 7¶
User: Bug investigator
primary actor: Any bug assignee for openQA observed bugs
stakeholder: Developer
trigger: bugs
user story: „As a developer that has been assigned a bug which has been observed in openQA I can review referenced tests, find a newer and the most recent job in the same scenario, understand what changed since the last successful job, what other jobs show same symptoms to investigate the root cause fast and use openQA for verification of a bug fix.“
Thoughts about categorizing test results, issues, states within openQA¶
by okurz
When reviewing test results it is important to distinguish between different causes of "failed tests"
Nomenclature¶
Test status categories¶
A common definition about the status of a test regarding the product it tests: "false|true positive|negative" as described on https://en.wikipedia.org/wiki/False_positives_and_false_negatives. "positive|negative" describes the outcome of a test ("positive": test signals presence of issue; "negative": no signal) whereas "false|true" describes the conclusion of the test regarding the presence of issues in the SUT or product in our case ("true": correct reporting; "false": incorrect reporting), e.g. "true negative", test successful, no issues detected and there are no issues, product is working as expected by customer. Another example: Think of testing as of a fire alarm. An alarm (event detector) should only go off (be "positive") if there is a fire (event to detect) --> "true positive" whereas if there is no fire there should be no alarm --> "true negative".
Another common but potentially ambiguous categorization:
- broken: the test is not behaving as expected (Ambiguity: "as expected" by whom?) --> commonly a "false positive", can also be "false negative" but hard to detect
- failing: the test is behaving as expected, but the test output is a fail --> "true positive"
- working: the test is behaving as expected (with no comment regarding the result, though some might ambiguously imply 'result is negative')
- passing: the test is behaving as expected, but the result is a success --> "true negative"
If in doubt declare a test as "broken". We should review the test and examine if it is behaving as expected.
Be careful about "positive/negative" as some might also use "positive" to incorrectly denote a passing test (and "negative" for failing test) as an indicator of "working product" not an indicator about "issue present". If you argue what is "used in common speech" think about how "false positive" is used as in "false alarm" --> "positive" == "alarm raised", also see https://narainko.wordpress.com/2012/08/26/understanding-false-positive-and-false-negative/
Priorization of work regarding categories¶
In this sense development+QA want to accomplish a "true negative" state whenever possible (no issues present, therefore none detected). As QA and test developers we want to prevent "false positives" ("false alarms" declaring a product as broken when it is not but the test failed for other reasons), also known as "type I error" and "false negatives" (a product issue is not catched by tests and might "slip through" QA and at worst is only found by an external outside customer) also known as "type II error". Also see https://en.wikipedia.org/wiki/Type_I_and_type_II_errors. In the context of openQA and system testing paired with screen matching a "false positive" is much more likely as the tests are very susceptible to subtle variations and changes even if they should be accepted. So when in doubt, create an issue in progress, look at it again, and find that it was a false alarm, rather than wasting more peoples time with INVALID bug reports by believing the product to be broken when it isn't. To quote Richard Brown: "I […] believe this is the route to ongoing improvement - if we have tests which produce such false alarms, then that is a clear indicator that the test needs to be reworked to be less ambiguous, and that IS our job as openQA developers to deal with".
Further categorization of statuses, issues and such in testing, especially automatic tests¶
By okurz
This categorization scheme is meant to help in communication in either written or spoken discussions being simple, concise, easy to remember while unambiguous in every case.
While used for naming it should also be used as a decision tree and can be followed from the top following each branch.
Categorization scheme¶
To keep it simple I will try to go in steps of deciding if a potential issue is of one of two categories in every step (maybe three) and go further down from there. The degree of further detailing is not limited, i.e. it can be further extended. Naming scheme should follow arabic number (for two levels just 1 and 2) counting schemes added from the right for every additional level of decision step and detail without any separation between the digits, e.g. "1111" for the first type in every level of detail up to level four. Also, I am thinking of giving the fully written form phonetic name to unambiguously identify each on every level as long as not more individual levels are necessary. The alphabet should be reserved for higher levels and higher priority types.
Every leaf of the tree must have an action assigned to it.
1 failed (ZULU)
11 new (passed->failed) (YANKEE)
111 product issue ("true positive") (WHISKEY)
1111 unfiled issue (SIERRA)
11111 hard issue (openqa fail) (KILO)
111121 critical / potential ship stopper (INDIA) --> immediately file bug report with "ship_stopper?" flag; opt. inform RM directly
111122 non-critical hard issue (HOTEL) --> file bug report
11112 soft issue (openqa softfail on job level, not on module level) (JULIETT) --> file bug report on failing test module
1112 bugzilla bug exists (ROMEO)
11121 bug was known to openqa / openqa developer --> cross-reference (bug->test, test->bug) AND raise review process issue, improve openqa process
11122 bug was filed by other sources (e.g. beta-tester) --> cross-reference (bug->test, test->bug)
112 test issue ("false positive") (VICTOR)
1121 progress issue exists (QUEBEC) --> cross-reference (issue->test, test->issue)
1122 unfiled test issue (PAPA)
11221 easy to do w/o progress issue
112211 need needles update --> re-needle if sure, TODO how to notify?
112212 pot. flaky, timeout
1122121 retrigger yields PASS --> comment in progress about flaky issue fixed
1122122 reproducible on retrigger --> file progress issue
11222 needs progress issue filed --> file progress issue
12 existing / still failing (failed->failed) (XRAY)
121 product issue (UNIFORM)
1211 unfiled issue (OSCAR) --> file bug report AND raise review process issue (why has it not been found and filed?)
1212 bugzilla bug exists (NOVEMBER) --> ensure cross-reference, also see rules for 1112 ROMEO
122 test issue (TANGO)
1221 progress issue exists (MIKE) --> monitor, if persisting reprioritize test development work
1222 needs progress issue filed (LIMA) --> file progress issue AND raise review process issue, see 1211 OSCAR
2 passed (ALFA)
21 stable (passed->passed) (BRAVO)
211 existing "true negative" (DELTA) --> monitor, maybe can be made stricter
212 existing "false negative" (ECHO) --> needs test improvement
22 fixed (failed->passed) (CHARLIE)
222 fixed "true negative" (FOXTROTT) --> TODO split monitor, see 211 DELTA
2221 was test issue --> close progress issue
2222 was product issue
22221 no bug report exists --> raise review process issue (why was it not filed?)
22222 bug report exists
222221 was marked as RESOLVED FIXED
221 fixed but "false negative" (GOLF) --> potentially revert test fix, also see 212 ECHO
Priority from high to low: INDIA->OSCAR->HOTEL->JULIETT->…
Important ticket queries¶
- All auto-review tickets: https://progress.opensuse.org/projects/openqav3/issues?query_id=697 , see https://github.com/os-autoinst/scripts/blob/master/README.md#auto-review---automatically-detect-known-issues-in-openqa-jobs-label-openqa-jobs-with-ticket-references-and-optionally-retrigger for further information regarding auto-review
- All auto-review+force-result tickets: https://progress.opensuse.org/projects/openqav3/issues?query_id=700
Proposals for uses of labels¶
With Show bug or label icon on overview if labeled (gh#550) it is possible to add custom labels just by writing them. Nevertheless, a convention should be found for a common benefit. Beware that labels are also automatically carried over with (Carry over labels from previous jobs in same scenario if still failing [gh#564])(https://github.com/os-autoinst/openQA/pull/564) which might make consistent test failures less visible when reviewers only look for test results without labels or bugrefs. Labels are not anymore automatically carried over (gh#1071).
List of proposed labels with their meaning and where they could be applied.
-
fixed_<build_ref>: If a test failure is already fixed in a more recent build and no bug reference is known, use this label together with a reference to a more recent passed test run in the same scenario. Useful for reviewing older builds. Example (https://openqa.suse.de/tests/382518#comments):
label:fixed_Build1501
t#382919
-
needles_added: In case needles were missing for test changes or expected product changes caused needle matching to fail, use this label with a reference to the test PR or a proper reasoning why the needles were missing and how you added them. Example (https://openqa.suse.de/tests/388521#comments):
label:needles_added
needles for https://github.com/os-autoinst/os-autoinst-distri-opensuse/pull/1353 were missing, added by jpupava in the meantime.
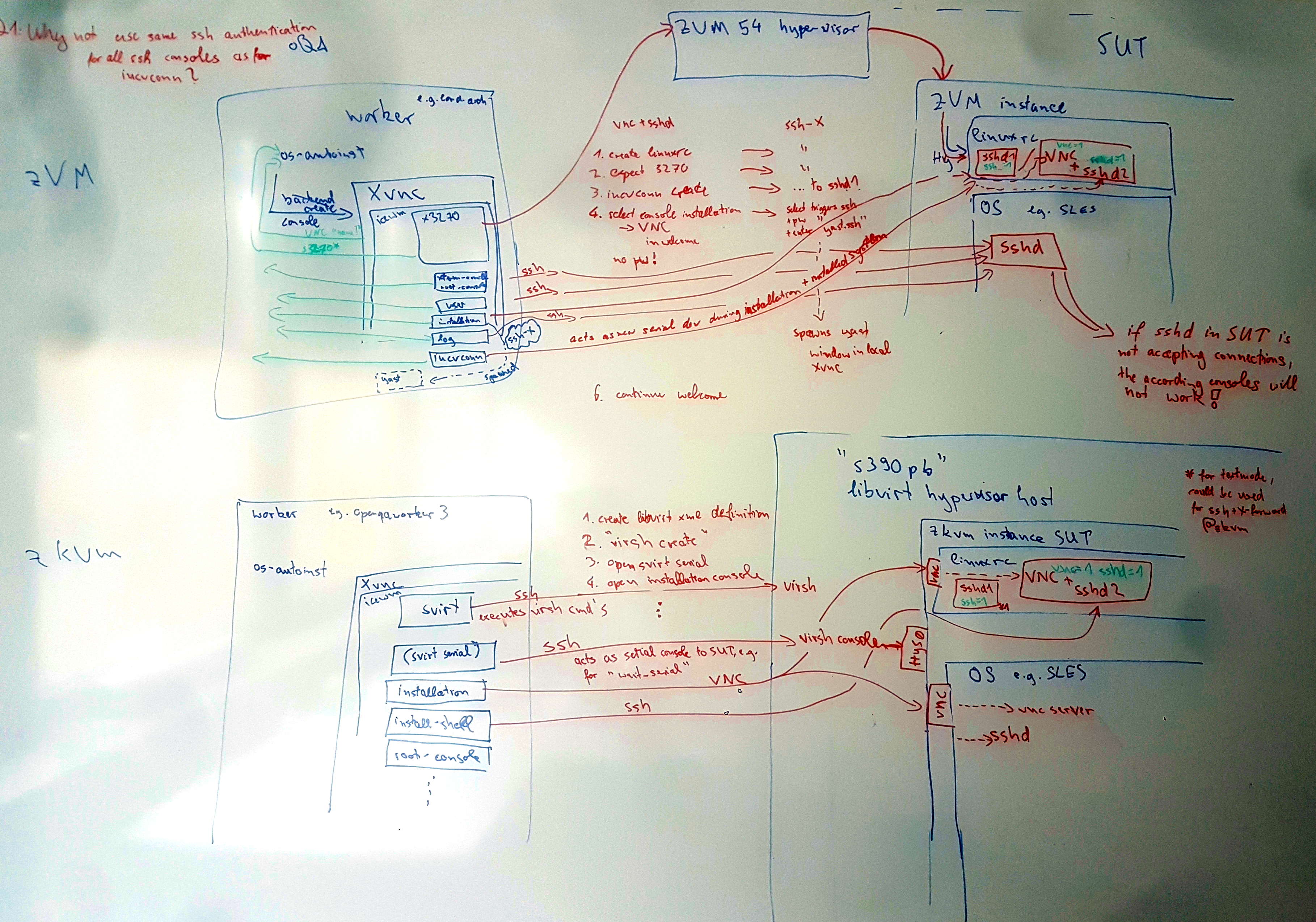
s390x Test Organisation¶
See the following picture for a graphical overview of the current s390x test infrastructure at SUSE:
Upgrades¶
on z/VM¶
special Requirements¶
Due to the lack of proper use of hdd-images on zVM, we need to workaround this with having a dedicated worker_class aka a dedicated Host where we run two jobs with START_AFTER_TEST,
the first one which installs the basesystem we want to have upgraded and a second one which is doing the actually upgrade (e.g migration_offline_sle12sp2_zVM_preparation and migration_offline_sle12sp2_zVM)
Since we encountered issues with randomly other preparation jobs are started in between there, we need to ensure that we have one complete chain for all migration jobs running on one worker, that means for example:
- migration_offline_sle12sp2_zVM_preparation
- migration_offline_sle12sp2_zVM (START_AFTER_TEST=#1)
- migration_offline_sle12sp2_allpatterns_zVM_preparation (START_AFTER_TEST=#2)
- migration_offline_sle12sp2_allpatterns_zVM
- ...
This scheme ensures that all actual Upgrade jobs are finding the prepared system and are able to upgrade it
on z/KVM¶
No special requirements anymore, see details in #18016
Automated z/VM LPAR installation with openQA using qnipl¶
There is an ongoing effort to automate the LPAR creation and installation on z/VM. A first idea resulted in the creation of qnipl. qnipl enables one to boot a very slim initramfs from a shared medium (e.g. shared SCSI-disks) and supply it with the needed parameters to chainload a "normal SLES installation" using kexec.
This method is required for z/VM because snipl (Simple network initial program loader) can only load/boot LPARs from specific disks, not network resources.
Setup¶
- Get a shared disk for all your LPARs
- Normally this can easily done by infra/gschlotter
- Disks needs to be connected to all guests which should be able to network-boot
- Boot a fully installed SLES on one of the LPARs to start preparing the shared-disk
- Put a DOS partition table on the disk and create one single, large partition on there
- Put a FS on there. Our first test was on ext2 and it worked flawlessly in our attempts
- Install
zipl(The s390x bootloader from IBM) on this partition
- A simple and sufficient config can be found in poo#33682
- clone
qniplto your dracut modules (e.g. /usr/lib/dracut/modules.d/95qnipl) - Include the module named
qniplto your dracut modules for initramfs generation
- e.g. in /etc/dracut.conf.d/99-qnipl.conf add:
add_dracutmodules+=qnipl
- Generate your initramfs (e.g.
dracut -f -a "url-lib qnipl" --no-hostonly-cmdline /tmp/custom_initramfs)
- Put the initramfs next to your kernel binary on the partition you want to prepare
- From now on you can use
sniplto boot any LPAR connected with this shared disk from network
- example:
snipl -f ./snipl.conf -s P0069A27-LP3 -A fa00 --wwpn_scsiload 500507630713d3b3 --lun_scsiload 4001401100000000 --ossparms_scsiload "install=http://openqa.suse.de/assets/repo/SLE-15-Installer-DVD-s390x-Build533.2-Media1 hostip=10.0.0.1/20 gateway=10.0.0.254 Nameserver=10.0.0.1 Domain=suse.de ssh=1" -
--ossparms_scsiloadis then evaluated and used byqniplto kexec into the installer with the (for the installer) needed parameters
Further details¶
Further details can also be found in the github repo. Pull requests, questions and ideas always welcome!
Infrastructure setup for o3 (openqa.opensuse.org) and osd (openqa.suse.de)¶
Both o3 and osd are hosted in SUSE data centers, mostly Nuremberg, Germany, and Prague, Czech Republic. For SUSE internal information about the osd (openqa.suse.de) setup see https://wiki.suse.net/index.php/OpenQA
o3 (openqa.opensuse.org)¶
o3 consists of a VM running the web UI and physical worker machines. The VM for o3 has netapp backed storage on rotating disk so less performant than SSD but cheaper. So eventually we might have the possibility to use SSD based storage. Currently there are four virtual storage devices provided to o3 totalling to more than 10 TB.
The o3 infrastructure is in detail described on https://github.com/os-autoinst/sync-and-trigger/blob/main/openqa-opensuse.md
Temporary things regarding the move to PRG2¶
On new-ariel there is the service autossh-old-ariel.service. If we get an email Problem: Interface tun5: Link down from zabbix this is the service we need to check.
Accessing the o3 infrastructure¶
Currently, ariel can only be accessed from the internal SUSE network through ariel.dmz-prg2.suse.org.
Ask one of the existing admins within https://app.element.io/#/room/#openqa:opensuse.org or irc://irc.libera.chat/opensuse-factory (so that I know you can be reached over those channels when people have questions to you what you did with the ssh access) to put your ssh key on the o3 webui host to be able to login.
To give access for a new user an existing admin can do the following:
sudo useradd -G users,trusted --create-home $user
echo "$ssh_key_from_user" | sudo tee -a /home/$user/.ssh/authorized_keys
SSH configuration¶
To easily access all hosts behind the jump host you can use the following config for your ssh client (~/.ssh/config):
Host ariel
HostName ariel.dmz-prg2.suse.org
Host *.opensuse.org
ProxyJump ariel
A word of warning: be aware that this enables agent-forwarding to at least the jumphost. Please read up for yourself if and how bad you consider the security implications of doing so.
The workers can only be accessed from "ariel", not directly. One can use password authentication on the workers using the root account. Ask existing admins for the root password. It is suggested that you use key-based authentication. For this put your ssh keys on all the workers, e.g. using the above configuration and ssh-copy-id.
Notice: Some machines are connected to the o3 openQA host from other networks and might need different ways of access, at time of writing:
- Remote (owner: @ggardet_arm):
- ip-10-0-0-58
- oss-cobbler-03
- siodtw01 (for tests on Raspberry Pi 2,3,4)
- Frankencampus (SUSE internal):
- aarch64-o3.qe.nue2.suse.org
- kerosene.qe.nue2.suse.org
Manual command execution on o3 workers¶
To execute commands manually on all workers within the o3 infrastructure one can do for example the following:
hosts="openqaworker20 openqaworker21 openqaworker22 openqaworker23 openqaworker24 openqaworker25 openqaworker26 openqaworker27 openqaworker28 openqaworker-arm21 openqaworker-arm22 qa-power8-3"
for i in $hosts; do echo $i && ssh root@$i "zypper -n dup && reboot" ; done
for i in $hosts; do echo $i && ssh root@$i " echo 'ssh-rsa … …' >> /root/.ssh/authorized_keys " ; done
mind the correct list of machines.
As of 2024-04 the following hosts are not available:
Formerly for true transactional servers we used:
for i in $hosts; do echo $i && ssh root@$i "(transactional-update -n dup || zypper -n dup) && reboot" ; done
To execute commands on additional workers (not reachable from o3 directly):
hosts="kerosene.qe.nue2.suse.org aarch64-o3.qe.nue2.suse.org"
for i in $hosts; do echo $i && ssh root@$i "zypper -n dup && reboot" ; done
Automatic update of o3¶
o3 is continuously deployed, that includes both the webUI host as well as the workers.
Automatic update of o3 webUI host¶
openqa.opensuse.org applies continuous updates of openQA related packages, conducts nightly updates of system packages and reboots automatically as required, see
http://open.qa/docs/#_automatic_system_upgrades_and_reboots_of_openqa_hosts
for details
Recurring automatic update of openQA workers¶
Same as the o3 webUI all o3 workers all apply continuous updates of openQA related packages. Additionally most apply a daily automatic system update. power8 is does a weekly update of the system every Sunday.
This was done to get and keep all the machines consistent after a few years of drift
These systems currently patch themselves and reboot automatically in the default maintenance window of 0330-0500 CET/CEST.
On problems this could be changed in the following way:
- Edit the maintenance window in /etc/rebootmgr.conf
- Disable the automatic reboot by "systemctl disable rebootmgr.service"
EDIT: 2022-07-11: All o3 machines are effectively not "transactional-workers" anymore as openqa-continuous-update.service is doing a complete zypper dup every couple of minutes. With rebootmgr triggered for reboot still automatic nightly reboots happen as necessary. See #111989 for details
SUSE employees have access to the bootmenu for the openQA worker machines, e.g. openqaworker21 and so on. "snapper rollback" can be executed from a booted, functionally operative machine which one can ssh into.
For manual investigation https://github.com/kubic-project/microos-toolbox can be helpful
Rollback of updates¶
Updates on workers can be rolled back using snapper rollback:
for i in $hosts; do echo $i && ssh root@$i "snapper rollback && reboot"; done
Updates on the central webUI host openqa.opensuse.org can be rolled back by using either older variants of packages that receive maintenance updates or using the locally cached packages in e.g. /var/cache/zypp/packages/devel_openQA/noarch using zypper in --oldpackage, similar to https://github.com/os-autoinst/openQA/blob/master/script/openqa-rollback#L39
Debugging qemu SUTs in openqa.opensuse.org¶
SUT: System Under Test
os-autoinst starts qemu with network type that doesn't allow access from the outside, so ssh is not possible. But, qemu is started with a VNC channel available from the host (the openQA-worker).
Running vncviewer inside a headless server is useless, but it is possible to use ariel as a jump host and SSH port forwarding to start vncviewer client from your desktop environment and connect to the VNC channel of the qemu SUT.
ssh -L LOCAL_PORT:WORKER_HOSTNAME:QEMU_VNC_PORT ariel
For example, if user bernhard, wants to connect to openqaworker7:11, and wants to use local port 43043
And the VNC channel port of openqa-worker@11 6001 (5990 + 11)
1. Create SSH tunnel with port forwarding¶
- on laptop shell 1: ssh -L 43043:openqaworker7:6001 ariel
- Keep shell open to keep the tunnel open and the port forwarding
2. Open vncviewer¶
- on laptop shell 2: vncviewer -Shared localhost:43043
-
-sharedis needed to not kick the VNC connection of os-autoinst. If it is kicked, the job will terminate and the qemu process will be killed.
AArch64 specific configurations on o3¶
On o3, the aarch64 workers need additional configuration.
Setup HugePages¶
You need to setup HugePages support to improve performances with qemu VM and to match current aarch64 MACHINE configuration.
For the D05 machine, the configuration is: 40 pages with a size of 1G.
If there are some permissions issues on /dev/hugepages/, check https://progress.opensuse.org/issues/53234
o3 s390 and other (e.g. bare-metal) workers¶
workers.ini
[global]
HOST=http://openqa1-opensuse
WORKER_HOSTNAME = 192.168.112.6
CACHEDIRECTORY=/var/lib/openqa/cache
CACHESERVICEURL=http://10.88.0.1:9530/
[101]
WORKER_CLASS=s390x-zVM-vswitch-l2,s390x-rebel-1-linux144
BACKEND=s390x
ZVM_HOST=192.168.112.9
ZVM_GUEST=linux144
ZVM_PASSWORD=lin390
S390_HOST=144
[102]
WORKER_CLASS=s390x-zVM-vswitch-l2,s390x-rebel-2-linux145
BACKEND=s390x
ZVM_HOST=192.168.112.9
ZVM_GUEST=linux145
ZVM_PASSWORD=lin390
S390_HOST=145
[103]
WORKER_CLASS=s390x-zVM-vswitch-l2,s390x-rebel-3-linux146
BACKEND=s390x
ZVM_HOST=192.168.112.9
ZVM_GUEST=linux146
ZVM_PASSWORD=lin390
S390_HOST=146
[104]
WORKER_CLASS=s390x-zVM-vswitch-l2,s390x-rebel-4-linux147
BACKEND=s390x
ZVM_HOST=192.168.112.9
ZVM_GUEST=linux147
ZVM_PASSWORD=lin390
S390_HOST=147
[105]
WORKER_CLASS=64bit-ipmi,64bit-ipmi-large-mem,64bit-ipmi-amd,blackbauhinia
IPMI_HOSTNAME=blackbauhinia-ipmi.openqanet.opensuse.org
IPMI_USER=ADMIN
IPMI_PASSWORD=ADMIN
SUT_IP=blackbauhinia.openqanet.opensuse.org
SUT_NETDEVICE=em1
IPMI_SOL_PERSISTENT_CONSOLE=1
IPMI_BACKEND_MC_RESET=1
[http://openqa1-opensuse]
TESTPOOLSERVER=rsync://openqa1-opensuse/tests
Allow containers to access cache service (systemctl edit openqa-worker-cacheservice.service):
# /etc/systemd/system/openqa-worker-cacheservice.service.d/override.conf
[Service]
Environment="MOJO_LISTEN=http://0.0.0.0:9530"
The s390 and ipmi workers for openQA are running within podman containers on openqaworker23.
The containers are started using systemd but the unit files are specific to the containers and will end up in a restart-loop if this fact is ignored. Whenever the containers are recreated, the systemd files have to be recreated.
The containers are started like this (for i=101…104):
i=101
podman run --pull=newer -d -h openqaworker23_container --name openqaworker23_container_$i -p $(python3 -c"p=${i}*10+20003;print(f'{p}:{p}')") -e OPENQA_WORKER_INSTANCE=$i -v /opt/s390x_opensuse:/etc/openqa -v /var/lib/openqa/share:/var/lib/openqa/share -v /var/lib/openqa/cache:/var/lib/openqa/cache registry.opensuse.org/devel/openqa/containers15.5/openqa_worker_os_autoinst_distri_opensuse:latest
(cd /etc/systemd/system/; podman generate systemd -f -n --new openqaworker23_container_$i --restart-policy always)
systemctl daemon-reload
systemctl enable container-openqaworker23_container_$i
To restart and permanently enable all workers at once:
for i in {101..104} ; do systemctl stop container-openqaworker23_container_$i ; done
podman rm -f openqaworker23_container_{101..104}
for i in {101..104} ; do podman run --pull=newer -d -h openqaworker23_container --name openqaworker23_container_$i -p $(python3 -c"p=${i}*10+20003;print(f'{p}:{p}')") -e OPENQA_WORKER_INSTANCE=$i -v /opt/s390x_opensuse:/etc/openqa -v /var/lib/openqa/share:/var/lib/openqa/share -v /var/lib/openqa/cache:/var/lib/openqa/cache registry.opensuse.org/devel/openqa/containers15.5/openqa_worker_os_autoinst_distri_opensuse:latest ; done
for i in {101..104} ; do (cd /etc/systemd/system/; podman generate systemd -f -n --new openqaworker23_container_$i --restart-policy always) ; done
systemctl daemon-reload
podman rm -f openqaworker1_container_{101..104}
for i in {101..104} ; do systemctl reenable container-openqaworker23_container_$i && systemctl restart container-openqaworker23_container_$i ; done
Initial ticket when the setup was created: https://progress.opensuse.org/issues/97751
As addition with https://progress.opensuse.org/issues/153706 we implemented IPMI workers in a similar manner starting with worker-slot 201. Its configuration can be found on worker23 in /opt/ipmi_opensuse.
As alternative s390x workers can run on the host "rebel" as well. Be aware that openQA workers accessing the same s390x instances must not run in parallel so only enable one worker instance per s390x instance at a time (See https://progress.opensuse.org/issues/97658 for details).
Monitoring¶
openqa.opensuse.org is monitored by SUSE over https://zabbix.suse.de/. There is a user group "Owners/O3" to which SUSE employees can be added. Alert notification is configured via trigger action in a special Infra-owned RO bot account. E-mail notification is in place for average problems and higher.
There is also an internal munin instance on o3. Anyone wanting to look at the HTML pages, do this:
rsync -a o3:/srv/www/htdocs/munin ~/o3-munin/
(where "o3" is configured in your ssh config of course)
It's also possible to view the munin page via an ssh tunnel:
ssh -L 8080:127.0.0.1:80 o3
and then go to http://127.0.0.1:8080/munin/
Configuration of alerts is done in /etc/munin/munin.conf
Hotfixing¶
Applying hotfixes, e.g. patches from an os-autoinst pull requests to O3 workers can be applied like this for a pull request <pr_id>:
for i in $hosts; do
echo $i && ssh root@$i
"snapper create --description 'Patch from PR ${pr_id}' &&
curl -sS https://patch-diff.githubusercontent.com/raw/os-autoinst/os-autoinst/pull/${pr_id}.patch | patch -p1 --directory=/usr/lib/os-autoinst &&
reboot"
done
Hotpatching on all OSD workers with the same <pr_id> as above with something like
sudo salt --no-color --state-output=changes -C 'G@roles:worker' cmd.run 'curl -sS https://patch-diff.githubusercontent.com/raw/os-autoinst/os-autoinst/pull/${pr_id}.patch | patch -p1 --directory=/usr/lib/os-autoinst'
Mitigation of boot failure or disk issues¶
Worker stuck in recovery¶
Check disk health and consider manual fixup of mount points, e.g.:
test -e /dev/md/openqa || lsblk -n | grep -v nvme | grep "/$" && mdadm --create /dev/md/openqa --level=0 --force --raid-devices=$(ls /dev/nvme?n1 | wc -l) --run /dev/nvme?n1 || mdadm --create /dev/md/openqa --level=0 --force --raid-devices=1 --run /dev/nvme0n1p3
PPC specific configurations¶
In one case it was necessary to disable snapshots for petitboot with nvram -p default --update-config "petitboot,snapshots?=false" to prevent a race condition between dm_raid and btrfs trying to discover bootable devices (#68053#note-25). In another case https://bugzilla.opensuse.org/show_bug.cgi?id=1174166 caused the boot entries to be not properly discovered and it was necessary to prevent grub from trying to update the according sections (#68053#note-31).
Moving worker from osd to o3¶
- Ensure system management, e.g. over IPMI works. This is untouched by the following steps and can be used during the process for recovery and setup
- Ensure network is configured for DHCP
- Instruct SUSE-IT to change VLAN for machine from oqa.suse.de VLAN to 662 (example: https://sd.suse.com/servicedesk/customer/portal/1/SD-124055,
https://infra.nue.suse.com/SelfService/Display.html?id=16458 (not available anymore)) - Remove from osd:
salt-key -y -d worker7.oqa.suse.de
-
On the worker * Change root password to o3 one
-
Allow ssh password authentication:
sed -i 's/^PasswordAuthentication/#&/' /etc/ssh/sshd_config && systemctl restart sshd -
Ensure ssh based root login works with
zypper -n in openssh-server-config-rootloginor if that is not available change 'PermitRootLogin' to 'yes' in sshd_config -
Add personal ssh key to machine, e.g. openqaworker7:/root/.ssh/authorized_keys
-
Add entry on o3 to
/etc/dnsmasq.d/openqa.confwith MAC address, e.g.
dhcp-host=54:ab:3a:24:34:b8,openqaworker7
- Add entry to
/etc/hostswhich dnsmasq picks up to give out a DHCP lease, e.g.
192.168.112.12 openqaworker7.openqanet.opensuse.org openqaworker7
-
Reload dnsmasq with
systemctl restart dnsmasq -
Adapt NFS mount point on the worker
sed -i '/openqa\.suse\.de/d' /etc/fstab && echo 'openqa1-opensuse:/ /var/lib/openqa/share nfs4 noauto,nofail,retry=30,ro,x-systemd.automount,x-systemd.device-timeout=10m,x-systemd.mount-timeout=30m 0 0' >> /etc/fstab
- Restart network on machine (over IMPI) using
systemctl restart networkand monitor in o3:journalctl -f -u dnsmasquntil address is assigned, e.g.:
Feb 29 10:48:30 ariel dnsmasq[28105]: read /etc/hosts - 30 addresses
Feb 29 10:48:54 ariel dnsmasq-dhcp[28105]: DHCPREQUEST(eth1) 10.160.1.101 54:ab:3a:24:34:b8
Feb 29 10:48:54 ariel dnsmasq-dhcp[28105]: DHCPNAK(eth1) 10.160.1.101 54:ab:3a:24:34:b8 wrong network
Feb 29 10:49:10 ariel dnsmasq-dhcp[28105]: DHCPDISCOVER(eth1) 54:ab:3a:24:34:b8
Feb 29 10:49:10 ariel dnsmasq-dhcp[28105]: DHCPOFFER(eth1) 192.168.112.12 54:ab:3a:24:34:b8
Feb 29 10:49:10 ariel dnsmasq-dhcp[28105]: DHCPREQUEST(eth1) 192.168.112.12 54:ab:3a:24:34:b8
Feb 29 10:49:10 ariel dnsmasq-dhcp[28105]: DHCPACK(eth1) 192.168.112.12 54:ab:3a:24:34:b8 openqaworker7
- Ensure all mountpoints up
mount -a
- Update /etc/openqa/client.conf with the same key as used on other workers for "openqa1-opensuse"
- Update /etc/openqa/workers.ini with similar config as used on other workers, e.g. based on openqaworker4, example:
# diff -Naur /etc/openqa/workers.ini{.osd,}
--- /etc/openqa/workers.ini.osd 2020-02-29 15:21:47.737998821 +0100
+++ /etc/openqa/workers.ini 2020-02-29 15:22:53.334464958 +0100
@@ -1,17 +1,10 @@
-# This file is generated by salt - don't touch
-# Hosted on https://gitlab.suse.de/openqa/salt-pillars-openqa
-# numofworkers: 10
-
[global]
-HOST=openqa.suse.de
-CACHEDIRECTORY=/var/lib/openqa/cache
-LOG_LEVEL=debug
-WORKER_CLASS=qemu_x86_64,qemu_x86_64_staging,tap,openqaworker7
-WORKER_HOSTNAME=10.X.X.101
-
-[1]
-WORKER_CLASS=qemu_x86_64,qemu_x86_64_staging,tap,qemu_x86_64_ibft,openqaworker7
+HOST=http://openqa1-opensuse
+WORKER_HOSTNAME=192.168.112.12
+CACHEDIRECTORY = /var/lib/openqa/cache
+CACHELIMIT = 50
+WORKER_CLASS = openqaworker7,qemu_x86_64
-[openqa.suse.de]
-TESTPOOLSERVER = rsync://openqa.suse.de/tests
+[http://openqa1-opensuse]
+TESTPOOLSERVER = rsync://openqa1-opensuse/tests
- Remove OSD specifics
systemctl disable --now auto-update.timer salt-minion telegraf
for i in NPI SUSE_CA telegraf-monitoring; do zypper rr $i; done
zypper -n dup --force-resolution --allow-vendor-change
- Enable apparmor
zypper -n in apparmor-utils
systemctl unmask apparmor
systemctl enable --now apparmor
- Switch firewall from SuSEfirewall2 to firewalld
zypper -n in firewalld && zypper -n rm SuSEfirewall2
systemctl enable --now firewalld
firewall-cmd --zone=trusted --add-interface=br1
firewall-cmd --set-default-zone trusted
firewall-cmd --zone=trusted --add-masquerade
- Copy over special openSUSE UEFI staging images, see #63382
- For multi-machine configured workers make sure to have updated IPv4 entries in /etc/wicked/scripts/gre_tunnel_preup.sh
- Check operation with a single openQA worker instance:
systemctl enable --now openqa-worker.target openqa-worker@1
- Test with an openQA job cloned from a production job, e.g. for openqaworker7
openqa-clone-job --within-instance https://openqa.opensuse.org/t${id} WORKER_CLASS=openqaworker7
- After the latest openQA job could successfully finish enable more worker instances
systemctl unmask openqa-worker@{2..14} && systemctl enable --now openqa-worker@{2..14}
- Monitor if nightly update works, e.g. look at the journal entries of
openqa-continuous-update.serviceandrebootmgr.service
Distribution upgrades¶
Note: Performing the upgrade differs slightly depending on the host setup:
- Consider stopping the workers without interrupting currently running jobs. This may take some time, as the worker/worker slots will wait for any currently running jobs to finish before going offline
- On hosts with a writable
/you need to enter a root shell i.e.sudo bash - Depending on available space it might be necessary to cleanup space before conducting the upgrade, e.g. use
snapper rm <N..M>to delete older root btrfs snapshots, cleanup unneeded packages, e.g. with https://github.com/okurz/scripts/blob/master/zypper-rm-orphaned and https://github.com/okurz/scripts/blob/master/zypper-rm-unneeded - Upgrades might pull in too many new packages so better crosscheck with
zypper … dup … --no-recommends - Consider using https://github.com/okurz/auto-upgrade/blob/master/auto-upgrade or manual (Tip*: Run this in
screen -d -r || screenand use e.g.sudo bash): - When updating workers: Update one machine first and run a bunch of test jobs to see whether everything still works. Other teams might also appreciate if we'd run special jobs they maintain. In particular, the kernel squad would like if we could clone kernel-related scenarios (so we should reach out to them once we have updated the first machine and ask for scenarios to clone).
new_version=15.5 # Specify the target release
# Change the release via the special $releasever
. /etc/os-release
sed -i -e "s/${VERSION_ID}/\$releasever/g" /etc/zypp/repos.d/*
zypper --releasever=$new_version --gpg-auto-import-keys ref
test -f /etc/openqa/openqa.ini && sudo -u geekotest /opt/openqa-scripts/dump-psql
systemctl stop openqa-continuous-update.timer # it would interfere, e.g. revert the previous zypper ref call
zypper -n --releasever=$new_version dup --auto-agree-with-licenses --replacefiles --download-in-advance
# Check config files for relevant changes
rpmconfigcheck
for i in $(cat /var/adm/rpmconfigcheck) ; do vimdiff ${i%.rpm*} $i ; done
rm $(cat /var/adm/rpmconfigcheck)
reboot
systemctl --failed
- Ensure that the upgrade was really successful, e.g. /etc/os-release should show the new version, the above
zypper dupcommand should show no more pending actions - Crosscheck for any obvious alerts, pipelines failing, user reports, etc.
- On any severe problems consider a complete rollback of the upgrade or also partial downgrade of packages, e.g. force-install older version of packages and zypper locks until an issue is fixed
- Monitor for successful openQA jobs on the host
openQA infrastructure needs (o3 + osd)¶
TL;DR: new OSD ARM workers needed, missing redundancy for o3-ppc, rest is needing replacement as nearly all current hardware is out of vendor provided maintenance (as of 2021-05), SSD storage for o3 would be good
2020-03: SUSE IT (EngInfra) provided us more space for O3 but we have only slow rotating-disk storage. Performance could be improved by providing SSD storage.
The most time and effort we currently struggle with storage space for OSD (openqa.suse.de). Both instances (OSD + O3) are using precious netapp-storage but there is currently no better approach to use different, external storage. An increase of the available space would be appreciated, see https://progress.opensuse.org/issues/57494 for details. Graphs like
https://stats.openqa-monitor.qa.suse.de/d/nRDab3Jiz/openqa-jobs-test?orgId=1&from=1578343509900&to=1578653794173&fullscreen&panelId=12 show how usual test backlogs are worked on within OSD by architecture. It can be seen that both the ppc64le and aarch64 backlogs are reduced fast so we do not need more ppc64le or aarch64 machines.
With number of workers and parallel processed tests as well as with the increased number of products tested on OSD and users using the system the workload on OSD constantly increases. The load is visible in https://monitor.qa.suse.de/d/WebuiDb/webui-summary?viewPanel=25 . From time to time should increase the number of CPU cores on the OSD VM due to the higher usage.
Setup guide for new machines¶
- Ensure the host has a proper DNS entry
- The MAC address of new o3 workers generally needs to be added to
/etc/dnsmasq.d/openqa.confand an IP address needs to be configured in/etc/hosts(both files are on ariel). - Hosts located at Frankencampus need a DNS entry via the OPS-Service repo, e.g. https://gitlab.suse.de/OPS-Service/salt/-/merge_requests/3687.
- The MAC address of new o3 workers generally needs to be added to
- Change IPMI/BMC passwords to use our common passwords instead of default IPMI
- OSD: Add to salt using https://gitlab.suse.de/openqa/salt-states-openqa
- Make sure to set /etc/salt/minion_id to the FQDN (see #90875#note-2 for reference)
- Checkout the next section for details
- o3: Setup the worker manually, see "Manual worker setup" section below
Network (legacy) boot via PXE and OS/worker setup¶
One can make use of our existing PXE infrastructure (which only supports legacy boot) following these steps:
- Ensure the boot mode allows legacy boot, e.g. select it in the machine's setup menu manually.
- Connect via IPMI and select "Leap -> HTTP -> Console" in our PXE menu, append
console=ttyS0,115200 autoyast=http://s.qa.suse.de/ay.xml.erb rootpassword=<passwd_to_login_as root>to the command line and wait until the installation has finished.- Short link directs to https://raw.githubusercontent.com/os-autoinst/openQA/master/contrib/ay-openqa-worker.xml.erb
- No need to generate the xml profile. The
autoyastparameter can work with .erb extension directly - If nothing shows up in the serial console, try a different console parameter, e.g.
console=ttyS1,115200.
- Configure repos, e.g. via the line of the scriptlet in http://s.qa.suse.de/ay.xml.erb.
- The scriptlet cannot be executed in the context of AutoYaST so this is a manual step at this point.
- Enable SSH access via
systemctl enable --now sshdand continue via SSH. - Install some basic software, e.g.
zypper in htop vim systemd-coredump. - For OSD workers, setup
salt-minionfollowing the documentation in our Salt states repository; otherwise setup the worker manually as explained in the next section. - Check whether the config looks good on the workers and whether jobs look good on the web UI host.
Manual worker setup¶
You likely want to configure the openQA development repository.
Then setup the worker like this:
echo "requires:openQA-worker" > /etc/zypp/systemCheck.d/openqa.check
zypper -n mr --keep-packages 1 devel_openQA devel_openQA_Leap # enable RPM files caching so older versions of openQA packages are available for an easy rollback
zypper -n in openQA-worker openQA-auto-update openQA-continuous-update os-autoinst-distri-opensuse-deps swtpm # openQA worker services plus dependencies for openSUSE distri or development repo if added previously
zypper -n in ffmpeg-4 # for using external video encoder as it is already configured on some machines like ow19, ow20 and power8
zypper -n in nfs-client # For /var/lib/openqa/share
zypper -n in bash-completion vim htop strace systemd-coredump iputils tcpdump bind-utils # for general tinkering
# enable cleanup of openQA repositories so we don't run out of disk space despite enabling RPM files caching
mkdir -p /etc/systemd/system/openqa-auto-update.service.d && echo -e \"[Service]\nEnvironment=OPENQA_PACKAGE_CACHE_RETENTION=1\" > /etc/systemd/system/openqa-auto-update.service.d/enable-pkg-cache-retention.conf && systemctl daemon-reload
echo "openqa1-opensuse:/ /var/lib/openqa/share nfs4 noauto,nofail,retry=30,ro,x-systemd.automount,x-systemd.device-timeout=10m,x-systemd.mount-timeout=30m 0 0" >> /etc/fstab
sed -i 's/\(solver.dupAllowVendorChange = \)false/\1true/' /etc/zypp/zypp.conf
# configure /etc/openqa/client.conf and /etc/openqa/workers.ini, then enable the desired number of worker slots, e.g.:
systemctl enable --now openqa-worker-auto-restart@{1..30}.service openqa-reload-worker-auto-restart@{1..30}.path openqa-auto-update.timer openqa-continuous-update.timer openqa-worker-cacheservice.service openqa-worker-cacheservice-minion.service rebootmgr.service
Also copy the OVMF images for staging tests (/usr/share/qemu/*staging*) from other workers. Those files are from the devel flavor of the OVMF package built in stagings and rings, e.g. https://build.opensuse.org/package/show/openSUSE:Factory:Rings:1-MinimalX/ovmf, just renamed.
UEFI boot via iPXE¶
The following steps are for the o3 environment but can likely also be adapted for setting up OSD workers. This section skips the setup of the OS as it doesn't differ when using UEFI/iPXE. Checkout the previous sections for the OS/worker setup.
Find the iPXE and dnsmasq network boot config at: https://github.com/os-autoinst/scripts/tree/master/ipxe
The boot.ipxe file contains instructions on how to build the required ipxe binaries for x86_64-BIOS, x86_64-UEFI and aarch64-UEFI that
embed the boot.ipxe script, which will load the menu.ipxe via TFTP or HTTP from the $next-server.
There's a PXE setup as part of dnsmasq.service running on ariel. It is currently configured to serve a legacy-only boot menu utilized by some tests. After following these steps, please restore this setup so tests can continue to use it.
First, make a file that contains the iPXE commands to boot available via some HTTP server. Here's how the file could look like for installing Leap 15.4 with AutoYaST:
#!ipxe
kernel http://download.opensuse.org/distribution/leap/15.4/repo/oss/boot/x86_64/loader/linux initrd=initrd console=tty0 console=ttyS1,115200 install=http://download.opensuse.org/distribution/leap/15.4/repo/oss/ autoyast=http://martchus.no-ip.biz/ipxe/ay-openqa-worker.xml rootpassword=…
initrd http://download.opensuse.org/distribution/leap/15.4/repo/oss/boot/x86_64/loader/initrd
boot
Then, setup the build of an iPXE UEFI image like explained on https://en.opensuse.org/SDB:IPXE_booting#Setup:
git clone https://github.com/ipxe/ipxe.git
cd ipxe
echo "#!ipxe
dhcp
chain http://martchus.no-ip.biz/ipxe/leap-15.4" > myscript.ipxe
As you can see, this build script contains the URL to the previously setup file. Of course commands could be built directly into the image but then you'd need to rebuild/redeploy the image all the time you want to make a change (instead of just editing a file on your HTTP server).
To conduct the build of the image, run:
cd src
make EMBED=../myscript.ipxe NO_WERROR=1 bin/ipxe.lkrn bin/ipxe.pxe bin-i386-efi/ipxe.efi bin-x86_64-efi/ipxe.efi
Note that these build options are taken from https://github.com/archlinux/svntogit-community/blob/packages/ipxe/trunk/PKGBUILD#L58 because when attempting to build on Tumbleweed I've otherwise ran into build errors.
Then you can copy the files to ariel and move them to a location somewhere under /srv/tftpboot:
# on build host
rsync bin-x86_64-efi/ipxe.efi openqa.opensuse.org:/home/martchus/ipxe.efi
# on ariel
sudo cp /home/martchus/ipxe.efi /srv/tftpboot/ipxe-own-build/ipxe.efi
Then configure the use of the image in /etc/dnsmasq.d/pxeboot.conf on ariel. Temporarily comment-out possibly disturbing lines and make sure the following lines are present:
enable-tftp
tftp-root=/srv/tftpboot
pxe-prompt="Press F8 for menu. foobar", 10
dhcp-match=set:efi-x86_64,option:client-arch,7
dhcp-match=set:efi-x86_64,option:client-arch,9
dhcp-match=set:efi-x86,option:client-arch,6
dhcp-match=set:bios,option:client-arch,0
dhcp-boot=tag:efi-x86_64,ipxe-own-build/ipxe.efi
Then run systemctl restart dnsmasq.service to apply and journalctl -fu dnsmasq.service to see what's going on.
Installation of machines being able to run kexec¶
If it is possible to directly execute "kexec" on a machine, e.g. on ppc64le machines running petitboot, it is possible to start a remote network installation following https://en.opensuse.org/SDB:Network_installation#Start_the_Installation . See #119008#note-6 for an example.
Linux Endpoint Protection Agent¶
Ensure any non-test OS installations have the Linux Endpoint Protection Agent deployed, see https://progress.opensuse.org/issues/123094 and https://confluence.suse.com/display/CS/Sensor+-+Linux+Endpoint+Protection+Agent for details
s390 LPAR setup¶
Originally from #51836-15. To be able to use s390x LPARs for use as KVM hypervisor hosts we followed those steps:
- Packages that need to be present:
- multipath-tools
- libvirt
- directories
- /var/lib/openqa/share/factory
- /var/lib/libvirt/images
- services
- libvirtd
- multipathd
- ZFCP disk for storing images
- cio_ignore -r [fc00,fa00] to whitelist the channels
- zfcp_host_configure [fa00,fc00] 1 to permanently enable the fcp devices
- multipath -ll to check what devices are there
- /usr/bin/rescan-iscsi-bus.sh to discover newly add ed zfcp disks
- fdisk to create new partition
- mkfs.ext4 to create file system
- /etc/fstab entries
- NFS openQA:
openqa.suse.de:/var/lib/openqa/share/factory /var/lib/openqa/share/factory nfs ro 0 0 - ZFCP disk:
/dev/mapper/$ID /var/lib/libvirt/images ext4 nobarrier,data=writeback 1
Additionally execute echo 'roles: libvirt' >> /etc/salt/grains and apply the state from https://github.com/os-autoinst/salt-states-openqa/tree/master/libvirt
Take machines out of salt-controlled production¶
E.g. for investigation or development or manual maintenance work
ssh osd "sudo salt-key -y -d $hostname"
ssh $hostname "sudo systemctl disable --now telegraf $(systemctl list-units | grep openqa-worker-auto-restart | cut -d . -f 1 | xargs)"
If you also want to remove all alerts related to that machine, consider to execute https://gitlab.suse.de/openqa/salt-states-openqa/-/blob/master/monitoring/grafana/cleanup_stale_alerts.sh on monitor.qa.suse.de like so (adjust the parameters at the end with appropriately privileged account credentials):
Caution: This will remove all alerts currently present in Grafana but not provisioned (e.g. manually created ones)
ssh -t root@monitor.qa.suse.de "curl https://gitlab.suse.de/openqa/salt-states-openqa/-/raw/master/monitoring/grafana/cleanup_stale_alerts.sh | bash -s -- USERNAME PASSWORD"
Checkout salt-states-openqa's examples for systemd commands to start and stop workers.
How to use samba shares to mount ISOs as virtual CD drives with SuperMicro server/mainboards¶
SuperMicro based servers have the capabilities to mount smb shares containing ISOs as virtual CD drives to e.g. boot from them.
Install the samba package on any machine you control. This also works from your personal workstation if the server can access it (e.g. over VPN) and create the following /etc/samba/smb.conf:
[global]
workgroup = MYGROUP
server string = Samba Server
log level = 3
client min protocol = core
server min protocol = core
guest ok = yes
## "Staging" test instances
SUSE internally we have two virtual machines that can be used for testing, developing, showcasing, reachable under convenient URLs:
* https://openqa-staging-1.qe.nue2.suse.org
* https://openqa-staging-2.qe.nue2.suse.org
You can use those machines and apply changes as desired over ssh.
#============================ Share Definitions ==============================
[recovery]
comment = recovery
path = /home/you/recovery
public = yes
Now start the samba service. Despite the share being accessible by everyone (be carful about this!), the SuperMicro machines still need a User on the Samba server as they don't support anonymous login. To create a user without requiring a local unix user, you can use the following command:
samba-tool domain provision --use-rfc2307 --interactive
afterwards create a user in the samba database with:
smbpasswd -a smbtest
Now it should be possible to access the share. Place an ISO file into your folder configured above and use the following settings in the webui of the SuperMicro server:
"Share Host": IP of your machine running samba
"Path to Image": Path to your ISO inside the share, e.g. "\recovery\some_boot_medium.iso" (mind the backslashes!)
"Users": The username from your just created user
"Password": It's password - don't keep this empty as it will not work otherwise
After clicking on "mount" you should now see a connection to your samba server. The machine will try to mount the ISO and if everything goes well, will report "There is an iso file mounted." in the "Health Status" of the Devices.
Bring back machines into salt-controlled production¶
ssh osd "sudo salt-key -y -a $hostname && sudo salt --state-output=changes $hostname state.apply"
Depending on your actions further manual cleanup might be necessary, e.g. ssh $hostname "sudo systemctl unmask telegraf salt-minion"
Access the BMC of machines in the SUSE network zones¶
One can use ssh portforwarding to access the services of a BMC (e.g. web interface) for a machine in the "oqa" network security zone. The host "oqa-jumpy" can be used for that like this:
ssh -t jumpy@oqa-jumpy.dmz-prg2.suse.org -L 8443:openqaworker21.oqa-ipmi-ur:443 -L 8080:openqaworker21.oqa-ipmi-ur:80
while the ssh-session is running you can then use your local browser to access the remote host by e.g. "http://localhost:8080" or "https://localhost:8443".
Using the build-in java tools of BMCs to access machines in the security zone¶
1. Follow Access the BMC of machines in the new security zone to download the build-in java webstart file of the machine you want to control
2. Use nmap on oqa-jumpy to scan for all ports of a machines BMC. Example:
jumpy@oqa-jumpy:~> nmap openqaworker21.oqa-ipmi-ur -p-
Starting Nmap 7.70 ( https://nmap.org ) at 2023-01-17 12:23 UTC
Nmap scan report for openqaworker21.oqa-ipmi-ur (…)
Host is up (0.0056s latency).
Not shown: 65525 closed ports
PORT STATE SERVICE
22/tcp open ssh
80/tcp open http
199/tcp open smux
427/tcp open svrloc
443/tcp open https
623/tcp open oob-ws-http
5120/tcp open barracuda-bbs
5122/tcp open unknown
5123/tcp open unknown
7578/tcp open unknown
3. Forward all ports relevant for the java applet to your local machine:
sudo ssh -i /home/nicksinger/.ssh/id_rsa.SUSE -4 jumpy@oqa-jumpy.suse.de -L 443:openqaworker21.oqa-ipmi-ur:443 -L 623:openqaworker21.oqa-ipmi-ur:623 -L 5120:openqaworker21.oqa-ipmi-ur:5120 -L 5122:openqaworker21.oqa-ipmi-ur:5122 -L 5123:openqaworker21.oqa-ipmi-ur:5123 -L 7578:openqaworker21.oqa-ipmi-ur:7578
Note 1: You have to use the exact same ports as shown by the port scan because you cannot instruct the applet to use different ports
Note 2: You have to execute your ssh client with root privileges for it to be able to bind to ports below 1024. These forwardings need to be present for the applet being able to download additional files from the BMC
Note 3: Make sure to point to your right keyfile by using the -i parameter as ssh will scan different directories if run as root
4. Execute the previously downloaded applet. I use the following command to make it work with wayland:
LANG=C _JAVA_AWT_WM_NONREPARENTING=1 javaws -nosecurity -jnlp jviewer\ \(1\).jnlp
5. You should now be able to control the machine/BMC with all its features (e.g. mounting ISO images as virtual CD)
Use a production host for testing backend changes locally, e.g. svirt, powerVM, IPMI bare-metal, s390x, etc.¶
- Find out which type of worker slot you need for the specific job you want to run, e.g. by checking which worker slots were used for previous runs of the job on OSD or by looking for the job's worker class in the workers table.
- Configure an additional worker slot in your local
workers.iniusing worker settings from the corresponding production worker. The production worker config can be found in workerconf.sls or on the hosts themselves. - Take out the corresponding worker slot from production using the systemd commands mentioned in salt-states-openqa's examples. This is important to prevent multiple jobs from using the same svirt host.
- Start the locally configured worker slot and clone/run some jobs.
- When you're done, bring back the production worker slots using the systemd commands mentioned in salt-states-openqa's examples.
Alternatives¶
It is also possible to test svirt backend changes fully locally, at least when running tests via KVM is sufficient. Checkout os-autoinst's documentation for further details.
Dealing with XEN servers¶
The Domain-0 is more or less the host system (actually it is a VM with special permissions).
Other than for KVM virtualisation, on XEN you need to explicitly allocate RAM to the Host (Domain-0) as well.
You can see the existing allocations for all VMs including Domain-0 using xl list.
To change the memory allocation for Dom-0, update /etc/default/grub like this, run update-bootloader and reboot.
GRUB_CMDLINE_XEN_DEFAULT="console=com3 com3=115200 dom0_mem=3072M,max:3072M loglvl=all guest_loglvl=all loglvl=all guest_loglvl=all"
Note that in the Dom-0 the free -m command will not show the total host memory but only the memory allocated to Dom-0.
The total host memory can be displayed using xl info.
Also note that the /proc/cmdline in Dom-0 doesn't show the kernel cmdline specified by the bootloader. That can only be seen via xl info as well.
The autoballoon setting in /etc/xen/xl.conf can be used to dynamically allocate memory to the Dom-0, decreasing it whenever a VM is started.
Dealing with PowerEdge SAP servers from Dell¶
Acessing the management interface via SSH¶
It is possible to access the management interface via SSH as well (using the same user name and password as for the web interface). Checkout further Wiki sections for useful commands or the manual which is also availabe as web page.
One very useful pair of commands are racadm get and … set which allow reading and writing configuration values, e.g. racadm get iDRAC.NIC.DNSRacName and racadm set iDRAC.NIC.DNSRacName somevalue.
Restoring access to the iDRAC web interface¶
If iDRAC returns a 400 error it might be due to a wrong DNS setting. This is especially likely if you have just changed the DNS entry. Try to access iDRAC via its IP which should still work. Then goto iDRAC settings -> Network -> General settings and update the DNS iDRAC name to match the not fully qualified domain (e.g. qesapworker-prg4-mgmt for https://qesapworker-prg4-mgmt.qa.suse.cz).
You may also change this setting by accessing the management interface via SSH. The command would be racadm set iDRAC.NIC.DNSRacName qesapworker-prg4-mgmt in this case. You may also use racadm set idrac.webserver.HostHeaderCheck 0 to get rid of this entire check completely. This is especially useful if you cannot conveniently put in a matching name, e.g. when accessing the web UI via SSH forwarding.
Recovering BIOS¶
If the BIOS appears completely broken (e.g. after a firmware update) you may try to invoke racadm systemerase bios after accessing the management interface via SSH. This will take a while and afterwards you'll have to redo settings (e.g. the bootmode).
Cancel/delete stuck iDRAC jobs¶
Invoke racadm jobqueue delete -i JID_CLEARALL_FORCE after accessing the management interface via SSH.
Check status of BOSS-S2 NVMe disks¶
Use the "MVCLI BOSS-S2" utility from Dell which you can download from their servers (see https://www.dell.com/support/manuals/de-de/poweredge-r6525/boss-s2_ug/run-boss-s2-cli-commands-on-poweredge-servers-running-the-linux-operating-system?guid=guid-c0f3bd0d-4725-4fed-8bc2-4aa872f3627f&lang=en-us).
Firmware updates¶
The easiest way is to download the Windows installer (a file that ends with .EXE) and upload and install that via the iDRAC web interface. This also works for updates of iDRAC but also for BIOS updates and firmware of various components. Uploading the GNU/Linux version (a file that ends with .BIN) is not possible this way. One can track the progress of those updates via the iDRAC job queue. It is possible to schedule two updates that require a reboot at the same time (e.g. BIOS update and SAS-RAID firmware) and do them this way in one go.
Backup¶
Both openqa.opensuse.org and openqa.suse.de run on virtual machine clusters that provide redundancy and differential backup using snapshotting of the involved storage. SUSE-IT currently provides backups going back up to 3 days with two daily backups conducted at 23:10Z and 11:00Z. With this it is possible in cases of catastrophic data loss to recover (raise ticket over https://sd.suse.com in that case). Additionally automatic backup for the o3 webui host introduced with https://gitlab.suse.de/okurz/backup-server-salt/tree/master/rsnapshot covering so far /etc and the SQL database dumps. Fixed assets and testresults are backed up on storage.qe.prg2.suse.org (see https://gitlab.suse.de/openqa/salt-states-openqa/-/merge_requests/612)
openQA database backups¶
Database backups of o3+osd are available on backup.qa.suse.de, acessible over ssh, same credentials as for the OSD infrastructure
Fallback deployment on AWS¶
To get an instance running from a backup in case of a disaster, one can be created on AWS with this configuration:
Launch instance¶
Web Interface, from scratch (only if necessary, otherwise just use the template below)¶
- Ensure your region is Frankfurt, Germany
- Pick a t3.large with
openSUSE Leapon AWS Marketplace - Add two disks
- 10 GiB for the root filesystem should be sufficient (can be easily extended later if needed)
- The OSD database alone needs > 30 GiB and results plus assets will also need a lot (e.g. > 4 GiB for TW snapshot ISO) so take at least 100 GiB for the 2nd drive
- The security group needs to include ssh and http
- Add
openqa_created_by,openqa_ttlandteam:qa-toolstags
Launch from a template¶
Note: When you modify the template (creating a new version), be sure to set the new version as the default.
- Go to the openQA-webUI-openSUSE-Leap Template
- Select "Actions - Launch instance from template"
- Choose your key pair
- Click "Launch instance"
Command line¶
For configuring aws cli, see below
aws ec2 run-instances --launch-template LaunchTemplateId=lt-002dfbcbd2f818e4c --key-name <your-keyname>
# or
aws ec2 run-instances --launch-template LaunchTemplateName=openQA-webUI-openSUSE-Leap --key-name <your-keyname>
For this you have to create a key pair first, if you haven't done so.
Save the result and look for the InstanceId.
Transfer keys¶
Since an instance is always created with a single key, public keys of all users need to be deployed by whoever owns that key.
Note: osd2 refers to the instance created above. Replace with the instance IP or add an alias to your SSH config.
ssh openqa.suse.de "sudo su -c 'cat /home/*/.ssh/authorized_keys'" | ssh ec2-user@osd2 "cat - >> ~/.ssh/authorized_keys"
Bootstrapping¶
ssh osd2
sudo su
parted --script /dev/nvme1n1 mklabel gpt && parted --script /dev/nvme1n1 mkpart ext4 4096s 100%
mkfs.ext4 /dev/nvme1n1p1
vim /etc/fstab # add mount to fstab
mkdir /space && mount /dev/nvme1n1p1 /space
mkdir -p /space/pgsql/data
mkdir -p /var/lib/pgsql
ln -s /space/pgsql/data /var/lib/pgsql/data
zypper in postgresql-server # needed for user.group
chown -R postgres.postgres /space/pgsql # without correct group postgresql.service fails
mkdir -p /space/openqa
mkdir -p /var/lib/openqa
mount /space/openqa /var/lib/openqa -o bind # open also requires a lot of space
curl -s https://raw.githubusercontent.com/os-autoinst/openQA/master/script/openqa-bootstrap | bash -x
ssh -A backup.qa.suse.de
rsync --progress /home/rsnapshot/alpha.0/openqa.suse.de/var/lib/openqa/SQL-DUMPS/2022-02-08.dump ec2-user@osd2:/tmp
ssh osd2
sudo -u postgres createdb -O geekotest openqa-osd # create pristine db for OSD import (to avoid conflicts with existing data)
sudo -u geekotest pg_restore -d openqa-osd /tmp/2022-02-08.dump # import data, will take a while (22m is a realistic time)
vim /etc/openqa/openqa.ini # change auth from Fake to OpenID
vim /etc/openqa/database.ini # change database to openqa-osd
vim /etc/openqa/client.conf # change key and secret to correct one
systemctl restart openqa-webui
Configure aws cli¶
You can use the command
aws configure
but it doesn't actually help you with the possible values, so you can just create the file yourself like this:
% cat ~/.aws/config
[default]
region = eu-central-1
output = json
% cat ~/.aws/credentials
[default]
aws_access_key_id = ABCDE
aws_secret_access_key = FGHIJ
Best practices for infrastructure work¶
- Same as in OSD deployment we should look for failed grafana alerts if users report something suspicious
- Collect all the information between "last good" and "first bad" and then also find the git diff in openqa/salt-states-openqa
- Apply proper "scientific method" with written down hypotheses, experiments and conclusions in tickets, follow https://progress.opensuse.org/projects/openqav3/wiki#Further-decision-steps-working-on-test-issues
- Keep salt states to describe what should not be there
- Try out older btrfs snapshots in systems for crosschecking and boot with disabled salt. In the kernel cmdline append
systemd.mask=salt-minion.service - Team should conduct a work backlog check on a daily base, e.g. look for urgent tickets related to infrastructure problems
- For hardware component replacement, create EngInfra ticket for coordination, order replacement on private expenses and get reimbursed using https://intra.suse.net/company/company-news/department/finance/claim-expenses/claim-expenses/ or have order placed with the help of line managers, let the components be delivered to the according place, e.g. SUSE Nuremberg datacenter and inform EngInfra in ticket to have them conduct the physical component replacement
- For ordering new machines follow https://mysuse.sharepoint.com/sites/SUSEBusinessCriticalLinux/Shared%20Documents/Hardware%20Order/E&I%20Hardware.pdf (get quotes from vendor, create ticket with procurement, CC osd-admins+mgriessmeier, wait for purchase order (PO) approval, order with vendor and ask them to include PO number in invoice)
- Prefer
reloadoverrestartwhere available e.g.systemctl reload postgres- in generalsystemctl cat postgreswill show available commands for any service - On boot problems, e.g. trying to fix broken bootloader, consider using a virtual machine like
qemu-system-x86_64 -m 8192 -snapshot -hda /dev/vda -nographic -serial mon:stdio -smp 4which tries to boot from the first storage device but keeping the physical device untouched due to the-snapshotparameter - Test reboot stability of machines with commands like https://github.com/os-autoinst/scripts/blob/master/reboot-stability-check
Automatic submission of packages¶
Every commit to the master branch of the git repositories of https://github.com/os-autoinst/os-autoinst and https://github.com/os-autoinst/openQA is considered a stable release and triggers package builds within https://build.opensuse.org/project/show/devel:openQA, in particular https://build.opensuse.org/package/show/devel:openQA/os-autoinst and https://build.opensuse.org/package/show/devel:openQA/openQA. http://jenkins.qa.suse.de/job/trigger-openQA_in_openQA-TW/ using https://github.com/os-autoinst/scripts/blob/master/trigger-openqa_in_openqa is monitoring the download repositories for new versions and triggers openQA-in-openQA tests as visible on https://openqa.opensuse.org/group_overview/24 . http://jenkins.qa.suse.de/job/monitor-openQA_in_openQA-TW/ monitors the test execution using https://github.com/os-autoinst/scripts/blob/master/monitor-openqa_job and on test success triggers http://jenkins.qa.suse.de/job/submit-openQA-TW-to-oS_Fctry/ periodically (with a build throttle as decided together with openSUSE reviewers) using https://github.com/os-autoinst/scripts/blob/master/os-autoinst-obs-auto-submit. This step prepares openQA related packages for automatic submission into openSUSE:Factory in https://build.opensuse.org/project/show/devel:openQA:tested, awaits build+check results and then creates automatic submissions to openSUSE:Factory for inclusion of packages into openSUSE Tumbleweed. This approach could also be extended for automatic submission to openSUSE Leap, SLE PackageHub or directly to SLE using maintenance updates based on a configurable schedule with additional check steps as applicable. Given that openQA are developed based on a rolling-release model with no maintenance branches any updates to base products supporting openQA would be new version updates along with dependency package updates as necessary.
Updated by robert.richardson 30 days ago · 316 revisions