action #163592
closed[alert] (HTTP Response alert Salt tm0h5mf4k) size:M
0%
Description
Observation¶
We saw several alerts this morning:
http://stats.openqa-monitor.qa.suse.de/alerting/grafana/tm0h5mf4k/view?orgId=1
Date: Wed, 10 Jul 2024 04:45:31 +0200
Suggestions¶
- DONE Reduce global job limit
- DONE Consider mitigations for route causing the overload (real fix is in place now)
- Actively monitor while mitigations are applied
- Repeatedly: Retrigger affected jobs when applicable
- Handle communication with affected users and downstream services
- strace on relevant processes (of openqa-webui.service). That helped us to define #163757
- After #163757 continue to closely monitor the system and then slowly and carefully conduct the rollback actions
- Ensure that https://stats.openqa-monitor.qa.suse.de/d/WebuiDb/webui-summary?viewPanel=78&orgId=1&from=now-7d&to=now
stays stable - Consider temporarily disabling pg_dump triggered by the regular backup
Rollback actions¶
-
DONE
Manual changes to-> reverted back to original code with deployment of 2024-07-12 for #163757/usr/share/openqa/lib/OpenQA/WebAPI.pmon osd -
DONE
enable https://gitlab.suse.de/openqa/osd-deployment/-/pipeline_schedules again -
DONE
sudo systemctl start auto-update.timeron osd -
DONE Enable the backup via
pg_dumpon OSD again by runningsudo ln -fs /usr/lib/postgresql16/bin/pg_dump /etc/alternatives/pg_dumpon OSD (to revert the experiment done in #163592#note-41)
Out of scope¶
Files
| Screenshot_20240720_170312_openqa_osd_load_during_3x_nice_pg_dump_3x_not-nice_pg_dump.png (193 KB) Screenshot_20240720_170312_openqa_osd_load_during_3x_nice_pg_dump_3x_not-nice_pg_dump.png |
Updated by okurz 11 months ago
- Related to action #163595: [alert] (Web proxy Response Time alert Salt IeChie2He) added
Updated by livdywan 11 months ago
- Status changed from New to In Progress
- Assignee set to livdywan
- Priority changed from Immediate to Urgent
The issue, some workers getting stuck, seems to have been resolved for now. See https://stats.openqa-monitor.qa.suse.de/d/WebuiDb/webui-summary?viewPanel=78&orgId=1
There's incompletes due to connectivity issues, see https://monitor.qa.suse.de/d/nRDab3Jiz/openqa-jobs-test?orgId=1
@mkittler is looking into restarting affected incompletes.
I didn't spot any failures that aren't incompletes from manually going through jobs at least.
Updated by okurz 11 months ago
- Copied to action #163610: Conduct "lessons learned" with Five Why analysis for "[alert] (HTTP Response alert Salt tm0h5mf4k)" added
Updated by livdywan 11 months ago
Decided to hotpatch /usr/share/openqa/lib/OpenQA/WebAPI.pm and uncomment the streaming route as the live view seems to be the underlying cause and we can't currently limit it, meaning a high enough number of live viewers is enough to break the web UI.
This is not persistent as of now.
A long-term solution may be making the live view a separate service so it can't block other requests.
Updated by livdywan 11 months ago
This is not persistent as of now.
https://gitlab.suse.de/openqa/osd-deployment/-/pipeline_schedules is also inactive as of right now to avoid the hotpatch from being reverted.
Updated by livdywan 11 months ago
This is not persistent as of now.
https://gitlab.suse.de/openqa/osd-deployment/-/pipeline_schedules is also inactive as of right now to avoid the hotpatch from being reverted.
Also sudo systemctl stop auto-update.timer
Updated by livdywan 11 months ago
- Related to action #162038: No HTTP Response on OSD on 10-06-2024 - auto_review:".*timestamp mismatch - check whether clocks on the local host and the web UI host are in sync":retry size:S added
Updated by okurz 11 months ago
- Related to action #163622: Scripts CI pipeline failing with invalid numeric literal error size:S added
Updated by openqa_review 11 months ago
- Due date set to 2024-07-25
Setting due date based on mean cycle time of SUSE QE Tools
Updated by livdywan 11 months ago
- Related to action #163757: Prevent live view viewers from making openQA unresponsive added
Updated by livdywan 11 months ago
- Status changed from In Progress to Workable
- Assignee deleted (
livdywan)
okurz wrote in #note-18:
I suggest you don't given how many problems show up over the day. We need you to handle the symptoms and actively monitor the execution of jobs
As far as I can tell we are not seeing this issue right now and I am trying to keep issues distinct so that we have a chance of addressing them individually. Maybe you didn't see my other updates on relevant tickets.
If you think there is currently a related issue here that's not covered in other tickets, please point it out accordingly.
Updated by okurz 11 months ago
- Related to action #163772: [openQA][ipmi][worker35:x] Assigned jobs hang and actually can not run size:M added
Updated by livdywan 11 months ago · Edited
I'm seeing a lot of these messages:
Jul 11 16:45:01 openqa openqa[1576]: [error] Publishing suse.openqa.job.create failed: Connect timeout (7 attempts left)
[...]
Jul 11 17:24:47 openqa openqa[30656]: [error] Publishing suse.openqa.job.create failed: Connect timeout (5 attempts left)
Also a lot of these errors, which I was also wondering if they were affecting #162038#note-19 except I don't know what they mean:
Jul 11 16:48:21 openqa wickedd[912]: rtnetlink event receive error: Out of memory (No buffer space available)
Jul 11 16:48:21 openqa wickedd[912]: restarted rtnetlink event listener
Updated by okurz 11 months ago
- Copied to action #163790: OSD openqa.ini is corrupted, invalid characters size:M added
Updated by okurz 11 months ago
- Description updated (diff)
https://monitor.qa.suse.de/d/WebuiDb/webui-summary?orgId=1&from=1720687039221&to=1720719386538 shows excessively high response times during today so we are definitely not ok. I also observed that the config file on OSD openqa.ini was corrupted meaning that also some settings were not used. I created #163790 for that specifically and repaired the file and restarted the openQA webUI.
I still assume that the actions done in #159396 might have an effect. I suggest to temporarily disable taking the database backup to observe if that helps.
Updated by livdywan 11 months ago
- Due date deleted (
2024-07-25) - Status changed from In Progress to Workable
- Assignee deleted (
livdywan)
I'm not currently observing related issues. It would be great to estimate the ticket to come up with a plan on what can be done here, either based on my findings or other ideas I couldn't come up with.
Updated by mkittler 11 months ago
There are not many incompletes as of today:
openqa=> select count(id), array_agg(id), reason from jobs where t_finished >= '2024-07-12T00:00:00' and result = 'incomplete' group by reason order by count(id) desc;
count | array_agg |
reason
-------+------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
15 | {14907486,14908052,14908265,14908038,14908189,14907472,14907444,14907764,14908087,14908089,14908013,14908232,14908020,14907691,14907493} | api failure: 502 response: Bad Gateway
11 | {14911322,14911454,14911321,14911265,14911203,14907686,14910421,14911434,14911437,14911451,14911105} | tests died: unable to load main.pm, check the log for the cause (e.g. syntax error)
7 | {14912021,14907393,14908650,14907389,14908659,14908639,14908671} | cache failure: Failed to download SLE-15-SP5-Full-x86_64-GM-Media1.iso to /var/lib/openqa/cache/openqa.suse.de/SLE-15-SP5-Full-x86_64-GM-Media1.iso [Auto-restarting bec
ause reason matches the configured "auto_clone_regex".]
7 | {14904395,14908635,14904400,14910543,14907819,14909239,14910628} | backend died: QEMU exited unexpectedly, see log for details
4 | {14908227,14908325,14908716,14908823} | backend died: QEMU terminated before QMP connection could be established. Check for errors below
2 | {14907730,14910524} | tests died: unable to load tests/network/samba/samba_adcli.pm, check the log for the cause (e.g. syntax error)
2 | {14909169,14910545} | asset failure: Failed to download autoyast_SLES-15-SP5-x86_64-create_hdd_yast_maintenance_minimal-Build20240711-1-Server-DVD-Updates-64bit.qcow2 to /var/lib/openqa/cach
e/openqa.suse.de/autoyast_SLES-15-SP5-x86_64-create_hdd_yast_maintenance_minimal-Build20240711-1-Server-DVD-Updates-64bit.qcow2
2 | {14908644,14908631} | cache failure: Failed to download SLE-15-SP3-Full-x86_64-GM-Media1.iso to /var/lib/openqa/cache/openqa.suse.de/SLE-15-SP3-Full-x86_64-GM-Media1.iso [Auto-restarting bec
ause reason matches the configured "auto_clone_regex".]
2 | {14908247,14908234} | cache failure: Failed to download supp_sles12sp5-x86_64.qcow2 to /var/lib/openqa/cache/openqa.suse.de/supp_sles12sp5-x86_64.qcow2 [Auto-restarting because reason matche
s the configured "auto_clone_regex".]
2 | {14906823,14906891} | died: terminated prematurely, see log output for details
1 | {14911446} | backend died: Error connecting to VNC server <s390kvm110.oqa.prg2.suse.org:5901>: IO::Socket::INET: connect: No route to host
1 | {14877886} | abandoned: associated worker worker29:6 re-connected but abandoned the job
1 | {14903610} | abandoned: associated worker sapworker3:22 re-connected but abandoned the job
1 | {14909708} | backend died: unexpected end of data at /usr/lib/os-autoinst/consoles/VNC.pm line 842.
1 | {14906618} | abandoned: associated worker openqaworker-arm-1:1 re-connected but abandoned the job
1 | {14906515} | abandoned: associated worker openqaworker-arm-1:7 re-connected but abandoned the job
1 | {14907413} | cache failure: Failed to download SLE-15-SP5-x86_64-Build20240711-1-qam-sles4sap-gnome.qcow2 to /var/lib/openqa/cache/openqa.suse.de/SLE-15-SP5-x86_64-Build20240711-1-q
am-sles4sap-gnome.qcow2 [Auto-restarting because reason matches the configured "auto_clone_regex".]
1 | {14907521} | cache failure: Failed to download SLES-12-SP3-x86_64-20240711-1@64bit-minimal_with_sdkGM_xfstests.qcow2 to /var/lib/openqa/cache/openqa.suse.de/SLES-12-SP3-x86_64-20240
711-1@64bit-minimal_with_sdkGM_xfstests.qcow2 [Auto-restarting because reason matches the configured "auto_clone_regex".]
1 | {14908653} | cache failure: Failed to download SLES-15-SP2-x86_64-mru-install-desktop-with-addons-Build20240711-1.qcow2 to /var/lib/openqa/cache/openqa.suse.de/SLES-15-SP2-x86_64-mr
u-install-desktop-with-addons-Build20240711-1.qcow2 [Auto-restarting because reason matches the configured "auto_clone_regex".]
1 | {14908685} | cache failure: Failed to download SLES-15-SP2-x86_64-mru-install-minimal-with-addons-Build20240711-1-Server-DVD-Updates-64bit.qcow2 to /var/lib/openqa/cache/openqa.suse
.de/SLES-15-SP2-x86_64-mru-install-minimal-with-addons-Build20240711-1-Server-DVD-Updates-64bit.qcow2 [Auto-restarting because reason matches the configured "auto_clone_regex".]
1 | {14907914} | cache failure: Failed to download openqa_support_server_sles12sp3_multipath.x86_64.qcow2 to /var/lib/openqa/cache/openqa.suse.de/openqa_support_server_sles12sp3_multipa
th.x86_64.qcow2 [Auto-restarting because reason matches the configured "auto_clone_regex".]
1 | {14912120} | asset failure: Failed to download autoyast-SLES-15-SP5-x86_64-textmode-updated.qcow2 to /var/lib/openqa/cache/openqa.suse.de/autoyast-SLES-15-SP5-x86_64-textmode-update
d.qcow2
1 | {14895992} | abandoned: associated worker openqaworker-arm-1:3 re-connected but abandoned the job
1 | {14912123} | asset failure: Failed to download publiccloud_15-SP2_Azure-BYOS-Updates-x86_64.qcow2 to /var/lib/openqa/cache/openqa.suse.de/publiccloud_15-SP2_Azure-BYOS-Updates-x86_6
4.qcow2
1 | {14911432} | backend died: Error connecting to VNC server <s390kvm105.oqa.prg2.suse.org:5901>: IO::Socket::INET: connect: No route to host
(25 rows)
In particular, there are no further incompletes due to unknown API errors, "premature connection close" or due to timestamp mismatches.
Yesterday it was a whole different story:
openqa=> select count(id), reason from jobs where t_finished >= '2024-07-11T00:00:00' and t_finished < '2024-07-12T00:00:00' and result = 'incomplete' group by reason order by count(id) desc limit 10;
count | reason
-------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
150 | api failure
67 | api failure: Connection error: Premature connection close
36 | api failure: 403 response: timestamp mismatch - check whether clocks on the local host and the web UI host are in sync
24 | quit: worker has been stopped or restarted
20 | cache failure: Failed to download SLE-15-SP4-Full-x86_64-GM-Media1.iso to /var/lib/openqa/cache/openqa.suse.de/SLE-15-SP4-Full-x86_64-GM-Media1.iso [Auto-restarting because reason matches the configured "auto_clone_regex".]
15 | isotovideo died: Unable to clone Git repository 'https://github.com/frankenmichl/os-autoinst-distri-opensuse/tree/nfs_baremetal' specified via CASEDIR (see log for details) at /usr/lib/os-autoinst/OpenQA/Isotovideo/Utils.pm line 164.
14 | cache failure: Failed to download SLE-15-SP5-Full-x86_64-GM-Media1.iso to /var/lib/openqa/cache/openqa.suse.de/SLE-15-SP5-Full-x86_64-GM-Media1.iso [Auto-restarting because reason matches the configured "auto_clone_regex".]
10 | api failure: Connection error: Connection timed out
9 | cache failure: Failed to download SLE-15-SP6-Full-x86_64-GM-Media1.iso to /var/lib/openqa/cache/openqa.suse.de/SLE-15-SP6-Full-x86_64-GM-Media1.iso [Auto-restarting because reason matches the configured "auto_clone_regex".]
9 | asset failure: Failed to download sle-15-SP6-x86_64-GM-with-hpc.qcow2 to /var/lib/openqa/cache/openqa.suse.de/sle-15-SP6-x86_64-GM-with-hpc.qcow2
Updated by openqa_review 11 months ago
- Due date set to 2024-07-27
Setting due date based on mean cycle time of SUSE QE Tools
Updated by mkittler 11 months ago · Edited
Note that all timestamps in the following comment from Grafana and the journal are CEST and all timestamps from the database UTC.
The alert was firing again today from 2024-07-15 01:00:09 to 2024-07-15 01:01:02 (https://stats.openqa-monitor.qa.suse.de/d/WebuiDb/webui-summary?orgId=1&viewPanel=78&from=1720993478167&to=1721003987228). Otherwise there were no further alerts over the weekend (also no pending ones).
I investigated the logs which are also attached to #163928.
The websocker server is very verbose so the first thing to notice are the many "Finishing current connection of worker … before accepting new one" messages:
Jul 15 01:04:33 openqa openqa-websockets-daemon[16477]: [debug] [pid:16477] Finishing current connection of worker 3016 before accepting new one
Jul 15 01:04:33 openqa openqa-websockets-daemon[16477]: [debug] [pid:16477] Finishing current connection of worker 2396 before accepting new one
Jul 15 01:04:33 openqa openqa-websockets-daemon[16477]: [info] [pid:16477] Worker 2558 websocket connection closed - 1008: only one connection per worker allowed, finishing old one in favor of new one
Jul 15 01:04:33 openqa openqa-websockets-daemon[16477]: [info] [pid:16477] Worker 3511 websocket connection closed - 1008: only one connection per worker allowed, finishing old one in favor of new one
And also:
Jul 15 01:04:34 openqa openqa-websockets-daemon[16477]: [info] [pid:16477] Received worker 3016 status too close to the last update, websocket server possibly overloaded or worker misconfigured
…
Jul 15 01:04:34 openqa openqa-websockets-daemon[16477]: [info] [pid:16477] Received worker 2559 status too close to the last update, websocket server possibly overloaded or worker misconfigured
…
This could be relevant - although this is just about the web socket server and should not impact normal API queries.
It looks like many services were started at this time and also asset cleanup was enqueued (but of course none of this is very unusual):
Jul 15 01:00:00 openqa systemd[1]: Starting Setup local PostgreSQL database for openQA...
Jul 15 01:00:00 openqa systemd[1]: Started Timeline of Snapper Snapshots.
Jul 15 01:00:00 openqa openqa-websockets-daemon[16477]: [debug] [pid:16477] Started to send message to 3080 for job(s) 14929376
Jul 15 01:00:00 openqa systemd[1]: Starting Rotate openQA log files...
Jul 15 01:00:00 openqa bash[7702]: ++ /usr/bin/systemctl is-active logrotate.service
Jul 15 01:00:00 openqa bash[7697]: + is_active=inactive
Jul 15 01:00:00 openqa bash[7697]: + [[ inactive == active ]]
Jul 15 01:00:00 openqa bash[7697]: + [[ inactive == activating ]]
Jul 15 01:00:00 openqa bash[7697]: + exit 0
Jul 15 01:00:00 openqa logrotate[7711]: reading config file /etc/logrotate.d/openqa
Jul 15 01:00:00 openqa logrotate[7711]: warning: 'size' overrides previously specified 'hourly'
Jul 15 01:00:00 openqa logrotate[7711]: compress_prog is now /usr/bin/xz
Jul 15 01:00:00 openqa logrotate[7711]: compress_ext was changed to .xz
Jul 15 01:00:00 openqa logrotate[7711]: uncompress_prog is now /usr/bin/xzdec
Jul 15 01:00:00 openqa logrotate[7711]: warning: 'size' overrides previously specified 'hourly'
Jul 15 01:00:00 openqa logrotate[7711]: compress_prog is now /usr/bin/xz
Jul 15 01:00:00 openqa logrotate[7711]: compress_ext was changed to .xz
Jul 15 01:00:00 openqa logrotate[7711]: uncompress_prog is now /usr/bin/xzdec
Jul 15 01:00:00 openqa dbus-daemon[813]: [system] Activating via systemd: service name='org.opensuse.Snapper' unit='snapperd.service' requested by ':1.171923' (uid=0 pid=7696 comm="/usr/lib/snapper/systemd-helper --timeline ")
Jul 15 01:00:00 openqa logrotate[7711]: reading config file /etc/logrotate.d/openqa-apache
Jul 15 01:00:00 openqa logrotate[7711]: warning: 'size' overrides previously specified 'hourly'
Jul 15 01:00:00 openqa logrotate[7711]: compress_prog is now /usr/bin/xz
Jul 15 01:00:00 openqa logrotate[7711]: compress_ext was changed to .xz
Jul 15 01:00:00 openqa logrotate[7711]: uncompress_prog is now /usr/bin/xzdec
Jul 15 01:00:00 openqa logrotate[7711]: Reading state from file: /var/lib/misc/logrotate.status
Jul 15 01:00:00 openqa logrotate[7711]: Allocating hash table for state file, size 64 entries
Jul 15 01:00:00 openqa logrotate[7711]: Creating new state
Jul 15 01:00:00 openqa logrotate[7711]: Creating new state
…
Jul 15 01:00:00 openqa logrotate[7711]: Creating new state
Jul 15 01:00:00 openqa openqa-websockets-daemon[16477]: [debug] [pid:16477] Started to send message to 3242 for job(s) 14929949
Jul 15 01:00:00 openqa systemd[1]: Starting DBus interface for snapper...
Jul 15 01:00:00 openqa logrotate[7711]: Creating new state
…
Jul 15 01:00:00 openqa logrotate[7711]: Creating new state
Jul 15 01:00:00 openqa logrotate[7711]: Handling 3 logs
Jul 15 01:00:00 openqa logrotate[7711]: rotating pattern: /var/log/openqa 307200000 bytes (20 rotations)
Jul 15 01:00:00 openqa logrotate[7711]: empty log files are not rotated, old logs are removed
Jul 15 01:00:00 openqa logrotate[7711]: considering log /var/log/openqa
Jul 15 01:00:00 openqa logrotate[7711]: Now: 2024-07-15 01:00
Jul 15 01:00:00 openqa logrotate[7711]: Last rotated at 2024-06-17 08:00
Jul 15 01:00:00 openqa logrotate[7711]: log does not need rotating (log size is below the 'size' threshold)
Jul 15 01:00:00 openqa logrotate[7711]: rotating pattern: /var/log/openqa_scheduler /var/log/openqa_gru 30720000 bytes (20 rotations)
Jul 15 01:00:00 openqa logrotate[7711]: empty log files are not rotated, old logs are removed
Jul 15 01:00:00 openqa logrotate[7711]: considering log /var/log/openqa_scheduler
Jul 15 01:00:00 openqa logrotate[7711]: Now: 2024-07-15 01:00
Jul 15 01:00:00 openqa logrotate[7711]: Last rotated at 2024-07-14 08:00
Jul 15 01:00:00 openqa logrotate[7711]: log does not need rotating (log size is below the 'size' threshold)
Jul 15 01:00:00 openqa logrotate[7711]: considering log /var/log/openqa_gru
Jul 15 01:00:00 openqa logrotate[7711]: Now: 2024-07-15 01:00
Jul 15 01:00:00 openqa logrotate[7711]: Last rotated at 2024-07-13 02:00
Jul 15 01:00:00 openqa logrotate[7711]: log does not need rotating (log size is below the 'size' threshold)
Jul 15 01:00:00 openqa logrotate[7711]: rotating pattern: /var/log/apache2/openqa.access_log 307200000 bytes (20 rotations)
Jul 15 01:00:00 openqa logrotate[7711]: empty log files are not rotated, old logs are removed
Jul 15 01:00:00 openqa logrotate[7711]: considering log /var/log/apache2/openqa.access_log
Jul 15 01:00:00 openqa logrotate[7711]: Now: 2024-07-15 01:00
Jul 15 01:00:00 openqa logrotate[7711]: Last rotated at 2024-06-17 08:00
Jul 15 01:00:00 openqa logrotate[7711]: log does not need rotating (log size is below the 'size' threshold)
Jul 15 01:00:00 openqa systemd[1]: openqa-setup-db.service: Deactivated successfully.
Jul 15 01:00:00 openqa openqa-websockets-daemon[16477]: [debug] [pid:16477] Started to send message to 3074 for job(s) 14929400
Jul 15 01:00:00 openqa systemd[1]: Finished Setup local PostgreSQL database for openQA.
Jul 15 01:00:00 openqa systemd[1]: Starting Enqueues an asset cleanup cleanup task for openQA....
…
Jul 15 01:00:03 openqa openqa-enqueue-asset-cleanup[7767]: {
Jul 15 01:00:03 openqa openqa-enqueue-asset-cleanup[7767]: "gru_id" => 37922639,
Jul 15 01:00:03 openqa openqa-enqueue-asset-cleanup[7767]: "minion_id" => 12136654
Jul 15 01:00:03 openqa openqa-enqueue-asset-cleanup[7767]: }
Jul 15 01:00:03 openqa systemd[1]: openqa-enqueue-asset-cleanup.service: Deactivated successfully.
Jul 15 01:00:03 openqa systemd[1]: Finished Enqueues an asset cleanup cleanup task for openQA..
…
Jul 15 01:00:19 openqa openqa-websockets-daemon[16477]: [debug] [pid:16477] Updating seen of worker 3319 from worker_status (free)
Jul 15 01:00:20 openqa telegraf[6820]: 2024-07-14T23:00:20Z E! [inputs.http] Error in plugin: [url=https://openqa.suse.de/admin/influxdb/jobs]: Get "https://openqa.suse.de/admin/influxdb/jobs": context deadline exceeded (Client.Timeout exceeded while awaiting headers)
Jul 15 01:00:20 openqa telegraf[6820]: 2024-07-14T23:00:20Z E! [inputs.http] Error in plugin: [url=https://openqa.suse.de/admin/influxdb/minion]: Get "https://openqa.suse.de/admin/influxdb/minion": context deadline exceeded (Client.Timeout exceeded while awaiting headers)
Jul 15 01:00:20 openqa openqa-websockets-daemon[16477]: [debug] [pid:16477] Updating seen of worker 3469 from worker_status (free)
…
We also had 130 "timestamp mismatch" jobs again over the weekend:
openqa=> select count(id), min(t_finished) as first_t_finished, max(t_finished) as last_t_finished, reason from jobs where t_finished >= '2024-07-12T18:00:00' and result = 'incomplete' group by reason order by count(id) desc;
count | first_t_finished | last_t_finished | reason
-------+---------------------+---------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
---------------------------------
130 | 2024-07-14 22:48:13 | 2024-07-14 22:54:29 | api failure: 403 response: timestamp mismatch - check whether clocks on the local host and the web UI host are in sync
16 | 2024-07-12 19:56:18 | 2024-07-15 00:19:31 | backend died: QEMU terminated before QMP connection could be established. Check for errors below
13 | 2024-07-15 03:41:26 | 2024-07-15 08:39:35 | backend died: Error connecting to VNC server <openqaw5-xen.qe.prg2.suse.org:5905>: IO::Socket::INET: connect: Connection refused [Auto-restarting because reason matches the configured "auto_clone_regex".]
12 | 2024-07-12 20:20:34 | 2024-07-15 05:02:30 | backend died: QEMU exited unexpectedly, see log for details
8 | 2024-07-15 06:44:41 | 2024-07-15 08:48:24 | backend died: Error connecting to VNC server <unreal6.qe.nue2.suse.org:5904>: IO::Socket::INET: connect: Connection refused [Auto-restarting because reason matches the configured "auto_clone_regex".]
8 | 2024-07-12 20:23:07 | 2024-07-14 20:27:58 | died: terminated prematurely, see log output for details
7 | 2024-07-15 07:16:03 | 2024-07-15 07:49:02 | tests died: unable to load tests/console/validate_partition_table.pm, check the log for the cause (e.g. syntax error)
7 | 2024-07-12 22:31:06 | 2024-07-15 02:14:06 | tests died: unable to load main.pm, check the log for the cause (e.g. syntax error)
4 | 2024-07-12 21:54:33 | 2024-07-14 22:00:55 | tests died: unable to load tests/network/samba/samba_adcli.pm, check the log for the cause (e.g. syntax error)
4 | 2024-07-13 00:39:22 | 2024-07-13 00:42:04 | asset failure: Failed to download sle-15-SP5-x86_64-146.1-gnome_ay_qesec@64bit.qcow2 to /var/lib/openqa/cache/openqa.suse.de/sle-15-SP5-x86_64-146.1-gnome_ay_qesec@64bit.qcow2
3 | 2024-07-15 05:37:27 | 2024-07-15 06:12:00 | backend died: Error connecting to VNC server <unreal6.qe.nue2.suse.org:5908>: IO::Socket::INET: connect: Connection refused [Auto-restarting because reason matches the configured "auto_clone_regex".]
3 | 2024-07-12 23:03:33 | 2024-07-12 23:04:04 | asset failure: Failed to download SLES-15-SP5-x86_64-Build146.3-textmode-intel_ipmi.qcow2 to /var/lib/openqa/cache/openqa.suse.de/SLES-15-SP5-x86_64-Build146.3-textmode-intel_ipmi.qcow2
openqa=> select count(jobs.id), min(t_finished) as first_t_finished, max(t_finished) as last_t_finished, array_agg(DISTINCT workers.host) as hosts, reason from jobs join workers on workers.id = jobs.assigned_worker_id where t_finished >= '2024-07-12T18:00:00' and result = 'incomplete' group by reason order by count(jobs.id) desc limit 1;
count | first_t_finished | last_t_finished | hosts |
reason
-------+---------------------+---------------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+---------------------------------
---------------------------------------------------------------------------------------
130 | 2024-07-14 22:48:13 | 2024-07-14 22:54:29 | {imagetester,openqaworker-arm-1,openqaworker1,openqaworker14,openqaworker17,openqaworker18,qesapworker-prg4,sapworker1,sapworker2,sapworker3,worker-arm1,worker-arm2,worker29,worker30,worker32,worker33,worker34,worker35,worker40} | api failure: 403 response: times
tamp mismatch - check whether clocks on the local host and the web UI host are in sync
(1 row)
EDIT: I adjusted the query to see the exact time range a certain type on incomplete happened. All happened within a very small time window. That window was shortly before the alert fired (you have to add 2 hours to the database timestamps). However, the alert only fired after a grace period. So the "timestamp mismatch" incompletes actually fall into the timeframe were we also had very high response times (https://stats.openqa-monitor.qa.suse.de/d/WebuiDb/webui-summary?orgId=1&viewPanel=78&from=1720984469160&to=1720999670148).
I also added another query to show the relevant worker hosts and it seems all hosts were relevant/affected. That also speaks for a problem on OSD itself and not on the workers.
Updated by tinita 11 months ago
- Related to action #163931: OpenQA logreport for ariel.suse-dmz.opensuse.org Can't locate object method render_specific_not_found via package OpenQA::Shared::Controller::Running added
Updated by mkittler 11 months ago
- Has duplicate action #163928: [alert] Openqa HTTP Response lost on 15-07-24 size:S added
Updated by tinita 11 months ago
Just wanted to note down my observation:
The response time slowly and steadily increased some minutes before 00:01. Funnily the response times were all pretty similar, e.g. directly before the gap it was 16s.
Then after the gap it starts at 375s and goes down slowly, until the queue of waiting requests gets down to normal.
Updated by mkittler 11 months ago · Edited
- Status changed from In Progress to Feedback
I had to edit #163592#note-34 because on second though the "timestamp mismatch" incompletes and high response times fall into the same time frame. (In the first place I didn't take timezones and the alert grace period into account.)
This also coincides with the time where we start the database backup on OSD (40 23 * * * which is every day at 23:40 UTC, or is it? Maybe that's CEST which would mean it does not coincide.).
We have established that cron uses CEST in our case. So the backup on OSD did not coincide with the high response times.
The alpha backup on backup-vm (that also invokes pg_dump at some point) finished around 20 minutes before the high response times:
Jul 15 00:00:00 backup-vm systemd[1]: Starting rsnapshot (alpha) backup...
Jul 15 00:00:23 backup-vm rsnapshot[10648]: Welcome to ariel.infra.opensuse.org!
Jul 15 00:00:23 backup-vm rsnapshot[10648]: ************************
Jul 15 00:00:23 backup-vm rsnapshot[10648]: * Managed by SaltStack *
Jul 15 00:00:23 backup-vm rsnapshot[10648]: ************************
Jul 15 00:00:23 backup-vm rsnapshot[10648]: Make sure changes get pushed into the state repo!
Jul 15 00:37:38 backup-vm rsnapshot[20583]: /usr/bin/rsnapshot alpha: completed successfully
The beta backup started only hours later:
Jul 15 03:30:00 backup-vm systemd[1]: Starting rsnapshot (beta) backup...
Jul 15 03:30:24 backup-vm rsnapshot[1117]: /usr/bin/rsnapshot beta: completed successfully
Jul 15 03:30:24 backup-vm systemd[1]: rsnapshot@beta.service: Deactivated successfully.
Jul 15 03:30:24 backup-vm systemd[1]: Finished rsnapshot (beta) backup.
The delta and gamma backups are not enabled at all.
It is strange that the backups done via backup-vm don't seem to be disturbing but the one triggered by OSD itself is. All those backups are running basically the same command and technically all those backups are executed on OSD because backup-vm is just invoking pg_dump via SSH on OSD.
None of the backups coincided with the high response times.
As an experiment we wanted to disable the backup but I'm not sure how to do it best.
- The cleanest way would be via a MR on the salt-states-openqa repo and the backup-server-salt repos. But we'd create commits just to revert them afterwards again (most likely).
- I could change things manually and disable salt-minion on OSD and the backup-vm. This is manual work and disabling salt is also not ideal.
- I could replace
pg_dumpwithtrueon OSD and lock the corresponding package and hope it won't break anything. The nice thing is that this would even cover the backup done as part of the deployment¹.
¹ And this is a good thing because I think all backups are potentially equally likely to cause this issue. It is all just pg_dump running on the same host (except that the pg_dump invocation before the deployment has no niceness parameters).
Updated by okurz 11 months ago
- Status changed from Feedback to In Progress
- Priority changed from High to Urgent
Either way is fine and I don't think it matters that much. Go with option 3.
Also, the ticket should stay urgent unless alerts are not silenced and can reappear and confuse people as happened with #163928
Updated by mkittler 11 months ago
According to select count(jobs.id), min(t_finished) as first_t_finished, max(t_finished) as last_t_finished, array_agg(DISTINCT workers.host) as hosts, reason from jobs join workers on workers.id = jobs.assigned_worker_id where t_finished >= '2024-07-15T12:00:00' and result = 'incomplete' group by reason order by count(jobs.id) desc limit 10; there were no new incompletes with "timestamp mismatch".
The alert also didn't fire again (and was not even pending).
/etc/alternatives/pg_dump still points to /bin/true.
Updated by okurz 11 months ago
- Description updated (diff)
- Priority changed from Urgent to High
mkittler stated that he would like to keep the alert enabled to be notified if something happens again. But that also means that other people are notified and for them the alert isn't actionable. This is why I tried out to set a nested override notification policy in https://monitor.qa.suse.de/alerting/routes by simply adding a policy with a matcher same as in silences, here matching alertname = HTTP Response alert and setting the contact point "okurz@suse.de" so to inform me but nobody else. Let's see if that is effective.
I monitored the system today, e.g. on
- https://openqa.suse.de/tests?resultfilter=Failed&resultfilter=Incomplete
- https://monitor.qa.suse.de/d/WebuiDb/webui-summary?orgId=1&from=now-7d&to=now&refresh=1h
- https://monitor.qa.suse.de/d/nRDab3Jiz/openqa-jobs-test?orgId=1&refresh=5m
- https://stats.openqa-monitor.qa.suse.de/d/KToPYLEWz/failed-systemd-services?orgId=1&from=now-15m&to=now&refresh=5m
and nothing unexpected is going on. As expected as pg_dump was disabled we can see in https://monitor.qa.suse.de/d/WebuiDb/webui-summary?orgId=1&from=1720911151888&to=1721129714096&viewPanel=89 the regular "20-30 Mil rows requests" have disappeared.
There is also overall a rather low job queue on OSD. Keeping everything else as-is for now.
Updated by okurz 11 months ago · Edited
Still no problems. Benchmarked with ab -c 40 -n 50000 https://openqa.suse.de/ resulting in
Concurrency Level: 40
Time taken for tests: 1375.128 seconds
Complete requests: 50000
Failed requests: 0
Total transferred: 3756950000 bytes
HTML transferred: 3667700000 bytes
Requests per second: 36.36 [#/sec] (mean)
Time per request: 1100.102 [ms] (mean)
Time per request: 27.503 [ms] (mean, across all concurrent requests)
Transfer rate: 2668.04 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 50 67 29.7 62 1263
Processing: 246 1032 377.6 1108 6721
Waiting: 202 994 380.7 1072 6694
Total: 311 1099 373.4 1172 6775
Percentage of the requests served within a certain time (ms)
50% 1172
66% 1243
75% 1285
80% 1311
90% 1379
95% 1438
98% 1518
99% 1596
100% 6775 (longest request)
Now reverted back pg_dump, called the database backup from /etc/cron.d/dump-openqa and in parallel started ab again.
As visible in
https://monitor.qa.suse.de/d/WebuiDb/webui-summary?orgId=1&from=1721282166188&to=1721287759948
HTTP response goes up from mean 200ms to 500ms and system load up to 35 but nothing problematic. Results from ab actually happen to be better than in before:
Concurrency Level: 40
Time taken for tests: 513.778 seconds
Complete requests: 50000
Failed requests: 0
Total transferred: 3762350000 bytes
HTML transferred: 3673100000 bytes
Requests per second: 97.32 [#/sec] (mean)
Time per request: 411.023 [ms] (mean)
Time per request: 10.276 [ms] (mean, across all concurrent requests)
Transfer rate: 7151.27 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 18 33 80.6 25 2069
Processing: 164 377 68.7 369 1383
Waiting: 148 359 61.0 352 1147
Total: 190 411 105.7 395 2502
Percentage of the requests served within a certain time (ms)
50% 395
66% 426
75% 445
80% 457
90% 490
95% 525
98% 615
99% 726
100% 2502 (longest request)
probably the overall time per request decreased as it's currently a less busy time with less users of OSD and pg_dump has no significant impact.
Extended experiment:
echo "### 3x ionice nice pg_dump $(date -Is)"; backup_dir="/var/lib/openqa/backup"; date=$(date -Idate); bf="$backup_dir/$date.dump"; runs=3 count-fail-ratio sudo -u postgres ionice -c3 nice -n19 pg_dump -Fc openqa -f "$bf" ; echo "### 3x not-nice pg_dump $(date -Is)"; backup_dir="/var/lib/openqa/backup"; date=$(date -Idate); bf="$backup_dir/$date.dump"; runs=3 count-fail-ratio sudo -u postgres pg_dump -Fc openqa -f "$bf"
so 3x ionice nice pg_dump followed with 3x not-nice pg_dump. In parallel for i in {1..10}; do echo "### run $i: date -Is while pg_dump is running"; ab -c 40 -n 50000 https://openqa.suse.de/; done
Updated by okurz 11 months ago
- Related to action #159396: Repeated HTTP Response alert for /tests and unresponsiveness due to potential detrimental impact of pg_dump (was: HTTP Response alert for /tests briefly going up to 15.7s) size:M added
Updated by okurz 11 months ago · Edited
After I encountered that pg_dump was still running after running for more than 1h (0930-1048 CEST) and I observed high stead system load I aborted the experiment for now. From https://monitor.qa.suse.de/d/WebuiDb/webui-summary?orgId=1&from=1721284394731&to=1721301033387 it looks like there is a steady 30-35 system load 0930-1300+CEST and an increase of HTTP response to around 1.2s until I stopped near-continuous runs of ab. CPU usage is maxed outwith the majority being user load. Biggest load contribution is due to "openqa" processes. Attached to such processes using strace and found processes mostly upload openQA test results. Also minion jobs queued increased up to 600 at 1247CEST but dropped after that even though in the mean time a pg_dump process triggered by rsnapshot was started. I/O on filesystems is high but on the same levels as I/O load peaks on the last days. It looks like the big load is caused by a combination of factors including multiple heavy openQA jobs finishing although the overall openQA job queue is below 1k so nothing severe.
My plan is to reconduct two experiments after EOB:
-
DONE Run
abover >1h to observe system load impact -> https://monitor.qa.suse.de/d/WebuiDb/webui-summary?orgId=1&from=1721314889745&to=1721325203745 shows a CPU usage of around 85% and system load first 30, later 15, possibly because other users ended their work day. During that timeframe there was also a short rise in minion jobs to around 30 queued. Increased load on /srv (database) and /results. Increased nginx requests per time and absolute numbers of requests with result 200. - Run the "6x pg_dump" experiment but w/o
abin parallel
Updated by okurz 11 months ago
Right now there are <5 openQA jobs running on OSD and overal system load is about 0.5. Running the pg_dump experiment. Runtime of 3x nice pg_dump 690±97s. Runtime for not-nice pg_dump 609±1.5s so slightly faster but not significantly different. The next question is how ab+pg_dump is doing in parallel.
Updated by okurz 11 months ago
- File Screenshot_20240720_170312_openqa_osd_load_during_3x_nice_pg_dump_3x_not-nice_pg_dump.png Screenshot_20240720_170312_openqa_osd_load_during_3x_nice_pg_dump_3x_not-nice_pg_dump.png added
- Status changed from In Progress to Feedback
nice pg_dump 1,087±48 vs. not-nice 688±5
https://monitor.qa.suse.de/d/WebuiDb/webui-summary?orgId=1&from=1721469234906&to=1721478711966
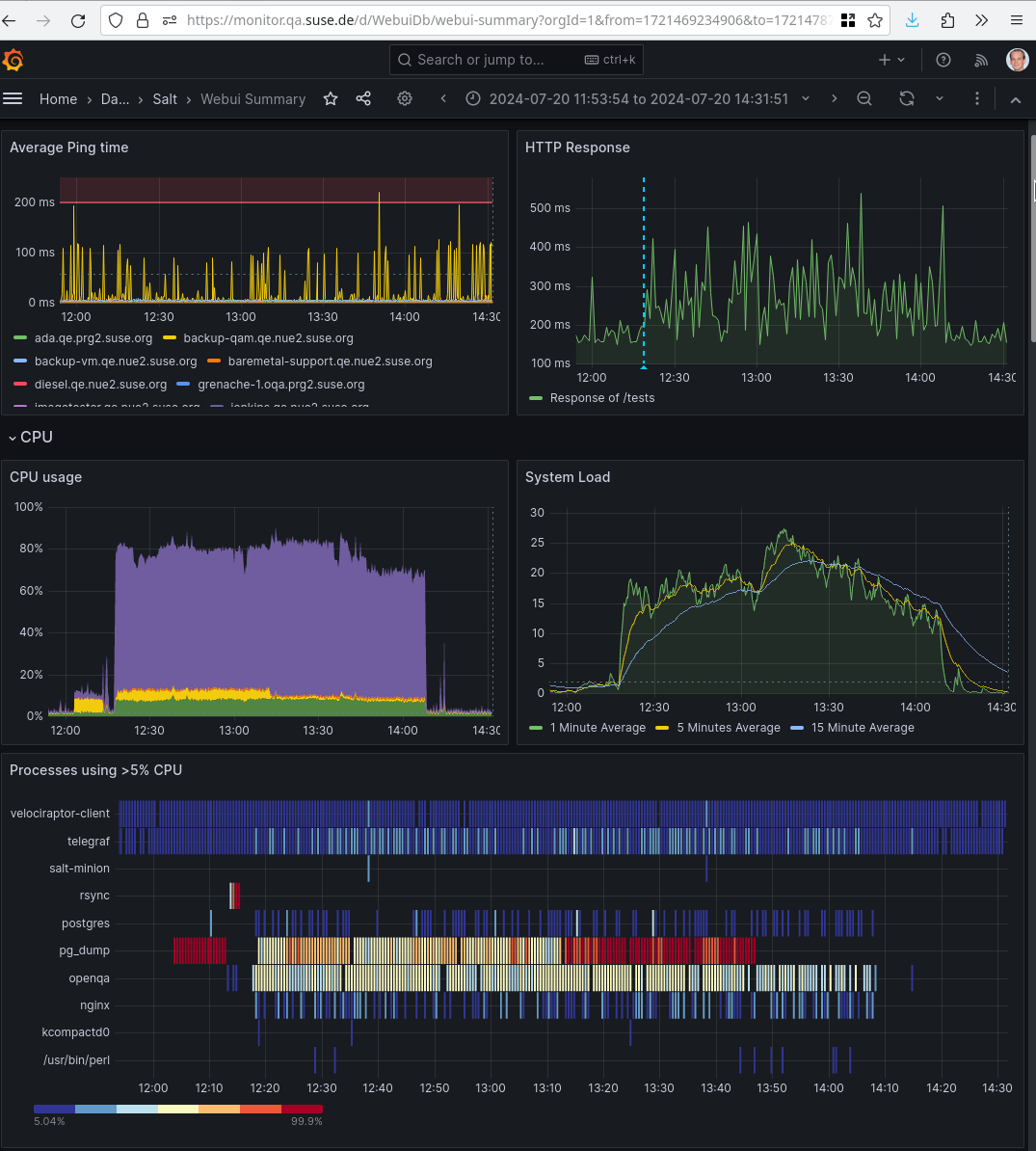
shows the HTTP response and system load during the time of the experiment execution. The system load is in the range 15-25 over the period of the experiment and the usage is around 70-85%.
The next higher level of load can be expected while openQA jobs are running. I set back the job limit to 420. Let's see what happens during in the next week.
Updated by okurz 10 months ago · Edited
- Description updated (diff)
Yesterday in #162038-39 fniederwanger found multiple issues which coincided with an HTTP response alert which I received. The notification policy override worked as expected to only notify me and not the rest of the team. https://monitor.qa.suse.de/d/WebuiDb/webui-summary?orgId=1&from=1721599027985&to=1721610165485 shows the according time period. So we could reproduce the issue in the timeframe 01:17-01:22 CEST on 2024-07-22. I reduced the job limit to 330 again.
By carefully looking at https://monitor.qa.suse.de/d/WebuiDb/webui-summary?orgId=1&from=1721557370670&to=1721718695670 I found "fstrim" running during the time of question. On OSD sudo systemctl list-timers | grep fstrim says
Mon 2024-07-29 01:38:30 CEST 5 days left Mon 2024-07-22 01:00:38 CEST 1 day 8h ago fstrim.timer fstrim.service
so was running during the time of question. systemctl status fstrim says
○ fstrim.service - Discard unused blocks on filesystems from /etc/fstab
Loaded: loaded (/usr/lib/systemd/system/fstrim.service; static)
Active: inactive (dead) since Mon 2024-07-22 01:24:39 CEST; 1 day 7h ago
TriggeredBy: ● fstrim.timer
Docs: man:fstrim(8)
Main PID: 11998 (code=exited, status=0/SUCCESS)
Jul 22 01:00:38 openqa systemd[1]: Starting Discard unused blocks on filesystems from /etc/fstab...
Jul 22 01:24:39 openqa fstrim[11998]: /home: 1.1 GiB (1234653184 bytes) trimmed on /srv/homes.img
Jul 22 01:24:39 openqa fstrim[11998]: /space-slow: 1.6 TiB (1796373069824 bytes) trimmed on /dev/vde
Jul 22 01:24:39 openqa fstrim[11998]: /results: 1.1 TiB (1225170825216 bytes) trimmed on /dev/vdd
Jul 22 01:24:39 openqa fstrim[11998]: /assets: 3.6 TiB (3983120650240 bytes) trimmed on /dev/vdc
Jul 22 01:24:39 openqa fstrim[11998]: /srv: 119.6 GiB (128381288448 bytes) trimmed on /dev/vdb
Jul 22 01:24:39 openqa fstrim[11998]: /: 7.5 GiB (8008380416 bytes) trimmed on /dev/vda1
Jul 22 01:24:39 openqa systemd[1]: fstrim.service: Deactivated successfully.
Jul 22 01:24:39 openqa systemd[1]: Finished Discard unused blocks on filesystems from /etc/fstab.
so it can be seen that the overall trim took from 01:00 to 01:24 so 24 minutes and also significant space was cleaned for each filesystem.
I consider it quite likely that fstrim can explain the problematic behaviour we see and possibly reducing the global job limit won't be helping much.
I asked in https://suse.slack.com/archives/C02CLLS7R4P/p1721719368768919 "#discuss-support-storage"
Hi, we observed an issue with a virtual machine that is running https://openqa.suse.de which uses multiple multi-TB virtual storage devices running from a IT maintained netapp cluster. The issue is low or stalled I/O operations leading to failing HTTP request of the openQA service. That happens regularly especially every Monday 01:00 CET/CEST and is very likely linked to the fstrim service running on a time Details on https://progress.opensuse.org/issues/163592 . My main question is: Does it make sense that fstrim runs in that situation at all? If yes, how could the impact on system performance be lessened?
According to my research a regular "trim" operation might help. https://blog.nuvotex.de/when-fstrim-stalls-your-i-o-subsystem/ stated that they just disabled fstrim as running on virtualized storage anyway. As stated on https://thelinuxcode.com/fstrim-linux-command/ there are daemons to run trim while the system is idle. That could be an option to explore. According to https://www.fosslinux.com/126140/mastering-fstrim-a-linux-command-for-ssd-optimization.htm it would be a good idea to run trim after "massive deletions" as e.g. our cleanup tasks.
Triggering systemctl start fstrim now while OSD is not that busy
EDIT: That caused immediate unresponsiveness so we could actually quite consistently trigger the original problem it seems.
# journalctl -f -u fstrim
Jul 22 01:24:39 openqa systemd[1]: Finished Discard unused blocks on filesystems from /etc/fstab.
Jul 23 10:23:33 openqa systemd[1]: Starting Discard unused blocks on filesystems from /etc/fstab...
Jul 23 10:47:32 openqa fstrim[19285]: /home: 323.2 MiB (338911232 bytes) trimmed on /srv/homes.img
Jul 23 10:47:32 openqa fstrim[19285]: /space-slow: 1.6 TiB (1794598633472 bytes) trimmed on /dev/vde
Jul 23 10:47:32 openqa fstrim[19285]: /results: 1.1 TiB (1236262948864 bytes) trimmed on /dev/vdd
Jul 23 10:47:32 openqa fstrim[19285]: /assets: 3.3 TiB (3598693122048 bytes) trimmed on /dev/vdc
Jul 23 10:47:32 openqa fstrim[19285]: /srv: 116.1 GiB (124629774336 bytes) trimmed on /dev/vdb
Jul 23 10:47:32 openqa fstrim[19285]: /: 5.7 GiB (6089187328 bytes) trimmed on /dev/vda1
Jul 23 10:47:32 openqa systemd[1]: fstrim.service: Deactivated successfully.
Jul 23 10:47:32 openqa systemd[1]: Finished Discard unused blocks on filesystems from /etc/fstab.
shows that again significant storage was trimmed nearly as much as just yesterday. Also the whole operation also took 24 minutes so just as long as yesterday. That also means that likely running that daily wouldn't help. I would still like to trigger that again within the same day multiple times consecutively to see if that causes the same problems. Then I could check if running trimming sequentially and not in parallel would help.
Looking at the OSD system journal again from yesterday night it seems the first indication of problems after the line "Starting Discard unused blocks on filesystems" is
telegraf[6820]: 2024-07-21T23:01:20Z E! [inputs.http] Error in plugin: [url=https://openqa.suse.de/admin/influxdb/jobs]: Get "https://openqa.suse.de/admin/influxdb/jobs": context deadline exceeded (Client.Timeout exceeded while awaiting headers)
but we should be aware that the initial problem this ticket describes is of a different source especially as fstrim is only triggered each Monday, not Wednesday.
Updated by okurz 10 months ago · Edited
- Status changed from Feedback to In Progress
https://suse.slack.com/archives/C02CANHLANP/p1721841092771439
As there is really just 1 (!) job running right now on OSD and 8 scheduled I will use the opportunity to conduct another important load experiment for https://progress.opensuse.org/issues/163592 . Expect spotty responsiveness of OSD for the next hours
date -Is && time sudo nice -n 19 ionice -c 3 /usr/sbin/fstrim --listed-in /etc/fstab:/proc/self/mountinfo --verbose --quiet-unsupported
From the output of that command and lsof -p $(pidof fstrim) it looks like only one mount point after another is trimmed. /home and /space-slow finished within seconds. /results takes long. But maybe that was me running "ab" for benchmarking. In "ab" I saw just normal response times. Pretty much as soon as I aborted that fstrim continued and finished stating /assets and only some seconds later the other file-systems:
$ date -Is && time sudo nice -n 19 ionice -c 3 /usr/sbin/fstrim --listed-in /etc/fstab:/proc/self/mountinfo --verbose --quiet-unsupported
2024-07-24T19:13:17+02:00
/home: 3.4 GiB (3630792704 bytes) trimmed on /srv/homes.img
/space-slow: 1.6 TiB (1796142841856 bytes) trimmed on /dev/vde
/results: 1.1 TiB (1231325605888 bytes) trimmed on /dev/vdd
/assets: 2.6 TiB (2893093855232 bytes) trimmed on /dev/vdc
/srv: 117.4 GiB (126101643264 bytes) trimmed on /dev/vdb
/: 7.4 GiB (7976497152 bytes) trimmed on /dev/vda1
real 37m36.323s
user 0m0.009s
sys 2m55.929s
so overall that took 37m. Let's see how long the same takes w/o me running "ab". That run finished again within 24m but interesting enough no significant effect on service availability. Let's see if without nice/ionice we can actually trigger unresponsiveness.
Updated by okurz 10 months ago
- Copied to action #164427: HTTP response alert every Monday 01:00 CET/CEST due to fstrim size:M added