coordination #135122
closedcoordination #110833: [saga][epic] Scale up: openQA can handle a schedule of 100k jobs with 1k worker instances
[epic] OSD openQA refuses to assign jobs, >3k scheduled not being picked up, no alert
100%
Description
Observation¶
From user reports in https://suse.slack.com/archives/C02CANHLANP/p1693798894476509 we learned that OSD openQA is not running the expected number of openQA jobs. https://openqa.suse.de/tests/ shows >3k jobs scheduled, only a single one in "running". No alerts known about it yet.
Maybe has to do with "max_running_jobs" and our artificial job limit?
From osd:/var/log/openqa_scheduler it seems the last time we had been exceeding "max_running_jobs" was yesterday morning:
[2023-09-03T06:42:55.629721+02:00] [debug] [pid:1477] max_running_jobs (220) exceeded, scheduling no additional jobs
but eventually no new jobs were scheduled:
[2023-09-03T06:37:08.921368+02:00] [debug] [pid:1477] Scheduler took 15.07441s to perform operations and allocated 80 jobs
[2023-09-03T06:38:25.471240+02:00] [debug] [pid:1477] max_running_jobs (220) exceeded, scheduling no additional jobs
[2023-09-03T06:39:55.414995+02:00] [debug] [pid:1477] max_running_jobs (220) exceeded, scheduling no additional jobs
[2023-09-03T06:41:34.751180+02:00] [debug] [pid:1477] Scheduler took 10.90210s to perform operations and allocated 36 jobs
[2023-09-03T06:42:55.629721+02:00] [debug] [pid:1477] max_running_jobs (220) exceeded, scheduling no additional jobs
[2023-09-03T06:44:30.842675+02:00] [debug] [pid:1477] Scheduler took 6.99158s to perform operations and allocated 12 jobs
[2023-09-03T06:45:58.842208+02:00] [debug] [pid:1477] Scheduler took 4.99004s to perform operations and allocated 1 jobs
[2023-09-03T06:47:38.480906+02:00] [debug] [pid:1477] Scheduler took 14.62729s to perform operations and allocated 7 jobs
[2023-09-03T06:49:09.720436+02:00] [debug] [pid:1477] Scheduler took 20.26448s to perform operations and allocated 2 jobs
[2023-09-03T06:49:24.279251+02:00] [debug] [pid:1477] Scheduler took 14.54522s to perform operations and allocated 2 jobs
[2023-09-03T06:49:29.162836+02:00] [debug] [pid:1477] Scheduler took 4.86909s to perform operations and allocated 5 jobs
[2023-09-03T06:49:33.687399+02:00] [debug] [pid:1477] Scheduler took 4.51766s to perform operations and allocated 1 jobs
[2023-09-03T06:52:25.667024+02:00] [debug] [pid:1477] Scheduler took 81.97759s to perform operations and allocated 20 jobs
[2023-09-03T06:52:41.096276+02:00] [debug] [pid:1477] Scheduler took 7.40601s to perform operations and allocated 2 jobs
[2023-09-03T06:54:13.828477+02:00] [debug] [pid:1477] Scheduler took 10.13754s to perform operations and allocated 1 jobs
[2023-09-03T06:55:48.446219+02:00] [debug] [pid:1477] Scheduler took 14.75419s to perform operations and allocated 10 jobs
[2023-09-03T06:57:21.131280+02:00] [debug] [pid:1477] Scheduler took 17.43828s to perform operations and allocated 2 jobs
[2023-09-03T06:58:42.071371+02:00] [debug] [pid:1477] Scheduler took 8.37779s to perform operations and allocated 6 jobs
[2023-09-03T06:59:49.418522+02:00] [debug] [pid:1477] Scheduler took 16.24076s to perform operations and allocated 2 jobs
[2023-09-03T06:59:54.048626+02:00] [debug] [pid:1477] Scheduler took 4.61859s to perform operations and allocated 2 jobs
[2023-09-03T07:01:29.409578+02:00] [debug] [pid:1477] Scheduler took 5.35949s to perform operations and allocated 0 jobs
[2023-09-03T07:03:19.697510+02:00] [debug] [pid:1477] Scheduler took 25.64661s to perform operations and allocated 6 jobs
[2023-09-03T07:04:47.643066+02:00] [debug] [pid:1477] Scheduler took 23.59141s to perform operations and allocated 8 jobs
[2023-09-03T07:06:07.213855+02:00] [debug] [pid:1477] Scheduler took 13.16123s to perform operations and allocated 3 jobs
[2023-09-03T07:07:47.049396+02:00] [debug] [pid:1477] Scheduler took 22.99531s to perform operations and allocated 1 jobs
[2023-09-03T07:08:24.139019+02:00] [debug] [pid:1477] Scheduler took 9.99626s to perform operations and allocated 2 jobs
[2023-09-03T07:08:29.208727+02:00] [debug] [pid:1477] Scheduler took 5.04446s to perform operations and allocated 0 jobs
[2023-09-03T07:10:05.727911+02:00] [debug] [pid:1477] Scheduler took 6.51611s to perform operations and allocated 4 jobs
[2023-09-03T07:11:41.546293+02:00] [debug] [pid:1477] Scheduler took 12.33484s to perform operations and allocated 6 jobs
[2023-09-03T07:13:13.093861+02:00] [debug] [pid:1477] Scheduler took 33.87103s to perform operations and allocated 5 jobs
[2023-09-03T07:13:20.125107+02:00] [debug] [pid:1477] Scheduler took 6.93538s to perform operations and allocated 8 jobs
[2023-09-03T07:15:06.484994+02:00] [debug] [pid:1477] Scheduler took 16.35689s to perform operations and allocated 3 jobs
[2023-09-03T07:16:40.364063+02:00] [debug] [pid:1477] Scheduler took 20.23532s to perform operations and allocated 2 jobs
[2023-09-03T07:16:48.671665+02:00] [debug] [pid:1477] Scheduler took 8.29525s to perform operations and allocated 4 jobs
[2023-09-03T07:17:25.439549+02:00] [debug] [pid:1477] Scheduler took 36.75237s to perform operations and allocated 2 jobs
[2023-09-03T07:20:04.238661+02:00] [debug] [pid:1477] Scheduler took 74.66060s to perform operations and allocated 10 jobs
[2023-09-03T07:20:50.585632+02:00] [debug] [pid:1477] Scheduler took 46.23221s to perform operations and allocated 3 jobs
[2023-09-03T07:22:25.632465+02:00] [debug] [pid:1477] Scheduler took 5.04418s to perform operations and allocated 0 jobs
[2023-09-03T07:24:07.989898+02:00] [debug] [pid:1477] Scheduler took 17.39979s to perform operations and allocated 2 jobs
[2023-09-03T07:24:56.537013+02:00] [debug] [pid:1477] Scheduler took 38.60689s to perform operations and allocated 3 jobs
[2023-09-03T07:25:10.040476+02:00] [debug] [pid:1477] Scheduler took 13.48023s to perform operations and allocated 7 jobs
[2023-09-03T07:27:56.371014+02:00] [debug] [pid:1477] Scheduler took 76.32781s to perform operations and allocated 2 jobs
[2023-09-03T07:28:15.311355+02:00] [debug] [pid:1477] Scheduler took 5.26678s to perform operations and allocated 0 jobs
[2023-09-03T07:29:45.190681+02:00] [debug] [pid:1477] Scheduler took 5.14464s to perform operations and allocated 0 jobs
[2023-09-03T07:31:17.581632+02:00] [debug] [pid:1477] Scheduler took 7.53423s to perform operations and allocated 1 jobs
[2023-09-03T07:32:54.416454+02:00] [debug] [pid:1477] Scheduler took 14.36776s to perform operations and allocated 1 jobs
[2023-09-03T07:33:22.111923+02:00] [debug] [pid:1477] Scheduler took 22.00829s to perform operations and allocated 4 jobs
[2023-09-03T07:33:26.993713+02:00] [debug] [pid:1477] Scheduler took 4.86527s to perform operations and allocated 2 jobs
[2023-09-03T07:35:09.693114+02:00] [debug] [pid:1477] Scheduler took 12.69689s to perform operations and allocated 1 jobs
[2023-09-03T07:36:32.347401+02:00] [debug] [pid:1477] Scheduler took 5.35075s to perform operations and allocated 0 jobs
[2023-09-03T07:38:02.165366+02:00] [debug] [pid:1477] Scheduler took 5.16799s to perform operations and allocated 0 jobs
[2023-09-03T07:39:32.304272+02:00] [debug] [pid:1477] Scheduler took 5.30574s to perform operations and allocated 0 jobs
[2023-09-03T07:41:01.816015+02:00] [debug] [pid:1477] Scheduler took 4.81563s to perform operations and allocated 0 jobs
[2023-09-03T07:42:32.059338+02:00] [debug] [pid:1477] Scheduler took 5.05789s to perform operations and allocated 0 jobs
[2023-09-03T07:43:21.293300+02:00] [debug] [pid:1477] Scheduler took 4.78223s to perform operations and allocated 0 jobs
[2023-09-03T07:43:25.971259+02:00] [debug] [pid:1477] Scheduler took 4.66514s to perform operations and allocated 0 jobs
[2023-09-03T07:43:32.419474+02:00] [debug] [pid:1477] Scheduler took 6.44357s to perform operations and allocated 0 jobs
[2023-09-03T07:45:07.570593+02:00] [debug] [pid:1477] Scheduler took 5.14955s to perform operations and allocated 0 jobs
…
I restarted both openqa-websockets as well as openqa-scheduler but to no effect.
Acceptance criteria¶
- AC1: A situation like this raises an alert
- AC2: New jobs are scheduled while max_running_jobs is clearly not exceeded and scheduled jobs exist
Rollback¶
Suggestions¶
Files
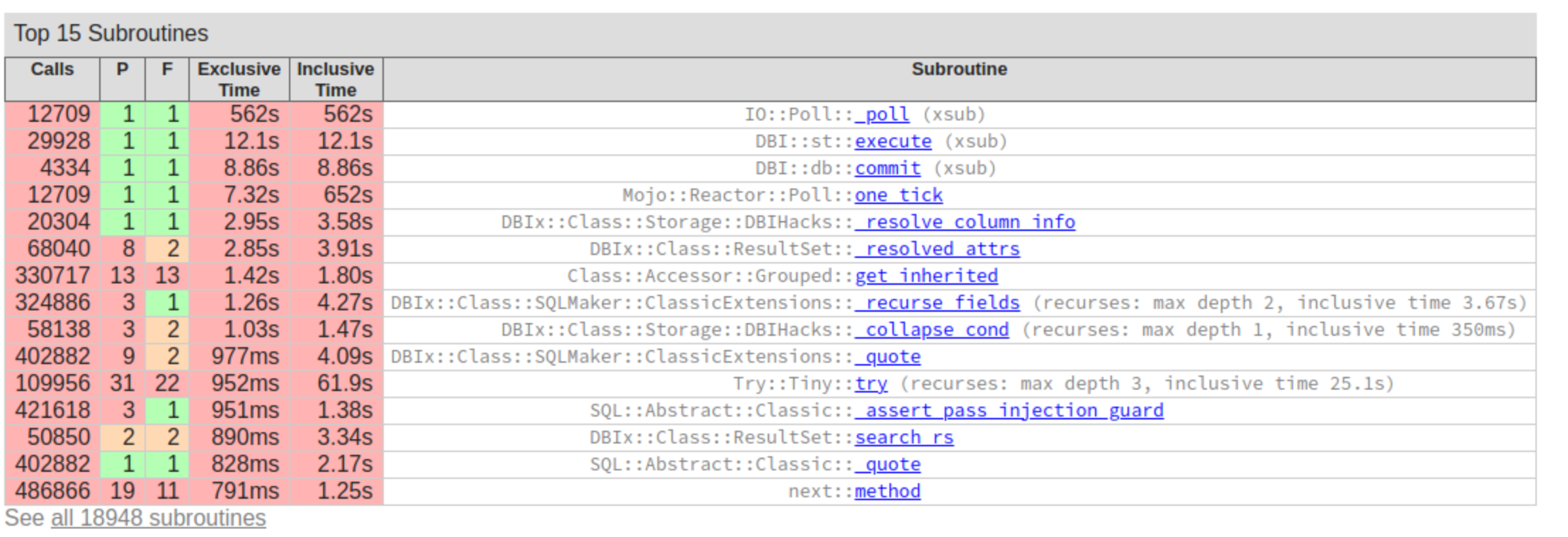
| top15-700.png (642 KB) top15-700.png | top 15 subroutines | ||
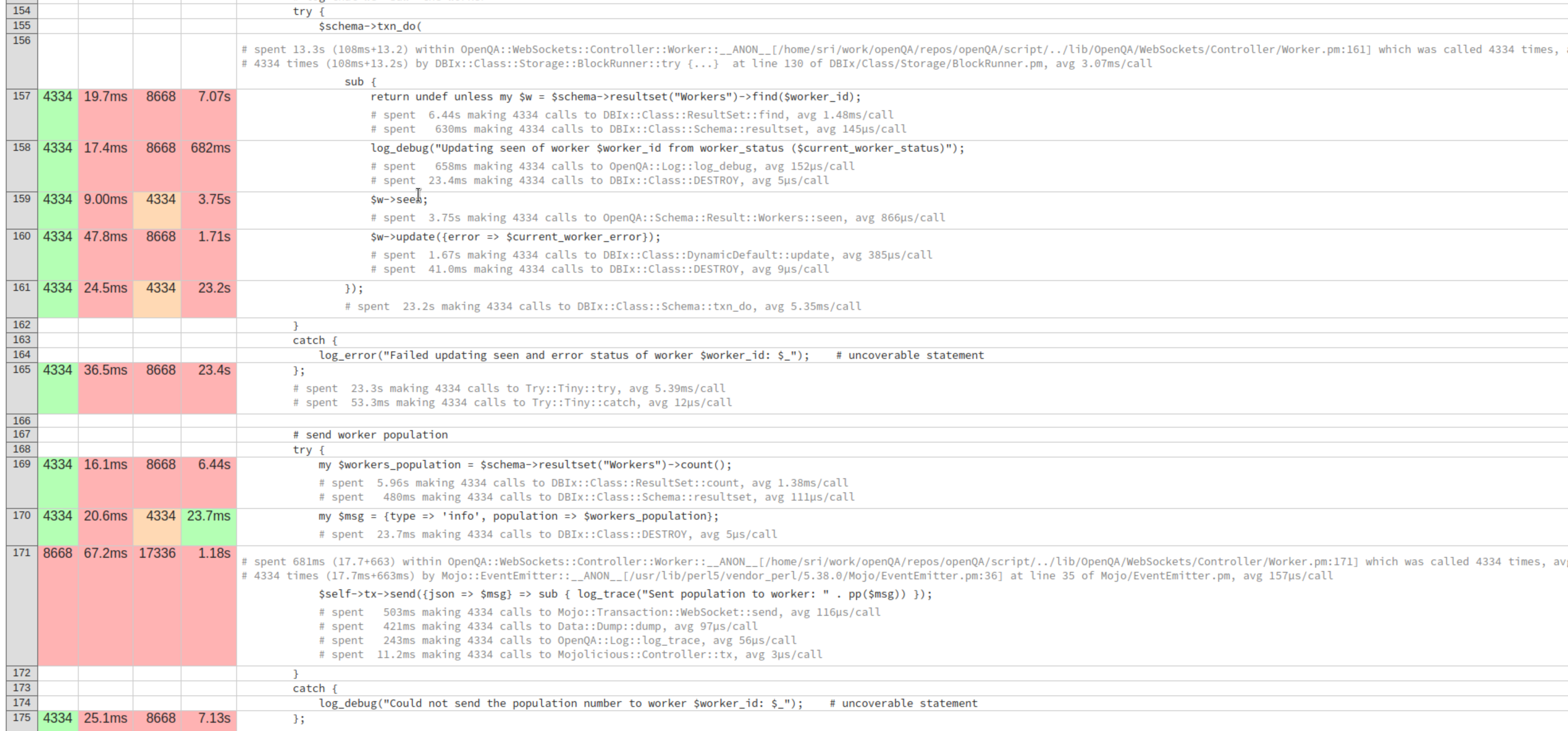
| seen.png (1.57 MB) seen.png | first half of the hot code path | ||
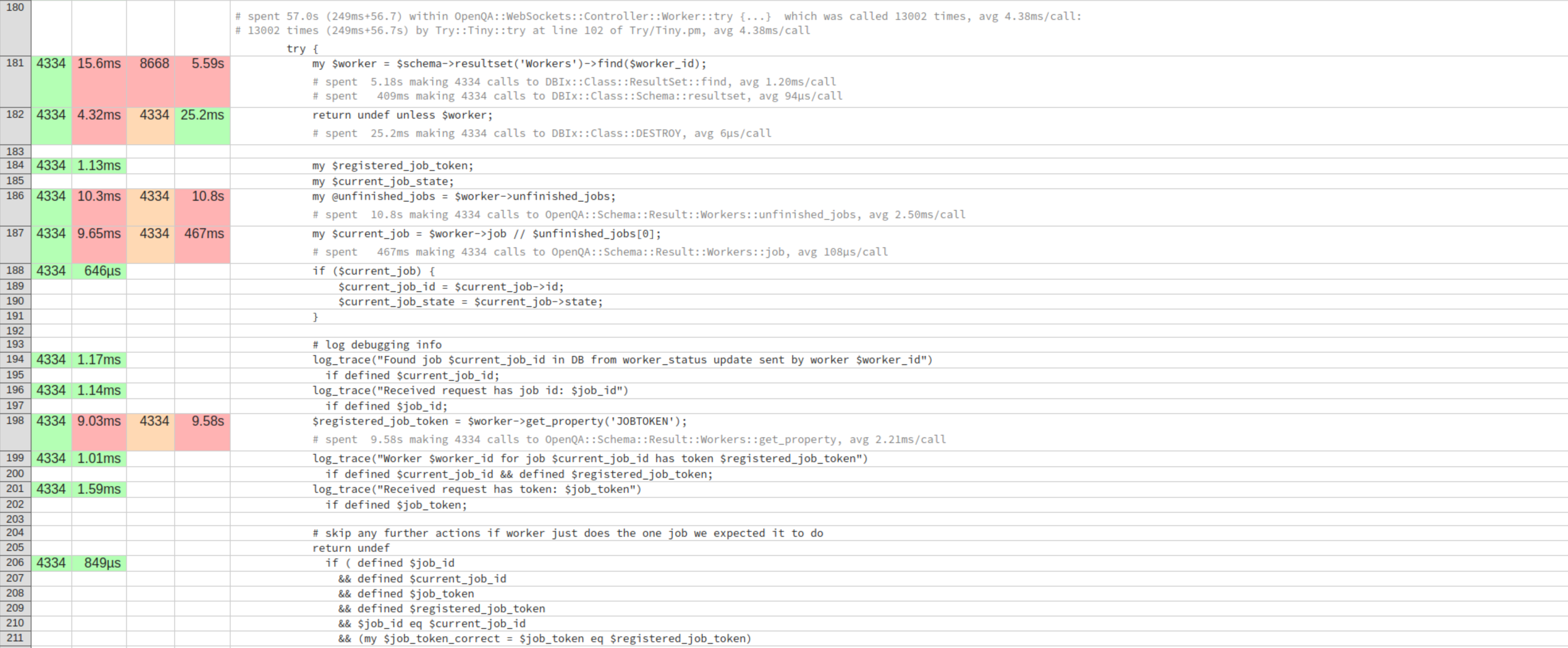
| duplicate.png (1.25 MB) duplicate.png | second half of the hot code path |
{kind=link}
{kind=link}
{kind=link}
Updated by okurz over 1 year ago
- Related to action #134693: Only one or two jobs running on osd for several hours added
Updated by okurz over 1 year ago
From
journalctl -f _SYSTEMD_UNIT=openqa-webui.service + _SYSTEMD_UNIT=openqa-websockets.service + _SYSTEMD_UNIT=openqa-scheduler.service
I see
Sep 04 10:30:53 openqa openqa-websockets-daemon[12824]: [debug] [pid:12824] Updating seen of worker 527 from worker_status (free)
Sep 04 10:30:53 openqa openqa[28183]: [warn] [pid:28183] Unable to wakeup scheduler: Request timeout
Sep 04 10:30:54 openqa openqa-websockets-daemon[12824]: [debug] [pid:12824] Updating seen of worker 533 from worker_status (free)
Sep 04 10:30:56 openqa openqa[28192]: [debug] [pid:28192] Sending AMQP event: suse.openqa.job.create
Sep 04 10:30:56 openqa openqa[28192]: [debug] [pid:28192] AMQP URL: amqps://openqa:b45z45bz645tzrhwer@rabbit.suse.de:5671/?exchange=pubsub
Sep 04 10:30:56 openqa openqa[28192]: [debug] [pid:28192] suse.openqa.job.create published
Sep 04 10:30:58 openqa openqa-websockets-daemon[12824]: [debug] [pid:12824] Updating seen of worker 1050 from worker_status (free)
Sep 04 10:31:01 openqa openqa[28192]: [warn] [pid:28192] Unable to wakeup scheduler: Request timeout
Sep 04 10:31:02 openqa openqa-websockets-daemon[12824]: [debug] [pid:12824] Updating seen of worker 1063 from worker_status (free)
so there are AMQP messages sent out but warnings about "scheduler: Request timeout"
Updated by tinita over 1 year ago
- Status changed from New to In Progress
- Assignee set to tinita
Updated by tinita over 1 year ago
The first large gap I see between here (/var/log/openqa_scheduler):
[2023-09-03T07:35:02.134089+02:00] [debug] [pid:1477] Assigned job '11995015' to worker ID '2118'
...
[2023-09-03T22:23:23.460248+02:00] [debug] [pid:1477] Assigned job '11995449' to worker ID '2370'
Updated by kraih over 1 year ago
@osukup attached strace to both the openqa-workers and the openqa-scheduler services, which showed us some interesting results. Here openqa-scheduler is getting blocked trying to send a job to openqa-websockets:
connect(7, {sa_family=AF_INET, sin_port=htons(9527), sin_addr=inet_addr("127.0.0.1")}, 16) = 0
getpeername(7, {sa_family=AF_INET, sin_port=htons(9527), sin_addr=inet_addr("127.0.0.1")}, [256 => 16]) = 0
setsockopt(7, SOL_TCP, TCP_NODELAY, [1], 4) = 0
getsockname(7, {sa_family=AF_INET, sin_port=htons(44166), sin_addr=inet_addr("127.0.0.1")}, [256 => 16]) = 0
getsockname(7, {sa_family=AF_INET, sin_port=htons(44166), sin_addr=inet_addr("127.0.0.1")}, [256 => 16]) = 0
getpeername(7, {sa_family=AF_INET, sin_port=htons(9527), sin_addr=inet_addr("127.0.0.1")}, [256 => 16]) = 0
poll([{fd=7, events=POLLIN|POLLPRI|POLLOUT}], 1, 599999) = 1 ([{fd=7, revents=POLLOUT}])
write(7, "POST /api/send_job HTTP/1.1\r\nAcc"..., 4491) = 4491
poll([{fd=7, events=POLLIN|POLLPRI}], 1, 600000
...blocked...
And at the same time openqa-websockets is busy writing status updates from workers to the database:
recvfrom(7, "T\0\0\0\36\0\1count\0\0\0\0\0\0\0\0\0\0\24\0\10\377\377\377\377\0\0D"..., 16384, 0, NULL, NULL) = 66
sendto(7, "B\0\0\0#\0dbdpg_p12824_2\0\0\0\0\1\0\0\0\3886"..., 58, MSG_NOSIGNAL, NULL, 0) = 58
recvfrom(7, "2\0\0\0\4T\0\0\0\361\0\tid\0\0\0Aa\0\1\0\0\0\24\0\10\377\377\377\377\0"..., 16384, 0, NULL, NULL) = 389
sendto(7, "B\0\0\0#\0dbdpg_p12824_5\0\0\0\0\1\0\0\0\3886"..., 58, MSG_NOSIGNAL, NULL, 0) = 58
recvfrom(7, "2\0\0\0\4T\0\0\3\203\0\36id\0\0\0@\226\0\1\0\0\0\24\0\10\377\377\377\377\0"..., 16384, 0, NULL, NULL) = 925
sendto(7, "B\0\0\0/\0dbdpg_p12824_3\0\0\0\0\2\0\0\0\10JOB"..., 70, MSG_NOSIGNAL, NULL, 0) = 70
recvfrom(7, "2\0\0\0\4T\0\0\0\235\0\6id\0\0\0AY\0\1\0\0\0\24\0\10\377\377\377\377\0"..., 16384, 0, NULL, NULL) = 183
sendto(7, "Q\0\0\0\nbegin\0", 11, MSG_NOSIGNAL, NULL, 0) = 11
recvfrom(7, "C\0\0\0\nBEGIN\0Z\0\0\0\5T", 16384, 0, NULL, NULL) = 17
sendto(7, "B\0\0\0$\0dbdpg_p12824_2\0\0\0\0\1\0\0\0\004103"..., 59, MSG_NOSIGNAL, NULL, 0) = 59
recvfrom(7, "2\0\0\0\4T\0\0\0\361\0\tid\0\0\0Aa\0\1\0\0\0\24\0\10\377\377\377\377\0"..., 16384, 0, NULL, NULL) = 391
sendto(7, "B\0\0\0R\0dbdpg_p12824_6\0\0\0\0\3\0\0\0\023202"..., 105, MSG_NOSIGNAL, NULL, 0) = 105
recvfrom(7, "2\0\0\0\4n\0\0\0\4C\0\0\0\rUPDATE 1\0Z\0\0\0\5T", 16384, 0, NULL, NULL) = 30
sendto(7, "Q\0\0\0\vcommit\0", 12, MSG_NOSIGNAL, NULL, 0) = 12
recvfrom(7, "C\0\0\0\vCOMMIT\0Z\0\0\0\5I", 16384, 0, NULL, NULL) = 18
sendto(7, "Q\0\0\0&SELECT COUNT( * ) FROM work"..., 39, MSG_NOSIGNAL, NULL, 0) = 39
recvfrom(7, "T\0\0\0\36\0\1count\0\0\0\0\0\0\0\0\0\0\24\0\10\377\377\377\377\0\0D"..., 16384, 0, NULL, NULL) = 66
sendto(7, "B\0\0\0$\0dbdpg_p12824_2\0\0\0\0\1\0\0\0\004103"..., 59, MSG_NOSIGNAL, NULL, 0) = 59
recvfrom(7, "2\0\0\0\4T\0\0\0\361\0\tid\0\0\0Aa\0\1\0\0\0\24\0\10\377\377\377\377\0"..., 16384, 0, NULL, NULL) = 391
sendto(7, "B\0\0\0$\0dbdpg_p12824_5\0\0\0\0\1\0\0\0\004103"..., 59, MSG_NOSIGNAL, NULL, 0) = 59
recvfrom(7, "2\0\0\0\4T\0\0\3\203\0\36id\0\0\0@\226\0\1\0\0\0\24\0\10\377\377\377\377\0"..., 16384, 0, NULL, NULL) = 925
sendto(7, "B\0\0\0000\0dbdpg_p12824_3\0\0\0\0\2\0\0\0\10JOB"..., 71, MSG_NOSIGNAL, NULL, 0) = 71
recvfrom(7, "2\0\0\0\4T\0\0\0\235\0\6id\0\0\0AY\0\1\0\0\0\24\0\10\377\377\377\377\0"..., 16384, 0, NULL, NULL) = 183
sendto(7, "Q\0\0\0\nbegin\0", 11, MSG_NOSIGNAL, NULL, 0) = 11
recvfrom(7, "C\0\0\0\nBEGIN\0Z\0\0\0\5T", 16384, 0, NULL, NULL) = 17
sendto(7, "B\0\0\0#\0dbdpg_p12824_2\0\0\0\0\1\0\0\0\003530"..., 58, MSG_NOSIGNAL, NULL, 0) = 58
recvfrom(7, "2\0\0\0\4T\0\0\0\361\0\tid\0\0\0Aa\0\1\0\0\0\24\0\10\377\377\377\377\0"..., 16384, 0, NULL, NULL) = 389
sendto(7, "B\0\0\0Q\0dbdpg_p12824_6\0\0\0\0\3\0\0\0\023202"..., 104, MSG_NOSIGNAL, NULL, 0) = 104
recvfrom(7, "2\0\0\0\4n\0\0\0\4C\0\0\0\rUPDATE 1\0Z\0\0\0\5T", 16384, 0, NULL, NULL) = 30
sendto(7, "Q\0\0\0\vcommit\0", 12, MSG_NOSIGNAL, NULL, 0) = 12
recvfrom(7, "C\0\0\0\vCOMMIT\0Z\0\0\0\5I", 16384, 0, NULL, NULL) = 18
sendto(7, "Q\0\0\0&SELECT COUNT( * ) FROM work"..., 39, MSG_NOSIGNAL, NULL, 0) = 39
recvfrom(7, "T\0\0\0\36\0\1count\0\0\0\0\0\0\0\0\0\0\24\0\10\377\377\377\377\0\0D"..., 16384, 0, NULL, NULL) = 66
sendto(7, "B\0\0\0#\0dbdpg_p12824_2\0\0\0\0\1\0\0\0\003530"..., 58, MSG_NOSIGNAL, NULL, 0) = 58
recvfrom(7, "2\0\0\0\4T\0\0\0\361\0\tid\0\0\0Aa\0\1\0\0\0\24\0\10\377\377\377\377\0"..., 16384, 0, NULL, NULL) = 389
sendto(7, "B\0\0\0#\0dbdpg_p12824_5\0\0\0\0\1\0\0\0\003530"..., 58, MSG_NOSIGNAL, NULL, 0) = 58
recvfrom(7, "2\0\0\0\4T\0\0\3\203\0\36id\0\0\0@\226\0\1\0\0\0\24\0\10\377\377\377\377\0"..., 16384, 0, NULL, NULL) = 925
sendto(7, "B\0\0\0/\0dbdpg_p12824_3\0\0\0\0\2\0\0\0\10JOB"..., 70, MSG_NOSIGNAL, NULL, 0) = 70
recvfrom(7, "2\0\0\0\4T\0\0\0\235\0\6id\0\0\0AY\0\1\0\0\0\24\0\10\377\377\377\377\0"..., 16384, 0, NULL, NULL) = 183
This seems to suggest that we might have reached an upper limit for the number of idle workers OSD is able to handle with the current count of 1052 workers.
Merely restartig the services showed no improvements, so all workers have been taken offline with salt '*' cmd.run 'systemctl stop openqa-worker*'. Shortly afterwards salt restarted workers, which seems to have been slow enough to allow for the system to recover on its own. We expect the problem to return however, as soon as all workers go idle again. Probably during the next weekend.
Updated by okurz over 1 year ago
- Related to action #134924: Websocket server overloaded, affected worker slots shown as "broken" with graceful disconnect in workers table added
Updated by kraih over 1 year ago
The current worker status update interval seems to be 20-100 seconds. Which doesn't look too bad even with 1052 workers. The websocket messages themselves are probably no problem, but the database queries triggered by each one will be the bottleneck. From the strace it appears that each one causes at least a SELECT COUNT(*) workers and an UPDATE workers..., which are rather costly operations. So aside from simply reducing the number of workers attached to OSD, we could also try optimising the database a bit.
The workers table is mostly ephemeral and we don't care too much about lost data during an unclean shutdown. That opens the possibility for making the table unlogged with ALTER TABLE workers SET UNLOGGED;, which should significantly improve the performance for the UPDATE as well as the SELECT, at the cost of data loss during unclean shutdowns.
Updated by kraih over 1 year ago
Also worth investigating might be the status update interval itself (20-100 seconds), there's always the possibility of a bug that causes updates to be sent too frequently when the worker is idle.
Updated by kraih over 1 year ago
It might be possible to locally replicate this issue with enough idle workers. I've not tried something like that yet, but will give it a shot. There's a feature that was added many years ago to avoid this kind of issue, which now ironically contributes to the large number of database queries blocking the websocket process. Perhaps it can be ripped out completely to improve the database bottleneck.
Updated by szarate over 1 year ago
- Related to action #25960: [tools][sprint 201710.2][sprint 201711.1] Investigate/Optimize messages sent from Workers to WebSockets Server added
Updated by livdywan over 1 year ago
kraih wrote in #note-15:
It might be possible to locally replicate this issue with enough idle workers. I've not tried something like that yet, but will give it a shot. There's a feature that was added many years ago to avoid this kind of issue, which now ironically contributes to the large number of database queries blocking the websocket process. Perhaps it can be ripped out completely to improve the database bottleneck.
Btw this is the according PR: https://github.com/os-autoinst/openQA/pull/5293
Updated by okurz over 1 year ago
To mitigate but also for #134912 I powered off worker13 and removed it from salt following https://progress.opensuse.org/projects/openqav3/wiki/#Take-machines-out-of-salt-controlled-production and
ssh -t -4 jumpy@qe-jumpy.suse.de -- ipmitool -I lanplus -C 3 -H openqaworker13-ipmi.qe-ipmi-ur -U ADMIN -P XXX power off
Same for worker9
Updated by kraih over 1 year ago
livdywan wrote in #note-17:
Btw this is the according PR: https://github.com/os-autoinst/openQA/pull/5293
For context, that's only the first PR, which is an obvious optimization. More to follow once i have profiling data.
Updated by okurz over 1 year ago
disabling more worker instances now
Trying on OSD
sudo salt 'worker3[1,2,3,4,5,6]*' cmd.run 'sudo systemctl disable --now telegraf $(systemctl list-units | grep openqa-worker-auto-restart | cut -d "." -f 1 | xargs)' && for i in {1..6}; do sudo salt-key -y -d "worker3$i*"; done
Updated by osukup over 1 year ago
Updated by livdywan over 1 year ago
osukup wrote in #note-21:
MR with alert -> https://gitlab.suse.de/osukup/salt-states-openqa/-/merge_requests/new?merge_request%5Bsource_branch%5D=jobs_alert
I can't open that - did you actually create the MR?
Updated by kraih over 1 year ago
- File top15-700.png top15-700.png added
- File seen.png seen.png added
- File duplicate.png duplicate.png added
kraih wrote in #note-15:
It might be possible to locally replicate this issue with enough idle workers. I've not tried something like that yet, but will give it a shot. There's a feature that was added many years ago to avoid this kind of issue, which now ironically contributes to the large number of database queries blocking the websocket process. Perhaps it can be ripped out completely to improve the database bottleneck.
Locally i can spin up 700 workers and even with a profiler attached to openqa-websockets, which significantly reduces performance, it's been running smoothly. As expected most time is spent idle in the event loop and performing database queries. Attached are screenshots of the top 15 and the hot code path for worker status updates. Some noteworthy observations there are the high cost of the SELECT COUNT(*) query for the worker population feature, duplicate $schema->resultset('Workers')->find($worker_id) calls, and the surprisingly slow $worker->get_property('JOBTOKEN').
Updated by kraih over 1 year ago
kraih wrote in #note-13:
The workers table is mostly ephemeral and we don't care too much about lost data during an unclean shutdown. That opens the possibility for making the table unlogged with
ALTER TABLE workers SET UNLOGGED;, which should significantly improve the performance for theUPDATEas well as theSELECT, at the cost of data loss during unclean shutdowns.
Unfortunately this is not an option after all. The jobs table has a relation on the workers table and would have to be made unlogged as well, which of course we don't want.
Updated by openqa_review over 1 year ago
- Due date set to 2023-09-20
Setting due date based on mean cycle time of SUSE QE Tools
Updated by okurz over 1 year ago
- Copied to action #135239: Conduct lessons learned "Five Why" analysis for "OSD openQA refuses to assign jobs, >3k scheduled not being picked up, no alert" size:M added
Updated by okurz over 1 year ago
https://monitor.qa.suse.de/d/nRDab3Jiz/openqa-jobs-test?orgId=1&viewPanel=9&from=1693909052517&to=1693991923027 shows that OSD has been busy with running jobs for nearly a day so we can reduce priority
Updated by kraih over 1 year ago
While benchmarking my next patch i made a small mistake and noticed something concerning. Once the websocket server is overwhelmed by too many status updates it only gets harder to recover as time passes. Because the workers are unaware of the status of the websocket server and just keep sending more status updates. And if the previous status update has not been processed yet, the new ones just get buffered behind it and will have to be processed eventually. Making it very easy for the problem to spiral out of control. Perhaps we can keep a last seen timestamp in the websocket server and ignore status updates coming in too fast to reduce the number of SQL queries.
Updated by kraih over 1 year ago
- Tags changed from scheduler, no alert to scheduler, no alert, epic
- Subject changed from OSD openQA refuses to assign jobs, >3k scheduled not being picked up, no alert to [epic] OSD openQA refuses to assign jobs, >3k scheduled not being picked up, no alert
Updated by livdywan over 1 year ago
- Tracker changed from action to coordination
Updated by osukup over 1 year ago
I can't open that - did you actually create the MR?
yeah, but copied bad link ...
https://gitlab.suse.de/openqa/salt-states-openqa/-/merge_requests/973
Updated by osukup over 1 year ago
- Related to action #135407: [tools] Measure to mitigate websockets overload by workers and revert it size:M added
Updated by osukup over 1 year ago
- Assignee deleted (
osukup)
AC1 full filled, new provisioned alert deployed in grafana. When running jobs go under 20 while exists more than 100 scheduled jobs. It will fire alert.
As now --> it looks like 600 workers is safe limit for current OSD setup .. -> running jobs sometimes during weekend got to 30 ( while in same time scheduled and blocked jobs are going down) , but during long time, and without any manual intervention then returned to values above 100+. Another thing, decrease of jobs was much slower than original problem.
Updated by okurz over 1 year ago
- Assignee set to okurz
https://gitlab.suse.de/openqa/salt-states-openqa/-/merge_requests/973 merged. Alert specific improvements to be done in #135380
Updated by okurz over 1 year ago
After recent optimizations we can again increase the number of workers with a revert of a recent change https://gitlab.suse.de/openqa/salt-pillars-openqa/-/merge_requests/606
Updated by livdywan over 1 year ago
osukup wrote in #note-40:
AC1 full filled, new provisioned alert deployed in grafana. When running jobs go under 20 while exists more than 100 scheduled jobs. It will fire alert.
As now --> it looks like 600 workers is safe limit for current OSD setup .. -> running jobs sometimes during weekend got to 30 ( while in same time scheduled and blocked jobs are going down) , but during long time, and without any manual intervention then returned to values above 100+. Another thing, decrease of jobs was much slower than original problem.
You got the wrong ticket. This is the epic. You are/were working on #135380 ;-)
Updated by okurz over 1 year ago
- Related to coordination #108209: [epic] Reduce load on OSD added