Actions
action #101520
closed[bot-ng] Stop very frequent scheduling of single incident jobs size:M
Description
Observation¶
I don't know how often are single jobs rescheduled, but stop this insanity.
Tests are blindly rotating because they even don't finish or something failed.
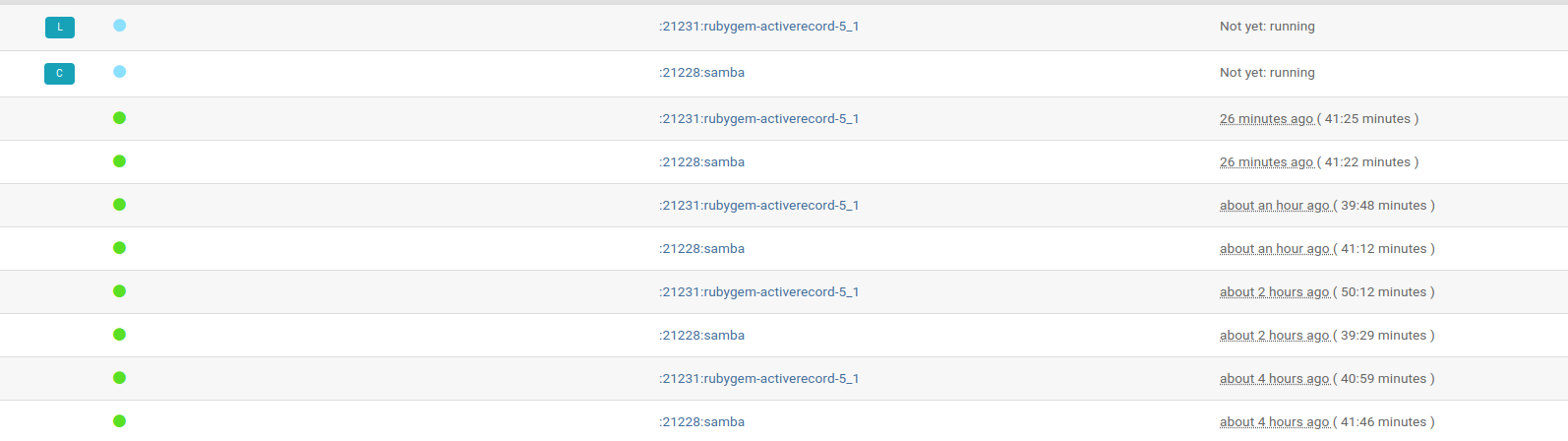
Below is one of many updates e.g. :21228:samba 3501 single jobs where 2037 are obsoleted and just 30 failed.
select id, test, version, result from jobs where build = ':21228:samba' and result = 'failed' order by id desc;
id | test | version | result
---------+-----------------------------------------+---------+--------
7513541 | qam_ha_hawk_client | 15-SP2 | failed
7507613 | qam-regression-installation-SLED | 15-SP2 | failed
7507543 | cryptlvm | 15.3 | failed
7507483 | qam_ha_hawk_client | 15-SP2 | failed
7503579 | qam_ha_hawk_client | 15-SP2 | failed
7496686 | qam_ha_qdevice_node2 | 15-SP2 | failed
7491914 | cryptlvm | 15.3 | failed
7489156 | qam-incidentinstall | 15-SP2 | failed
7488544 | qam-incidentinstall-ha | 15-SP2 | failed
7482383 | mau-extratests1 | 15-SP2 | failed
…
7141789 | qam_ha_hawk_client | 15-SP2 | failed
(30 rows)
select id, test, version, result from jobs where build = ':21228:samba' order by id desc;
id | test | version | result
---------+------------------------------------------------+---------+------------------
7545733 | qam-incidentinstall | 15-SP2 | none
7545699 | mau-extratests-docker | 15-SP2 | none
7545698 | mau-extratests1 | 15-SP2 | none
… (yes, we get it, the list is very long :) )
7329994 | qam_ha_rolling_update_support_server | 15-SP2 | obsoleted
(2037 rows)
Problem¶
The component that triggers these tests is gitlab.suse.de/qa-maintenance/bot-ng and AFAIK (okurz) there were no recent changes in this component that should explain a change in scheduling behaviour.
Expected result¶
Less tests are triggered (but how many "less"?)
Suggestions¶
- Ask coolo what he means with "the repo is moving"
- Look into the gitlab CI pipelines https://gitlab.suse.de/qa-maintenance/bot-ng/-/pipelines , e.g. from the latest log (at time of writing) https://gitlab.suse.de/qa-maintenance/bot-ng/-/pipelines/239575 , to understand what is going on, if there is something unusual happening
- Potentially temporarily reduce the frequency with which the pipeline is triggered to prevent "too many" jobs to be triggered
- Find out if this only happens for some incidents or all
- Try to find what the tool is expected to do vaguely
- What could be tried optionally (like a guess) is to apply a timeout (or cooldown time) per incident to not schedule too often regardless what triggered changes
Files
{kind=link}
Actions