action #101520
closed[bot-ng] Stop very frequent scheduling of single incident jobs size:M
Description
Observation¶
I don't know how often are single jobs rescheduled, but stop this insanity.
Tests are blindly rotating because they even don't finish or something failed.
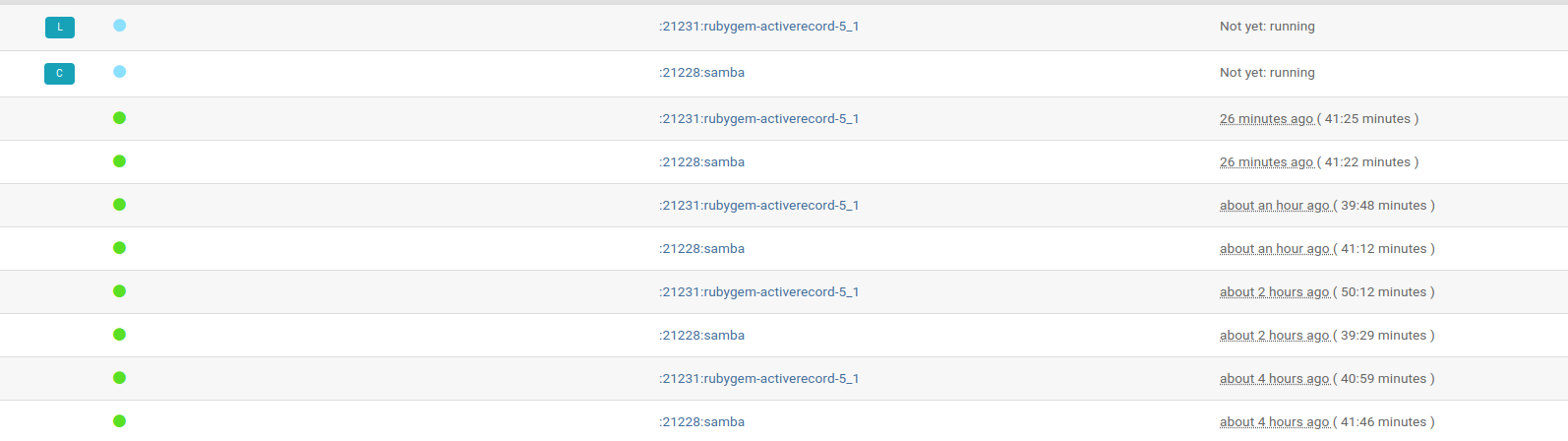
Below is one of many updates e.g. :21228:samba 3501 single jobs where 2037 are obsoleted and just 30 failed.
select id, test, version, result from jobs where build = ':21228:samba' and result = 'failed' order by id desc;
id | test | version | result
---------+-----------------------------------------+---------+--------
7513541 | qam_ha_hawk_client | 15-SP2 | failed
7507613 | qam-regression-installation-SLED | 15-SP2 | failed
7507543 | cryptlvm | 15.3 | failed
7507483 | qam_ha_hawk_client | 15-SP2 | failed
7503579 | qam_ha_hawk_client | 15-SP2 | failed
7496686 | qam_ha_qdevice_node2 | 15-SP2 | failed
7491914 | cryptlvm | 15.3 | failed
7489156 | qam-incidentinstall | 15-SP2 | failed
7488544 | qam-incidentinstall-ha | 15-SP2 | failed
7482383 | mau-extratests1 | 15-SP2 | failed
…
7141789 | qam_ha_hawk_client | 15-SP2 | failed
(30 rows)
select id, test, version, result from jobs where build = ':21228:samba' order by id desc;
id | test | version | result
---------+------------------------------------------------+---------+------------------
7545733 | qam-incidentinstall | 15-SP2 | none
7545699 | mau-extratests-docker | 15-SP2 | none
7545698 | mau-extratests1 | 15-SP2 | none
… (yes, we get it, the list is very long :) )
7329994 | qam_ha_rolling_update_support_server | 15-SP2 | obsoleted
(2037 rows)
Problem¶
The component that triggers these tests is gitlab.suse.de/qa-maintenance/bot-ng and AFAIK (okurz) there were no recent changes in this component that should explain a change in scheduling behaviour.
Expected result¶
Less tests are triggered (but how many "less"?)
Suggestions¶
- Ask coolo what he means with "the repo is moving"
- Look into the gitlab CI pipelines https://gitlab.suse.de/qa-maintenance/bot-ng/-/pipelines , e.g. from the latest log (at time of writing) https://gitlab.suse.de/qa-maintenance/bot-ng/-/pipelines/239575 , to understand what is going on, if there is something unusual happening
- Potentially temporarily reduce the frequency with which the pipeline is triggered to prevent "too many" jobs to be triggered
- Find out if this only happens for some incidents or all
- Try to find what the tool is expected to do vaguely
- What could be tried optionally (like a guess) is to apply a timeout (or cooldown time) per incident to not schedule too often regardless what triggered changes
Files
{kind=link}
Updated by dzedro over 3 years ago
- Project changed from openQA Tests (public) to openQA Project (public)
Updated by dzedro over 3 years ago
- Subject changed from Stop very frequent scheduling of sinle tests to Stop very frequent scheduling of single incident jobs
Updated by coolo over 3 years ago
- Priority changed from Normal to Urgent
The repo is moving and it looks like the bot takes any movement in the incident as signal to trigger all of it:
https://download.suse.de/download/ibs/SUSE:/Maintenance:/21228/SUSE_Updates_openSUSE-SLE_15.3/
Updated by okurz over 3 years ago
- Category set to Feature requests
- Target version set to Ready
Updated by okurz over 3 years ago
- Subject changed from Stop very frequent scheduling of single incident jobs to [bot-ng] Stop very frequent scheduling of single incident jobs size:M
- Description updated (diff)
- Status changed from New to Workable
@coolo can you clarify what you mean with "the repo is moving"? Is this something unusual?
Updated by coolo over 3 years ago
yes, the repos that the release request is about are locked and won't update - but 15.3 repo is not locked and causes these rebuilds. The logic that checks if the incident needs to be rescheduled needs to look only at the relevant repos.
Updated by kraih over 3 years ago
Looks like the GitLab Pipeline currently runs every hour. Would it be possible to run it less frequent for the time being to reduce the urgency of this issue? (Until a proper fix can be implemented to the reschedule logic)
Updated by okurz over 3 years ago
coolo wrote:
yes, the repos that the release request is about are locked and won't update - but 15.3 repo is not locked and causes these rebuilds.
can you explain why the 15.3 repos are designed differently? Can 15.3 repos be "locked" as well?
The logic that checks if the incident needs to be rescheduled needs to look only at the relevant repos.
You mean in bot-ng handle 15.3 repos explicitly to not consider them "relevant"?
kraih wrote:
Looks like the GitLab Pipeline currently runs every hour. Would it be possible to run it less frequent for the time being to reduce the urgency of this issue? (Until a proper fix can be implemented to the reschedule logic)
I guess that question mainly goes to dzedro, coolo and QA maintenance related managers
Updated by coolo over 3 years ago
Guess it's not so much about 15.3
https://openqa.suse.de/tests/7513541#next_previous is scheduled in SP2, still there are 27 runs scheduled for :21228:samba in a month. But https://build.suse.de/request/show/256866 is open only for 3 days. So I guess the ticket is asking about stopping to reschedule unlocked incidents blindly.
Updated by jbaier_cz over 3 years ago
I am not entirely sure, however if I followed the code correctly, when there is a new version/revision in any repo in the incident (including the openSUSE-SLE_15.3), the incident is rescheduled in all of them; so the solution for this might be:
- Do not look on changes in the openSUSE-SLE
- Only update relevant jobs (as coolo wrote)
Updated by okurz over 3 years ago
Sounds useful. Am I right to assume that this is not a recent regression (and hence actually not that urgent)?
Updated by coolo over 3 years ago
- Priority changed from Urgent to High
https://stats.openqa-monitor.qa.suse.de/d/nRDab3Jiz/openqa-jobs-test?viewPanel=11&orgId=1&from=now-2y&to=now - look the trend for "Maintenance: Single Incidents"
.
Updated by coolo over 3 years ago
There is definitely a problem - the SP2 repos are locked since 25th
Updated by osukup over 3 years ago
okurz wrote:
Sounds useful. Am I right to assume that this is not a recent regression (and hence actually not that urgent)?
it's same for years( in past it was worse because orig bot used same REPOHASH for all architectures), and yes openSUSE Leap-SLE repo looks like a case of above average reschedule
on the other side, IBS changes repomd.xml too much -> so if anyone proposes a better mechanism to check changes of incident
Updated by osukup over 3 years ago
Updated by osukup over 3 years ago
- Status changed from Workable to In Progress
- Assignee set to osukup
Updated by openqa_review over 3 years ago
- Due date set to 2021-11-16
Setting due date based on mean cycle time of SUSE QE Tools
Updated by osukup over 3 years ago
Updated by jbaier_cz over 3 years ago
- Related to action #102347: bot-ng: repohash calculation added
Updated by okurz over 3 years ago
- Due date deleted (
2021-11-16) - Status changed from Resolved to Feedback
From #102347: I believe we have a regression in repohash calculation introduced by https://gitlab.suse.de/qa-maintenance/bot-ng/-/merge_requests/27. The problem is likely caused by inconsistencies between product version from metadata (12-SP2) and version from incident (12-SP2-BCL, ...).
Due to this, some jobs are not scheduled, see https://suse.slack.com/archives/C02D16TCP99/p1636721399076500
@jbaier_cz suggests a fix https://gitlab.suse.de/qa-maintenance/bot-ng/-/merge_requests/32
Updated by osukup over 3 years ago
- Status changed from Feedback to Resolved
@okurz both was fixed..(suggestet fix merged and working)