action #169939
closedopenQA Project (public) - coordination #157969: [epic] Upgrade all our infrastructure, e.g. o3+osd workers+webui and production workloads, to openSUSE Leap 15.6
Upgrade Power8 o3 workers to openSUSE Leap 15.6 size:M
0%
Description
Motivation¶
- Need to upgrade workers before EOL of Leap 15.5 and have a consistent environment
- Upgrading power8 workers - kerosene.qe.nue2.suse.org and qa-power8-3.openqanet.opensuse.org encountered some issues, refer #157972
Acceptance criteria¶
- AC1: all power8 o3 worker machines run a clean upgraded openSUSE Leap 15.6 (no failed systemd services, no left over .rpm-new files, etc.)
Suggestions¶
- Go through the comment to understand the issue: #157972-53
- read https://progress.opensuse.org/projects/openqav3/wiki#Distribution-upgrades
- Reserve some time when the workers are only executing a few or no openQA test jobs
- Keep IPMI interface ready and test that Serial-over-LAN works for potential recovery
- Try using old package version of kernel and utils-linux, refer: #119008-14
- After upgrade reboot and check everything working as expected, additionally use https://github.com/os-autoinst/scripts/blob/master/reboot-stability-check, if not rollback, e.g. with
transactional-update rollback
Rollback Actions¶
- Remove zypper package lock
perl-Mojo-IOLoop-ReadWriteProcess
Further details¶
- Don't worry, everything can be repaired :) If by any chance the worker gets misconfigured there are btrfs snapshots to recover, the IPMI Serial-over-LAN, a reinstall is possible and not hard, there is no important data on the host (it's only an openQA worker) and there are also other machines that can jobs while one host might be down for a little bit longer. And okurz can hold your hand :)
Files
| clipboard-202501101213-mq9d6.png (38.4 KB) clipboard-202501101213-mq9d6.png | |||
| clipboard-202501101222-maqgi.png (74.5 KB) clipboard-202501101222-maqgi.png | |||
| clipboard-202501101823-slqbk.png (67.8 KB) clipboard-202501101823-slqbk.png | |||
| clipboard-202501101826-poyf3.png (40.9 KB) clipboard-202501101826-poyf3.png | |||
| clipboard-202501101827-kt565.png (86.1 KB) clipboard-202501101827-kt565.png | |||
| clipboard-202501131748-nqil7.png (60.4 KB) clipboard-202501131748-nqil7.png | |||
| clipboard-202501141602-ndo23.png (72.5 KB) clipboard-202501141602-ndo23.png | |||
| qa-power8-crash (29.6 KB) qa-power8-crash | |||
| crash-qa-power8 (66 KB) crash-qa-power8 | Kernel Crash Log | ||
| Crash-Log.7z (2.07 MB) Crash-Log.7z | |||
| Crash-Log.tar.gz (4.37 MB) Crash-Log.tar.gz | |||
| qa-power8-softlockup-2.log (112 KB) qa-power8-softlockup-2.log | |||
| qa-power8-3-kernel-error.log (94.2 KB) qa-power8-3-kernel-error.log |
Updated by gpathak 4 months ago
- Copied from action #157972: Upgrade o3 workers to openSUSE Leap 15.6 size:S added
Updated by okurz 3 months ago
- Related to action #157975: Upgrade osd workers to openSUSE Leap 15.6 size:S added
Updated by gpathak 2 months ago
After performing an upgrade on qa-power8-3.openqanet.opensuse.org, the petitboot is taking a lot of time to mount the actual filesystem (/dev/sda3).
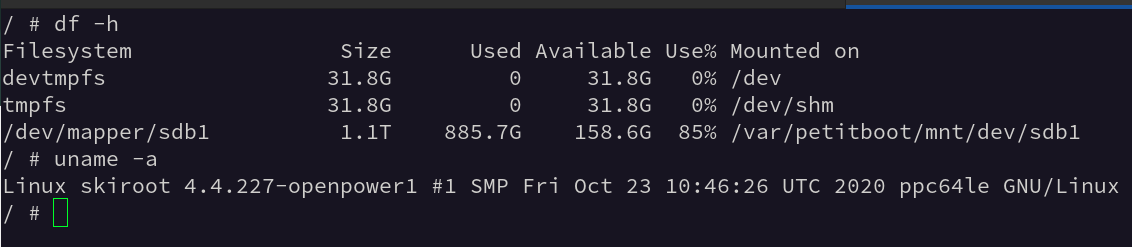
I think @nicksinger did something magical previously as part of #169576 to fix this issue.

Updated by gpathak about 2 months ago
After removing Kernel 6.4.0.150600.23.30, the machine is now able to boot properly without going into maintenance mode.
Triggered some jobs on o3 to check if tests pass:
Updated by gpathak about 2 months ago
- File clipboard-202501101823-slqbk.png clipboard-202501101823-slqbk.png added
- File clipboard-202501101826-poyf3.png clipboard-202501101826-poyf3.png added
- File clipboard-202501101827-kt565.png clipboard-202501101827-kt565.png added
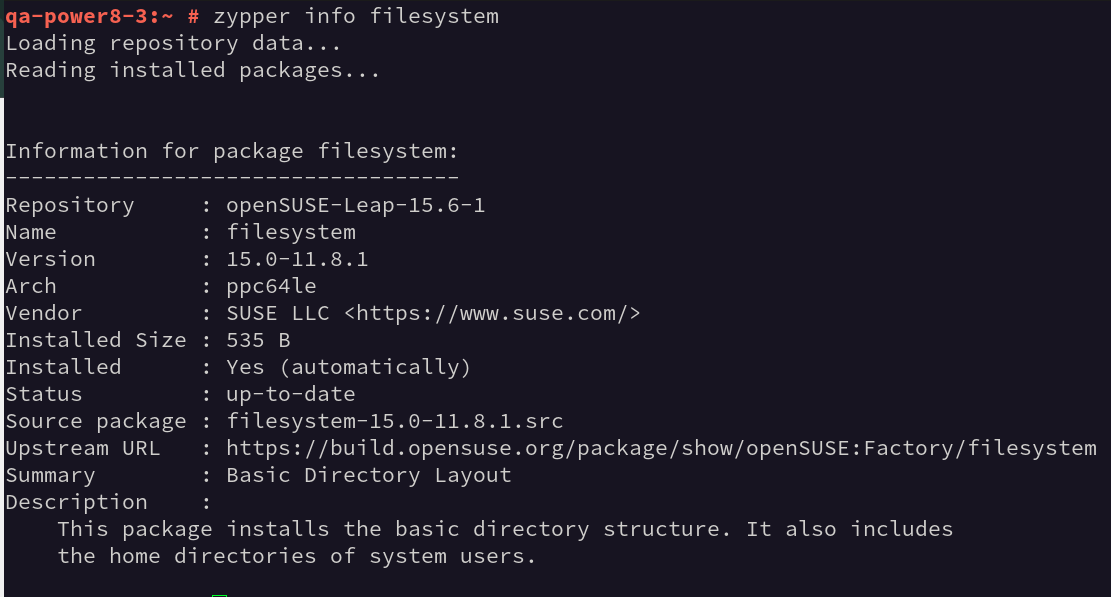
Trying to update the kernel to 6.12.8 from https://download.opensuse.org/repositories/Kernel:/stable/PPC/ is causing package conflict with package filesystem

Trying to upgrade the filesystem to a newer version isn't supported because it is the highest version installed from Factory

The URL of the repo is pointing to OBS factory
Updated by openqa_review about 2 months ago
- Due date set to 2025-01-25
Setting due date based on mean cycle time of SUSE QE Tools
Updated by gpathak about 2 months ago
I was able to upgrade the qa-power8 machine to 15.6 with Kernel version 6.13.0-rc6-3.g25a2d29-default installed from https://download.opensuse.org/repositories/Kernel:/HEAD/PPC/
Have to replace suse module tools to non-standard repository https://download.opensuse.org/repositories/home:/mwilck:/suse-module-tools/PowerPC/
Installed filesystem-84.87-16.1.ppc64le package from https://build.opensuse.org/package/show/openSUSE:Factory/filesystem and changed vendor to obs://build.opensuse.org/Base:System
Tried cloning jobs to run to qa-power8, but the jobs are failing
Fatal error in command /usr/bin/chattr +C /var/lib/openqa/pool/4/raid: Can't locate object method "quirkiness" via package "Mojo::IOLoop::ReadWriteProcess" at /usr/lib/os-autoinst/osutils.pm line 63
https://openqa.opensuse.org/tests/4764546
other error was main: Can't locate object method "_fork_collect_status" via package "Mojo::IOLoop::ReadWriteProcess" at /usr/lib/perl5/vendor_perl/5.26.1/Mojo/IOLoop/ReadWriteProcess/Session.pm line 79
https://openqa.opensuse.org/tests/4765533
Updated by gpathak about 2 months ago
I verified that the system gets IP address and doesn't crash during boot with Linux Kernel 6.4 (without performing reboot stability check) but I have to manually edit the Petitboot option to modify Kernel and Initrd path, I have to delete the initial /@/.snapshots/1/snapshot from Kernel and Initrd path as shown in the screenshot to boot the machine.

Not sure how to save it permanently.
Updated by gpathak about 2 months ago
gpathak wrote in #note-19:
Not sure how to save it permanently.
Turned out that /etc/default/grub needs to have some extra configuration that wasn't present on qa-power8.
Checked petrol and diesel for grub configuration in /etc/default/grub, copied the common configuration on qa-power8 as well and the boot issue mentioned in my previous comment is resolved.
Right now running reboot-stability-check script https://github.com/os-autoinst/scripts/blob/master/reboot-stability-check.
Linux Kernel Version 6.4 is currently active and running on qa-power8
Updated by gpathak about 2 months ago

Reboot stability check executed 30 times and the machine booted successfully.
run: 25, qa-power8-3.openqanet.opensuse.org: ping .. ok, ssh .. ok, uptime/reboot: 21:45:15 up 0:05, 0 users, load average: 0.88, 0.93, 0.45
run: 26, qa-power8-3.openqanet.opensuse.org: ping .. ok, ssh .. ok, uptime/reboot: 21:58:54 up 0:05, 0 users, load average: 0.88, 0.92, 0.45
run: 27, qa-power8-3.openqanet.opensuse.org: ping .. ok, ssh .. ok, uptime/reboot: 22:12:29 up 0:05, 0 users, load average: 0.96, 0.94, 0.45
run: 28, qa-power8-3.openqanet.opensuse.org: ping .. ok, ssh .. ok, uptime/reboot: 22:26:06 up 0:05, 0 users, load average: 0.89, 0.93, 0.45
run: 29, qa-power8-3.openqanet.opensuse.org: ping .. ping: sendmsg: No route to host
ok, ssh .. ok, uptime/reboot: 22:39:37 up 0:05, 0 users, load average: 1.11, 1.18, 0.58
run: 30, qa-power8-3.openqanet.opensuse.org: ping .. ping: sendmsg: No route to host
ok, ssh .. ok, uptime/reboot: 22:53:14 up 0:05, 0 users, load average: 1.02, 1.12, 0.56
but tests aren't running properly and failing...
Updated by gpathak about 2 months ago · Edited
The jobs on qa-power8-3 were failing with error:
[2025-01-10T19:04:01.488855+01:00] [debug] [pid:29227] Fatal error in command/usr/bin/chattr +C /var/lib/openqa/pool/4/raid: Can't locate object method "quirkiness" via package "Mojo::IOLoop::ReadWriteProcess" at /usr/lib/os-autoinst/osutils.pm line 63.
Turned out that there were two ReadWriteProcess.pm files — one located in /usr/lib/perl5/vendor_perl/5.26.1/Mojo/IOLoop and the other in /usr/lib/perl5/site_perl/5.26.1/Mojo/IOLoop. The latter did not have any quirkiness defined, such as:
has [qw(blocking_stop serialize quirkiness total_sleeptime_during_kill)] => 0;
This definition was present in the vendor_perl version.
To resolve the issue, I had to delete the ReadWriteProcess.pm file and ReadWriteProcess directory from site_perl, restarted the job, and isotovideo started successfully.
I will do some more tests.
Updated by gpathak about 2 months ago
- File qa-power8-crash qa-power8-crash added
Kernel 6.4 crashed after running for nearly a day.
Something related to #162296
Updated by gpathak about 2 months ago · Edited
Executed some more jobs with Kernel 6.4:
- https://openqa.opensuse.org/tests/4780030
- https://openqa.opensuse.org/tests/4780019
- https://openqa.opensuse.org/tests/4780250
- https://openqa.opensuse.org/tests/4780251
- https://openqa.opensuse.org/tests/4780241
Seems the machine is stable now, will keep it under observation to see if it crashes again, if it doesn't crash then I will move to next machine and upgrade kerosene.
Updated by gpathak about 2 months ago · Edited
Disabled worker slots 11..30 on kerosene to redirect some job schedule to run on qa-power8.
Updated by gpathak about 2 months ago
Upgraded kerosene to Leap 15.6 as well, and is under observation.
Updated by gpathak about 2 months ago
- File crash-qa-power8 crash-qa-power8 added
qa-power8-3 crashed again
Updated by gpathak about 2 months ago
gpathak wrote in #note-28:
qa-power8-3 crashed again
Installed old firewalld package
zypper in --oldpackage https://download.opensuse.org/update/leap/15.3/sle/noarch/firewalld-0.9.3-150300.3.3.1.noarch.rpm https://download.opensuse.org/update/leap/15.3/sle/noarch/python3-firewall-0.9.3-150300.3.3.1.noarch.rpm https://download.opensuse.org/update/leap/15.3/sle/noarch/firewalld-lang-0.9.3-150300.3.3.1.noarch.rpm
and added package lock zypper al -m "boo#1227616" *firewall*
Kerosene is also crashing but it seems unrelated to firewall (I am not sure at this point because I am unable to get any crash log yet)
The issue on kerosene seems to be related to corrupted filesystem of node /dev/sdb1
[ 125.598476][ T4515] EXT4-fs error (device sdb1): ext4_lookup:1858: inode #22282262: comm perl: deleted inode referenced: 22315870
[ 125.861617][ T4515] EXT4-fs error (device sdb1): ext4_lookup:1858: inode #22282262: comm perl: deleted inode referenced: 22315865
[ 125.877535][ T4515] EXT4-fs error (device sdb1): ext4_lookup:1858: inode #22282262: comm perl: deleted inode referenced: 22315864
[ 140.606753][ T4035] EXT4-fs error (device sdb1) in ext4_free_inode:362: Corrupt filesystem
[ 140.609626][ T4035] EXT4-fs error (device sdb1) in ext4_free_inode:362: Corrupt filesystem
[ 140.622667][ T4035] EXT4-fs error (device sdb1) in ext4_free_inode:362: Corrupt filesystem
[ 141.286896][ T4035] EXT4-fs error (device sdb1) in ext4_free_inode:362: Corrupt filesystem
[ 141.295465][ T4035] EXT4-fs error (device sdb1) in ext4_free_inode:362: Corrupt filesystem
[ 141.392507][ T4035] EXT4-fs error (device sdb1) in ext4_free_inode:362: Corrupt filesystem
[ 141.395382][ T4035] EXT4-fs error (device sdb1) in ext4_free_inode:362: Corrupt filesystem
[ 141.399007][ T4035] EXT4-fs error (device sdb1) in ext4_free_inode:362: Corrupt filesystem
[ 141.403024][ T4035] EXT4-fs error (device sdb1) in ext4_free_inode:362: Corrupt filesystem
[ 141.407136][ T4035] EXT4-fs error (device sdb1) in ext4_free_inode:362: Corrupt filesystem
[ 174.313161][ T4455] EXT4-fs error (device sdb1): ext4_lookup:1858: inode #22282268: comm perl: deleted inode referenced: 22315988
[ 174.327871][ T4455] EXT4-fs error (device sdb1): ext4_lookup:1858: inode #22282268: comm perl: deleted inode referenced: 22315987
[ 174.339871][ T4455] EXT4-fs error (device sdb1): ext4_lookup:1858: inode #22282268: comm perl: deleted inode referenced: 22315986
[ 174.343795][ T4455] EXT4-fs error (device sdb1): ext4_lookup:1858: inode #22282268: comm perl: deleted inode referenced: 22554957
[ 174.349235][ T4455] EXT4-fs error (device sdb1): ext4_lookup:1858: inode #22282268: comm perl: deleted inode referenced: 22315988
[ 174.351765][ T4455] EXT4-fs error (device sdb1): ext4_lookup:1858: inode #22282268: comm perl: deleted inode referenced: 22315987
[ 174.355750][ T4455] EXT4-fs error (device sdb1): ext4_lookup:1858: inode #22282268: comm perl: deleted inode referenced: 22315986
[ 174.359731][ T4455] EXT4-fs error (device sdb1): ext4_lookup:1858: inode #22282268: comm perl: deleted inode referenced: 22554957
[ 174.368650][ T4455] EXT4-fs error (device sdb1): ext4_lookup:1858: inode #22282268: comm perl: deleted inode referenced: 22315988
[ 174.371705][ T4455] EXT4-fs error (device sdb1): ext4_lookup:1858: inode #22282268: comm perl: deleted inode referenced: 22315987
[ 181.099461][ T4045] EXT4-fs error (device sdb1): ext4_lookup:1858: inode #22282268: comm worker: deleted inode referenced: 22315988
[ 181.145671][ T4045] EXT4-fs error (device sdb1): ext4_lookup:1858: inode #22282268: comm worker: deleted inode referenced: 22315987
[ 181.149643][ T4045] EXT4-fs error (device sdb1): ext4_lookup:1858: inode #22282268: comm worker: deleted inode referenced: 22315986
Updated by gpathak about 2 months ago · Edited
19-01-2025: Reverted kerosene to version 15.5 to enable the execution of scheduled/blocked PPC64 tests
19-01-2025: Applied the solution from #162296 on qa-power8-3 (ref https://progress.opensuse.org/issues/162296#note-35). The system remains stable, with all 8 slots successfully running tests for over 24 hours
Will be upgrading kerosene-8 as well.
Updated by gpathak about 2 months ago
Kerosene-8 is also upgraded to 15.6 running kernel 6.4.0-150600.23.33-default
Updated by gpathak about 2 months ago · Edited
- Status changed from In Progress to Feedback
@okurz
Both power-8 machines in o3 infra are upgraded to Leap 15.6 Kernel 6.4.
Moving it to feedback.
Updated by okurz about 2 months ago
- Status changed from Feedback to Workable
- What about https://progress.opensuse.org/issues/169939#Rollback-Actions
- Can you please comment on the bugzilla ticket about the kernel regression which prevented us kernel upgrades since Leap 15.4
Updated by gpathak about 2 months ago
okurz wrote in #note-33:
- What about https://progress.opensuse.org/issues/169939#Rollback-Actions
- Can you please comment on the bugzilla ticket about the kernel regression which prevented us kernel upgrades since Leap 15.4
The machines are still getting unreachable with kernel 6.4.0-150600.23.33-default, not immediately after boot-up as mentioned in https://bugzilla.suse.com/show_bug.cgi?id=1227616#c2, but now the machines are going offline after approximately 24 Hours.
I can't find a way to collect the reason of the machines going offline.
Updated by gpathak about 2 months ago
This happened on kerosene: https://bugzilla.suse.com/show_bug.cgi?id=1227616#c15
It is not happening consistently everytime.
Updated by gpathak about 2 months ago
- Status changed from Workable to In Progress
Updated by gpathak about 2 months ago
- File Crash-Log.7z Crash-Log.7z added
Even after installing stable Kernel 6.13.0-1.g1513344-default from https://download.opensuse.org/repositories/Kernel:/stable/PPC/ on qa-power8, the machine crashed.
The solution applied on kerosene-8 with nftables replacing firewalld from #162296 also didn't work, the machine crashed.
Updated by gpathak about 2 months ago · Edited
- File qa-power8-softlockup-2.log qa-power8-softlockup-2.log added
- Status changed from In Progress to Blocked
Observed another softlockup on qa-power8 causing performance issue, making the machine slow to respond.
Filed separate bugzilla tickets for two different issues observed.
Blocking on
Updated by okurz about 1 month ago
@gpathak in your bug reports please add details about steps to reproduce and what statistics about failures you have. Also please reference the last good and the original bug report we had why we kept the kernel at the Leap 15.3 version
Updated by gpathak about 1 month ago · Edited
okurz wrote in #note-41:
@gpathak in your bug reports please add details about steps to reproduce and what statistics about failures you have. Also please reference the last good and the original bug report we had why we kept the kernel at the Leap 15.3 version
There are no clear steps to reproduce the issue at this time. The kernel on the Power8 machine occasionally crashes, causing the system to go offline while running an openQA test (though the specific test is unknown). This does not directly impact openQA results, as the job is simply marked as canceled due to the worker becoming unreachable.
The last known stable kernel version was 5.3.18.
Updated by openqa_review 27 days ago
- Due date set to 2025-02-26
Setting due date based on mean cycle time of SUSE QE Tools
Updated by gpathak 27 days ago · Edited
Right now I am focusing on one power8 machine and I am currently utilising qa-power8 for the task
Going back to square-one, starting it all over and recording what I did/doing here in this ticket.
12-Feb-2025:
- Re-enabled firewalld-2.0.1-150600.3.5.1 from http://download.opensuse.org/update/leap/15.6/sle/
- Disabled custom nftables systemd service
- added all available tap devices to bridge br1 with command
tapdevs=$(ip -o link show | awk -F': ' '{print $2}' | grep tap) && for i in $tapdevs; do echo $i; ovs-vsctl add-port br1 $i; donesince some tests were failing https://openqa.opensuse.org/tests/4851764 with error'tapXX' is not connected to bridge 'br1'
Updated by gpathak 26 days ago
gpathak wrote in #note-45:
Right now I am focusing on one power8 machine and I am currently utilising qa-power8 for the task
Going back to square-one, starting it all over and recording what I did/doing here in this ticket.12-Feb-2025:
- Re-enabled firewalld-2.0.1-150600.3.5.1 from http://download.opensuse.org/update/leap/15.6/sle/
- Disabled custom nftables systemd service
- added all available tap devices to bridge br1 with command
tapdevs=$(ip -o link show | awk -F': ' '{print $2}' | grep tap) && for i in $tapdevs; do echo $i; ovs-vsctl add-port br1 $i; donesince some tests were failing https://openqa.opensuse.org/tests/4851764 with error'tapXX' is not connected to bridge 'br1'
It's been more than 24 Hours and there are significant number of tests ran on qa-power8-3, so far the machine looks stable.
Let's wait and watch the behaviour until end of this week.
Updated by gpathak 25 days ago
- Status changed from In Progress to Feedback
Discussed this in the infra daily.
Putting this to feedback since we want to keep qa-power-8 machine under observation for more time to gain more confidence because from past experiences power8 machine always get into some issue after upgrade.
Updated by gpathak 24 days ago · Edited
gpathak wrote in #note-47:
Discussed this in the infra daily.
Putting this to feedback since we want to keep qa-power-8 machine under observation for more time to gain more confidence because from past experiences power8 machine always get into some issue after upgrade.
The openqa-continuous-update.service upgraded the kernel from 6.4.0-150600.23.33 to 6.4.0-150600.23.38 and seems like after that the kernel crashed again.
Downgraded the kernel version to 6.4.0-150600.23.33, added zypper package-lock zypper al -m "boo#1236380" *kernel-default* and zypper al -m "boo#1236380" kernel-default
Updated by gpathak 20 days ago · Edited
- Status changed from Feedback to Workable
gpathak wrote in #note-48:
gpathak wrote in #note-47:
Discussed this in the infra daily.
Putting this to feedback since we want to keep qa-power-8 machine under observation for more time to gain more confidence because from past experiences power8 machine always get into some issue after upgrade.The
openqa-continuous-update.serviceupgraded the kernel from6.4.0-150600.23.33to6.4.0-150600.23.38and seems like after that the kernel crashed again.
Downgraded the kernel version to6.4.0-150600.23.33, added zypper package-lockzypper al -m "boo#1236380" *kernel-default*andzypper al -m "boo#1236380" kernel-default
I think we have enough tests executed on qa-power8 and this machine seems stable till now.
I will go ahead and upgrade kerosene-8 as well.
Updated by gpathak 20 days ago
- Status changed from Workable to Feedback
gpathak wrote in #note-45:
12-Feb-2025:
- Re-enabled firewalld-2.0.1-150600.3.5.1 from http://download.opensuse.org/update/leap/15.6/sle/
- Disabled custom nftables systemd service
- added all available tap devices to bridge br1 with command
tapdevs=$(ip -o link show | awk -F': ' '{print $2}' | grep tap) && for i in $tapdevs; do echo $i; ovs-vsctl add-port br1 $i; donesince some tests were failing https://openqa.opensuse.org/tests/4851764 with error'tapXX' is not connected to bridge 'br1'
Upgraded kerosene-8 to Leap 15.6 Running Kernel 6.4.0-150600.23.33-default.
Moving this ticket again to feedback.
Updated by gpathak 18 days ago
gpathak wrote in #note-53:
spent time to setup kdump on qa-power8 since it went into the same state.
The kdump setup is not yet complete, will continue it later.
Did kdump setup on kerosene as well as qa-power-8, hopefully it should now generate a kernel dump if kernel crashes again in future
zypper in -y kexec-tools kdump-*- added below contents to
/etc/sysconfig/kdump
KDUMP_KERNELVER="/boot/vmlinux-6.4.0-150600.23.33-default"
KDUMP_CPUS=2
KDUMP_COMMANDLINE_APPEND=""
KDUMP_AUTO_RESIZE="false"
KDUMP_FADUMP="false"
KDUMP_FADUMP_SHELL="false"
KDUMP_IMMEDIATE_REBOOT="true"
KDUMP_SAVEDIR="/var/crash"
KDUMP_KEEP_OLD_DUMPS=2
KDUMP_FREE_DISK_SIZE=64
KDUMP_VERBOSE=0
KDUMP_DUMPLEVEL=31
KDUMP_DUMPFORMAT="compressed"
KDUMP_CONTINUE_ON_ERROR="true"
KDUMP_NETCONFIG="auto"
KDUMP_NET_TIMEOUT=30
- Symlinks for vmlinux and initrd in
/boot/directory should not be dangling - Added
GRUB_CMDLINE_LINUX_DEFAULT+=" crashkernel=1G"to/etc/default/gruband thenupdate-bootloader - Started kexec-load and kdump services
systemctl enable --now kexec-load.service; systemctl enable --now kdump - Rebooted the machine once
- Verified kdump by triggering a "kernel panic" with the procfs interface to Magic SysRq keys:
echo c > /proc/sysrq-trigger
Updated by livdywan 12 days ago
Discussed the options briefly:
- The best work-around idea currently is changing away from btrfs e.g. ext4 but that could obviously lead to corruption
- Automatic reboots like we do on some arm machines (which crashes less readily)
- Leave it for now. You made an amazing effort to find a working version. It is what it is. We voted in favor of this
Updated by gpathak 12 days ago
- Copied to action #177973: Dying disk on qa-power8-3: Needs replacement? size:S added
Updated by gpathak 12 days ago · Edited
livdywan wrote in #note-55:
Discussed the options briefly:
- The best work-around idea currently is changing away from btrfs e.g. ext4 but that could obviously lead to corruption
- Automatic reboots like we do on some arm machines (which crashes less readily)
- Leave it for now. You made an amazing effort to find a working version. It is what it is. We voted in favor of this
I just did a fresh Leap 15.6 installation on qa-power8-3, in my opinion the kernel in-stability seems to be ruled out because kerosene-8 is running flawlessly for more than 5 days.
I discovered some error message in boot logs (#177973) that can be a sign of dying storage medium, and I think it can be a cause of unstable behavior of qa-power8-3 machines, I am saying this because in most of the kernel crash logs of qa-power8, the stack trace points to kernel filesystem APIs for btrfs and in this case the rootfs is of type btrfs
Updated by gpathak 11 days ago
- Copied to action #178063: Investigate the effect of removing kernel package lock on kerosene-8 added
Updated by gpathak 11 days ago · Edited
- Status changed from Feedback to Resolved
Resolving this ticket as discussed in daily.
Created a separate ticket #177973 for investigating issue, as this is happening only on one machine.
kerosene-8 was updated successfully, I added a kernel package lock on kerosene-8 to be on the safe side cause we only have one reliable power8 machine, a follow-up ticket is created for this #178063 to investigate and attempt to remove the package lock.
Updated by gpathak 5 days ago
gpathak wrote in #note-57:
livdywan wrote in #note-55:
Discussed the options briefly:
- The best work-around idea currently is changing away from btrfs e.g. ext4 but that could obviously lead to corruption
- Automatic reboots like we do on some arm machines (which crashes less readily)
- Leave it for now. You made an amazing effort to find a working version. It is what it is. We voted in favor of this
I just did a fresh Leap 15.6 installation on qa-power8-3, in my opinion the kernel in-stability seems to be ruled out because kerosene-8 is running flawlessly for more than 5 days.
I discovered some error message in boot logs (#177973) that can be a sign of dying storage medium, and I think it can be a cause of unstable behavior of qa-power8-3 machines, I am saying this because in most of the kernel crash logs of qa-power8, the stack trace points to kernel filesystem APIs for btrfs and in this case the rootfs is of type btrfs
Since, the crash was more frequent, I rolled back qa-power8-3 to Leap 15.5. If the machine crashes again because of filesystem or inode issue then I think it can be handled in #177973