action #164979
closed[alert][grafana] File systems alert for WebUI /results size:S
0%
Description
Observation¶
Observed at 2024-08-06 07:17:00 +0200 CEST
One of the file systems /results is too full (> 90%)
See http://stats.openqa-monitor.qa.suse.de/d/WebuiDb?orgId=1&viewPanel=74
Current usage:
Filesystem Size Used Avail Use% Mounted on
/dev/vdd 7.0T 6.4T 681G 91% /results
Acceptance criteria¶
AC1: There is enough space and headroom on the affected file system /results, i.e. considerably more than 20%
Suggestions¶
- Check job group "logs" retention settings for "not-important" / "groupless" result and consider reducing the period
- Consider extending the silence period if fixing takes too long: https://stats.openqa-monitor.qa.suse.de/alerting/silence/9ee9b299-3d06-4234-97bf-6b84e2ad9a24/edit?alertmanager=grafana
- Reconsider the design of scheduling openqa-investigate for unreviewed jobs and possibly plan in a separate ticket
- Tell the security squad that their test scenario(s) are problematic and should fail less or be properly reviewed
- Tell the security squad about their test scenario(s) which is significantly bigger than other jobs and consider reducing the space usage, e.g. save less or compress stuff
Rollback steps¶
- DONE
Remove silence https://stats.openqa-monitor.qa.suse.de/alerting/silence/9ee9b299-3d06-4234-97bf-6b84e2ad9a24/edit?alertmanager=grafana
Out of scope¶
- Better accounting e.g. linking of investigation jobs to their original groups -> #164988
Files
| Screenshot_20240807_093724_results_usage_6_months.png (33.2 KB) Screenshot_20240807_093724_results_usage_6_months.png | |||
| clipboard-202408071619-oi5o1.png (73.6 KB) clipboard-202408071619-oi5o1.png |
Updated by nicksinger 5 months ago
- Copied from action #129244: [alert][grafana] File systems alert for WebUI /results size:M added
Updated by mkittler 5 months ago
We had an increase of 10 percent points in the last 7 days. The graph also shows that the cleanup is still generally working. The Minion dashboard and gru logs also look generally good (e.g. https://openqa.suse.de/minion/jobs?task=limit_results_and_logs). I nevertheless triggered another result cleanup.
It looks like the group of groupless jobs is the biggest contributor: https://stats.openqa-monitor.qa.suse.de/d/nRDab3Jiz/openqa-jobs-test?orgId=1&viewPanel=19
Updated by mkittler 4 months ago · Edited
The query select id, TEST, result, pg_size_pretty(result_size) as result_size_pretty from jobs where group_id is null and t_created > '2024-07-30' and state = 'done' and archived = false order by result_size desc; shows lots of oscap_ansible_anssi_bp28_high jobs like https://openqa.suse.de/tests/15082557.
The following query shows this more clearly:
openqa=> select (substring(TEST from 0 for position(':' in TEST))) as short_name, min(TEST) as example_name, pg_size_pretty(sum(result_size)) as result_size_pretty from jobs where group_id is null and t_created > '2024-07-30' and state = 'done' and archived = false group by short_name order by sum(result_size) desc;
short_name | example_name | result_size_pretty
------------------------------------------------+-------------------------------------------------------------------------------------------------------+--------------------
oscap_bash_anssi_bp28_high | oscap_bash_anssi_bp28_high:investigate:bisect_without_32673 | 355 GB
oscap_ansible_anssi_bp28_high | oscap_ansible_anssi_bp28_high:investigate:bisect_without_32673 | 350 GB
| 390x-2 | 18 GB
gnome | gnome:investigate:last_good_build::34061:mozilla-nss | 3098 MB
qam-regression-firefox-SLES | qam-regression-firefox-SLES:investigate:bisect_without_34295 | 2784 MB
oscap_ansible_cis | oscap_ansible_cis:investigate:bisect_without_33993 | 2436 MB
cryptlvm | cryptlvm:investigate:last_good_build::34061:mozilla-nss | 2421 MB
jeos-containers-podman | jeos-containers-podman:investigate:bisect_without_33993 | 2194 MB
jeos-containers-docker | jeos-containers-docker:investigate:bisect_without_33585 | 2173 MB
docker_tests | docker_tests:investigate:bisect_without_33585 | 2113 MB
qam_ha_hawk_haproxy_node01 | qam_ha_hawk_haproxy_node01:investigate:last_good_build::32673:python-docutils | 2048 MB
jeos-extratest | jeos-extratest:investigate:bisect_without_33993 | 2021 MB
qam_ha_hawk_haproxy_node02 | qam_ha_hawk_haproxy_node02:investigate:last_good_build::32673:python-docutils | 1921 MB
qam_ha_hawk_client | qam_ha_hawk_client:investigate:last_good_build::32673:python-docutils | 1891 MB
fips_env_mode_tests_crypt_web | fips_env_mode_tests_crypt_web:investigate:bisect_without_33585 | 1705 MB
jeos-filesystem | jeos-filesystem:investigate:bisect_without_33585 | 1694 MB
fips_ker_mode_tests_crypt_web | fips_ker_mode_tests_crypt_web:investigate:bisect_without_33585 | 1663 MB
qam_wicked_startandstop_sut | qam_wicked_startandstop_sut:investigate:last_good_build:20240804-1 | 1440 MB
qam_ha_rolling_upgrade_migration_node01 | qam_ha_rolling_upgrade_migration_node01:investigate:last_good_build::32673:python-docutils | 1404 MB
slem_image_default | slem_image_default:investigate:bisect_without_28151 | 1350 MB
slem_fips_docker | slem_fips_docker:investigate:bisect_without_35050 | 1141 MB
slem_installation_autoyast | slem_installation_autoyast:investigate:bisect_without_28150 | 1105 MB
wsl2-main+wsl_gui | wsl2-main+wsl_gui:investigate:last_good_build:2.374 | 1072 MB
Problematic job groups:
openqa=> select concat('https://openqa.suse.de/group_overview/', group_id) as group_url, (select name from job_group_parents where id = (select parent_id from job_groups where id = group_id)) as parent_group_name, (select name from job_groups where id = group_id) as group_name, count(id) as job_count from jobs where TEST = 'oscap_bash_anssi_bp28_high' group by group_id order by job_count desc;
group_url | parent_group_name | group_name | job_count
-------------------------------------------+---------------------------------+--------------------------------------+-----------
https://openqa.suse.de/group_overview/429 | Maintenance: Aggregated updates | Security Maintenance Updates | 839
https://openqa.suse.de/group_overview/268 | SLE 15 | Security | 141
https://openqa.suse.de/group_overview/517 | Maintenance: QR | Maintenance - QR - SLE15SP5-Security | 43
https://openqa.suse.de/group_overview/462 | Maintenance: QR | Maintenance - QR - SLE15SP4-Security | 38
https://openqa.suse.de/group_overview/588 | Maintenance: QR | Maintenance - QR - SLE15SP6-Security | 1
(5 rows)
Updated by mkittler 4 months ago
Those are the most offending jobs:
openqa=> select count(id), pg_size_pretty(sum(result_size)) from jobs where group_id is null and TEST like 'oscap_%_anssi_bp28_high:investigate%' and t_finished < '2024-08-06';
count | pg_size_pretty
-------+----------------
2488 | 548 GB
(1 row)
openqa=> select count(id), pg_size_pretty(sum(result_size)) from jobs where group_id is null and TEST like 'oscap_%_anssi_bp28_high:investigate%' and t_finished >= '2024-08-06';
count | pg_size_pretty
-------+----------------
700 | 157 GB
(1 row)
I am deleting currently the jobs from before today via:
openqa=> \copy (select id from jobs where group_id is null and TEST like 'oscap_%_anssi_bp28_high:investigate%' and t_finished < '2024-08-06') to '/tmp/jobs_to_delete' csv;
COPY 2488
martchus@openqa:~> for id in $(cat /tmp/jobs_to_delete) ; do sudo openqa-cli api --osd -X delete jobs/$id ; done
Updated by okurz 4 months ago
- Copied to action #164988: Better accounting for openqa-investigation jobs size:S added
Updated by okurz 4 months ago
mkittler wrote in #note-10:
The deletion went through and now we're back at 83 % which should be good enough for now.
83% means that the space-aware cleanup can not delete more but should be able to do so so I think the job group quotas in sum are bigger than the overall available space in /results, isn't it?
Updated by mkittler 4 months ago
I mentioned the problematic scenarios on the Slack channel #discuss-qe-security. Let's see what the response will be. If it is not helpful and if https://gitlab.suse.de/openqa/salt-states-openqa/-/merge_requests/1243 doesn't help well enough we'll have to resort to the sledge hammer method of disabling the investigation jobs for all involved jobs groups (see #164979#note-5) by adjusting the exclude_group_regex configured in salt states.
@okurz I'm not entire sure what you're getting at. We're above the threshold for skipping/executing the cleanup - in other words the cleanup is executed and that is expected. Whether the sum of the quotas is bigger than the overall space is not calculatable because we use time-based quotas.
Updated by openqa_review 4 months ago
- Due date set to 2024-08-21
Setting due date based on mean cycle time of SUSE QE Tools
Updated by okurz 4 months ago · Edited
- File Screenshot_20240807_093724_results_usage_6_months.png Screenshot_20240807_093724_results_usage_6_months.png added
Taking a look into the last 6 months one should clearly see that the space-aware cleanup was able to keep enough free space only until 2024-04
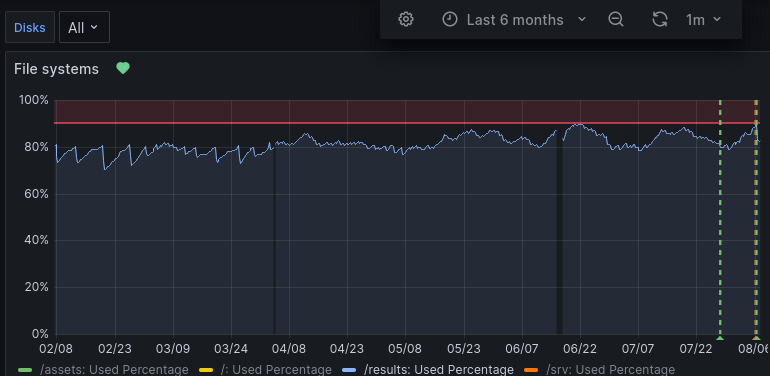
So in my understanding that means that the job group quotas in sum exceed what is available and that should be reduced.
Updated by mkittler 4 months ago
I suppose for deleting the jobs we needed to file a SR on https://gitlab.suse.de/qe-security/osd-sle15-security. This should also cover the 5xx groups not explicitly mentioned in their README. We just needed to search for _anssi_bp28_high and delete all entries in the YAML that ends with it.
Updated by mkittler 4 months ago
I just wanted to see on what products the problematic test scenarios fail specifically. However, not it looks like they have all been fixed:
- https://openqa.suse.de/tests/overview?test=oscap_ansible_anssi_bp28_high
- https://openqa.suse.de/tests/overview?test=oscap_bash_anssi_bp28_high
With that I hope we can refrain from removing those scenarios.
Updated by mkittler 4 months ago
I now deleted all jobs from \copy (select id from jobs where group_id is null and TEST like 'oscap_%_anssi_bp28_high:investigate%') to '/tmp/jobs_to_delete' csv; to free 160 GiB of disk space. Now we're at 81 %. So we'd still have to reduce quotas. However, it makes probably sense to wait for a response in https://sd.suse.com/servicedesk/customer/portal/1/SD-164873 first.
Updated by mkittler 4 months ago
- Status changed from Blocked to Feedback
The scenarios mentioned in note #164979#note-18 fail again as of today and the investigation jobs have already occupied 80 GiB. I'm deleting all investigation jobs. All jobs in the scenarios seem to have proper bugrefs now. So let's see whether the carry over works and further investigation jobs are prevented. (Although it is already problematic that we use 80 GiB on the first occurrence. So even if those scenarios are reviewed in a timely manner that's a lot of disk space being used.)
Updated by viktors.trubovics 4 months ago
Hello!
One of possible long term solution can be move/change OpenQA storage to the BTRFS FS level compression.
It effectively compressing more than x100 times text files.
I solved this way storage problem of storing huge amount of small text files (billions of files and terabytes of text) on terabyte storage.
I created PR for OSCAP tests: Compress and upload test artifacts https://github.com/os-autoinst/os-autoinst-distri-opensuse/pull/19967
Updated by mkittler 4 months ago · Edited
Looks like the carry over generally works, see https://openqa.suse.de/tests/15198055#comments. 19 GiB have nevertheless piled up again for investigation jobs. I'll check the situation next week and possible delete jobs again manually.
EDIT: Not much more has piled up. I'm deleting the now 20 GiB of investigation jobs now nevertheless.
Updated by mkittler 4 months ago
- Status changed from Feedback to Resolved
We only gained additional 2431 MiB from new investigation jobs of the problematic scenarios. They are now also better maintained and smaller thanks to compression. We also have #164988 for better accounting of such jobs in general. The additional 1 TiB also gives us more headroom. With all of that I guess the alert is handled for now (and the silence has been removed for a while now) so I consider this ticket resolved.