action #107875
closed
[alert][osd] Apache Response Time alert size:M
Added by mkittler about 3 years ago.
Updated 10 months ago.
Description
Observation¶
We've got the alert again on March 3, 2022 09:00:40:
[Alerting] Apache Response Time alert
The apache response time exceeded the alert threshold. * Check the load of the web UI host * Consider restarting the openQA web UI service and/or apache Also see https://progress.opensuse.org/issues/73633
Metric name
Value
Min
18733128.83
Relevant panel: https://stats.openqa-monitor.qa.suse.de/d/WebuiDb/webui-summary?tab=alert&viewPanel=84
Tina wrote in chat
if anyone was wondering about the short high load on osd, I fetched /api/v1/jobs and it took 10 minutes
but that was already on Wednesday so it shouldn't have been caused this.
Further data points
- High CPU likely didn't affect scheduling, or we should've had other reports of it
- High CPU wouldn't cause a spike in failures in jobs?
Suggestions¶
- The apache log parsing seems to be quite heavy. Can we reduce the amount of data parsed by telegraf
- Reduce interval we take new data points in telegraf
- Extend alerting measurement period from 5m to 30m (or higher) to smooth out gaps
Files
I've also just had a look. The InfluxDB query is very slot when selecting a time-range like "Last 2 days". Maybe we're collecting too many data points per time. Regardless, it looks like gaps causing this, indeed:
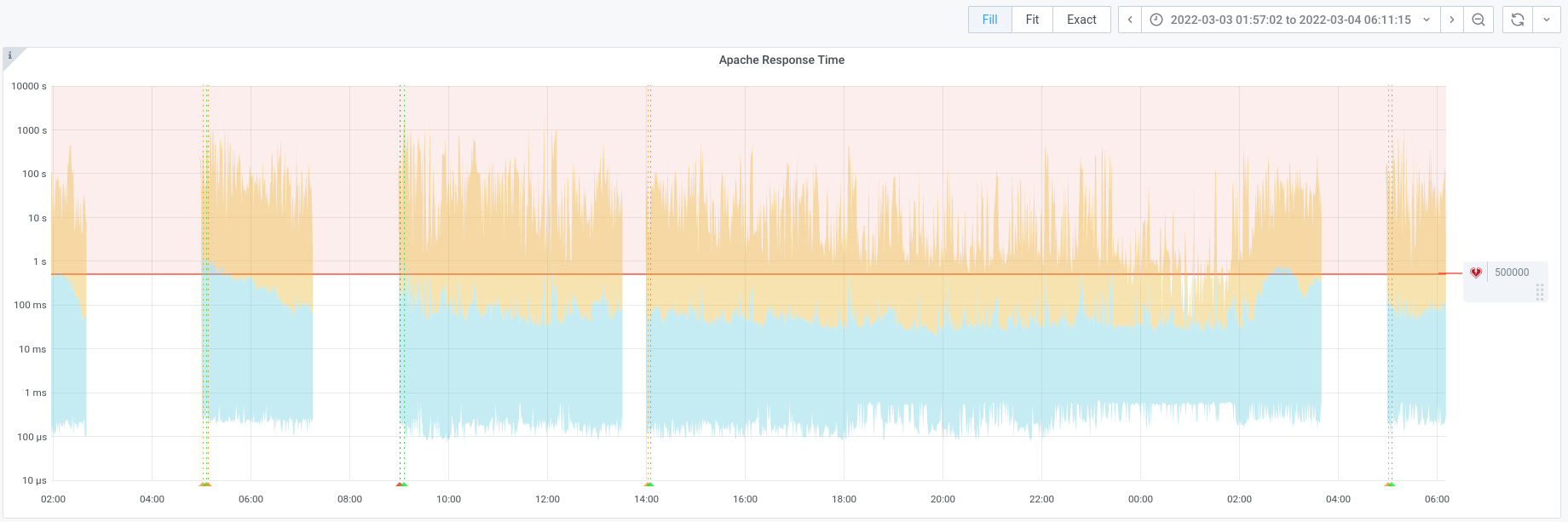
Some other graphs have gaps as well but not all:
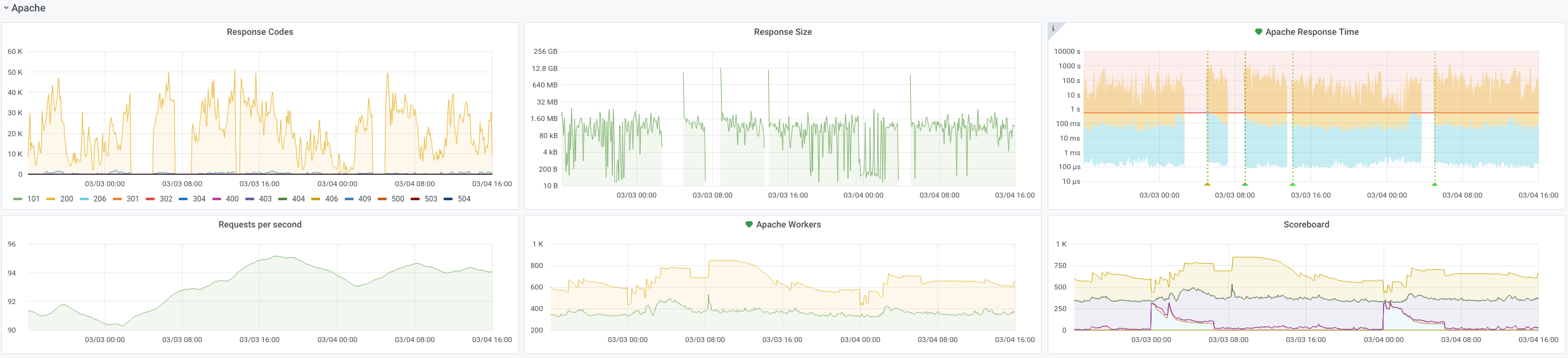
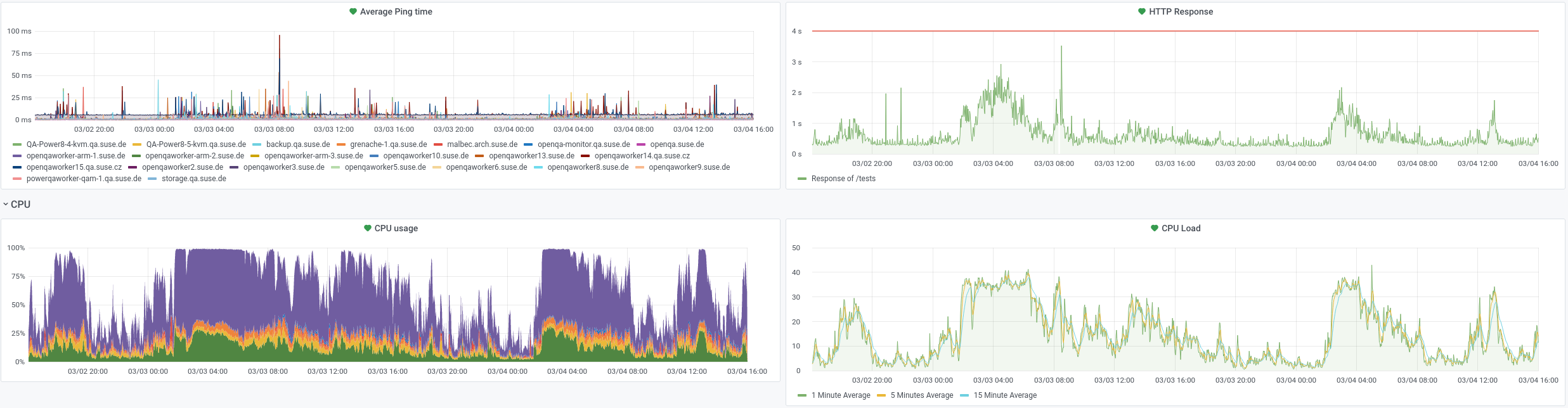
The CPU load was quite high from time to time but the HTTP response graph shows no gaps:
- Priority changed from High to Urgent
- Related to action #107257: [alert][osd] Apache Response Time alert size:M added
- Related to action #96807: Web UI is slow and Apache Response Time alert got triggered added
- Subject changed from [alert][osd] Apache Response Time alert to [alert][osd] Apache Response Time alert size:M
- Description updated (diff)
- Status changed from New to Workable
- Assignee set to tinita
- Status changed from Workable to In Progress
All graphs with gaps are reading from the apache_log table, but the comment Response time measured by the apache proxy [...] suggests that this data comes from the proxy logs and not from apache itself.
I need to find out where to find the proxy and the logs.
tinita wrote:
All graphs with gaps are reading from the apache_log table, but the comment Response time measured by the apache proxy [...] suggests that this data comes from the proxy logs and not from apache itself.
I need to find out where to find the proxy and the logs.
We use apache as the reverse proxy for openQA, so apache == proxy.
- Due date set to 2022-03-24
Setting due date based on mean cycle time of SUSE QE Tools
- Status changed from In Progress to Feedback
- Status changed from Feedback to Resolved
So even after the interval change to 30s was merged, we still have gaps (there was a one hour gap this morning, in the middle of a 3 hour timeframe with high load).
But we haven't seen alerts, so I consider this ticket resolved, as we have a followup ticket about the high load.
- Related to action #128789: [alert] Apache Response Time alert size:M added
- Due date deleted (
2022-03-24)
Also available in: Atom
PDF