action #158059
closedopenQA Project (public) - coordination #110833: [saga][epic] Scale up: openQA can handle a schedule of 100k jobs with 1k worker instances
openQA Project (public) - coordination #108209: [epic] Reduce load on OSD
OSD unresponsive or significantly slow for some minutes 2024-03-26 13:34Z
0%
Description
Observation¶
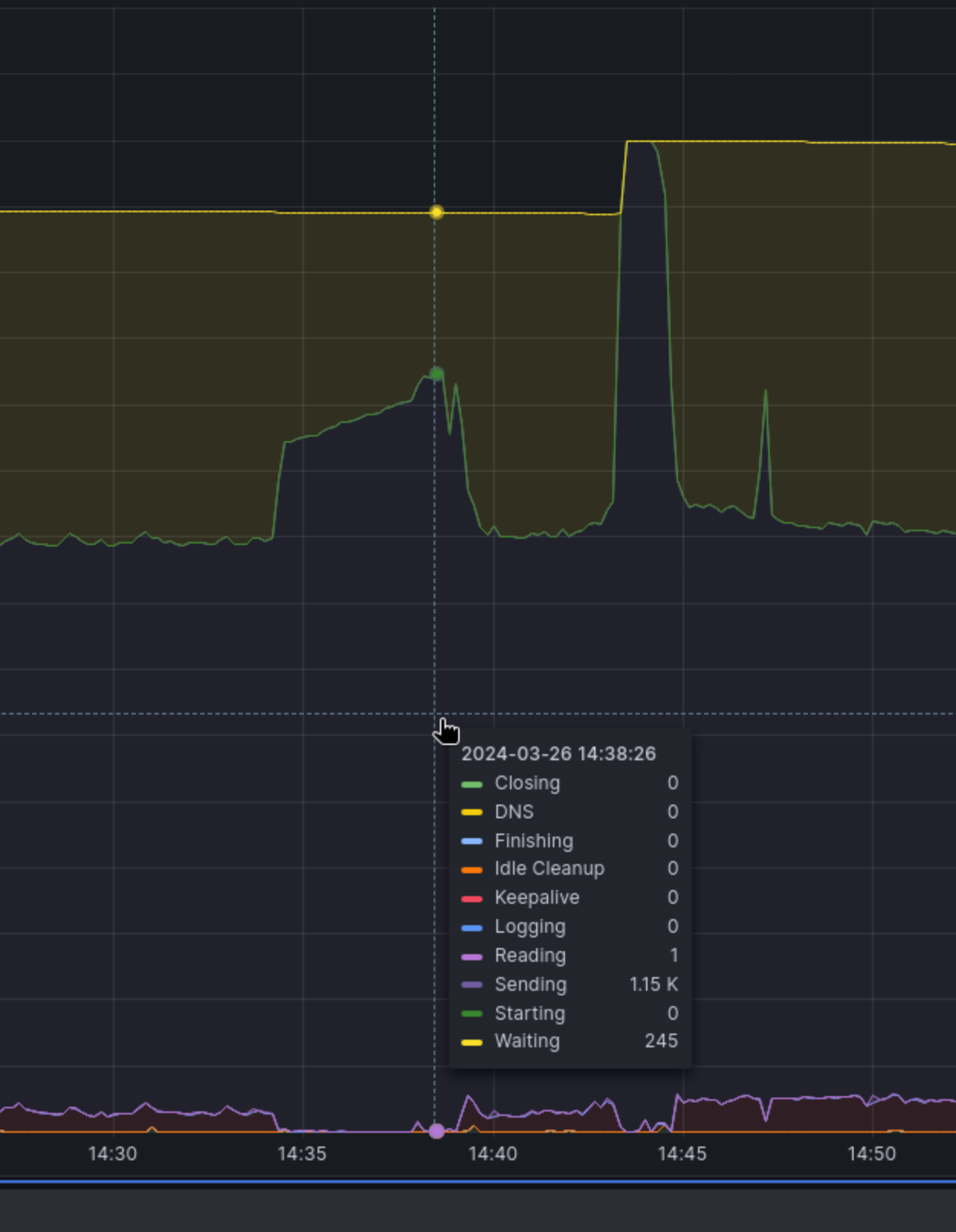
Another instance of unresponsiveness on 2024-03-26 1334Z, https://monitor.qa.suse.de/d/WebuiDb/webui-summary?orgId=1&from=1711459478659&to=1711461053083 . A sudden unresponsiveness with indicators in before. CPU usage and other parameters moderate and getting low after the unresponsiveness started. In the system journal on OSD the first obvious symptom:
Mar 26 14:34:50 openqa telegraf[27132]: 2024-03-26T13:34:50Z E! [inputs.http] Error in plugin: [url=https://openqa.suse.de/admin/influxdb/jobs]: Get "https://openqa.suse.de/admin/influxdb/jobs": context deadline exceeded
In before a lot of
Updating seen of worker …
And some few
Mar 26 14:34:23 openqa openqa-livehandler-daemon[28668]: [debug] client disconnected: …
…
Mar 26 14:34:23 openqa openqa-livehandler-daemon[28668]: [debug] client connected: …
Could this have to do with long-running live session connections exhausting some worker pool?
In /var/log/error_log it looks like there are every couple of minutes some timeout messages but a surge after the incident start. And certain errors during the outage. From grep 'Mar 26 14:' error_log | grep -v 'AH01110' | sed 's/client [^]]*/:masked:/':
[Tue Mar 26 14:38:39.904559 2024] [proxy_http:error] [pid 31986] (70007)The timeout specified has expired: [:masked:] AH01102: error reading status line from remote server localhost:9526, referer: https://openqa.suse.de/tests/13875288
[Tue Mar 26 14:38:39.904677 2024] [proxy:error] [pid 31986] [:masked:] AH00898: Error reading from remote server returned by /tests/13875288/streaming, referer: https://openqa.suse.de/tests/13875288
[Tue Mar 26 14:38:39.906407 2024] [negotiation:error] [pid 31986] [:masked:] AH00690: no acceptable variant: /usr/share/apache2/error/HTTP_BAD_GATEWAY.html.var, referer: https://openqa.suse.de/tests/13875288
[Tue Mar 26 14:38:42.788536 2024] [proxy_http:error] [pid 20896] (70007)The timeout specified has expired: [:masked:] AH01102: error reading status line from remote server localhost:9526, referer: https://openqa.suse.de/tests/13875288
[Tue Mar 26 14:38:42.788653 2024] [proxy:error] [pid 20896] [:masked:] AH00898: Error reading from remote server returned by /tests/13875288/streaming, referer: https://openqa.suse.de/tests/13875288
[Tue Mar 26 14:38:42.789293 2024] [negotiation:error] [pid 20896] [:masked:] AH00690: no acceptable variant: /usr/share/apache2/error/HTTP_BAD_GATEWAY.html.var, referer: https://openqa.suse.de/tests/13875288
…
[Tue Mar 26 14:39:15.460642 2024] [negotiation:error] [pid 16619] [:masked:] AH00690: no acceptable variant: /usr/share/apache2/error/HTTP_BAD_GATEWAY.html.var, referer: https://openqa.suse.de/tests/13875288
[Tue Mar 26 14:39:16.699839 2024] [proxy_http:error] [pid 16323] (70007)The timeout specified has expired: [:masked:] AH01102: error reading status line from remote server localhost:9526, referer: https://openqa.suse.de/tests/13875288
[Tue Mar 26 14:39:16.699908 2024] [proxy:error] [pid 16323] [:masked:] AH00898: Error reading from remote server returned by /tests/13875288/liveterminal, referer: https://openqa.suse.de/tests/13875288
[Tue Mar 26 14:39:16.700229 2024] [negotiation:error] [pid 16323] [:masked:] AH00690: no acceptable variant: /usr/share/apache2/error/HTTP_BAD_GATEWAY.html.var, referer: https://openqa.suse.de/tests/13875288
The above look like symptoms that we can use to improve our monitoring at least. Or should we really just switch to nginx in before?
Files
{kind=link}
Updated by okurz about 1 year ago
- Due date set to 2024-04-09
- Status changed from New to Feedback
Asking the team for vote https://suse.slack.com/archives/C02AJ1E568M/p1711462651911559
New OSD unresponsiveness https://progress.opensuse.org/issues/158059 . Should we 1. improve our monitoring, 2. switch to nginx, 3. ignore it and do other more important stuff. Please vote!
I also asked in #eng-testing. Let's see what comes out of it.
Updated by kraih about 1 year ago
Having looked over the monitoring data from the most recent case of OSD being unresponsive, there was some interesting information. Most importantly there was a significant spike in write activity by Apache visible on the scoreboard. That could indicate that a huge number of file downloads were exhausting our entire pool of Apache worker processes (since Apache workers only handle one connection at a time). This is indeed a problem where switching to nginx (like we did for O3 before) could be of significant benefit.
Updated by okurz about 1 year ago
- Related to action #130636: high response times on osd - Try nginx on OSD size:S added
Updated by okurz about 1 year ago
- Status changed from Feedback to Resolved
I asked for a vote and in #eng-testing there are 2 votes for better monitoring and 5 for nginx, excluding my own. In #team-qa-tools 3 votes for nginx, 0 for the other options. So next stop: #130636
Updated by okurz about 1 year ago
- Related to action #159396: Repeated HTTP Response alert for /tests and unresponsiveness due to potential detrimental impact of pg_dump (was: HTTP Response alert for /tests briefly going up to 15.7s) size:M added