action #110296
closedMachines within .qa.suse.de unavailable (was: Some ipmi workers become offline which affects PublicRC-202204 candidate Build137.1 test run)
0%
Description
Observation¶
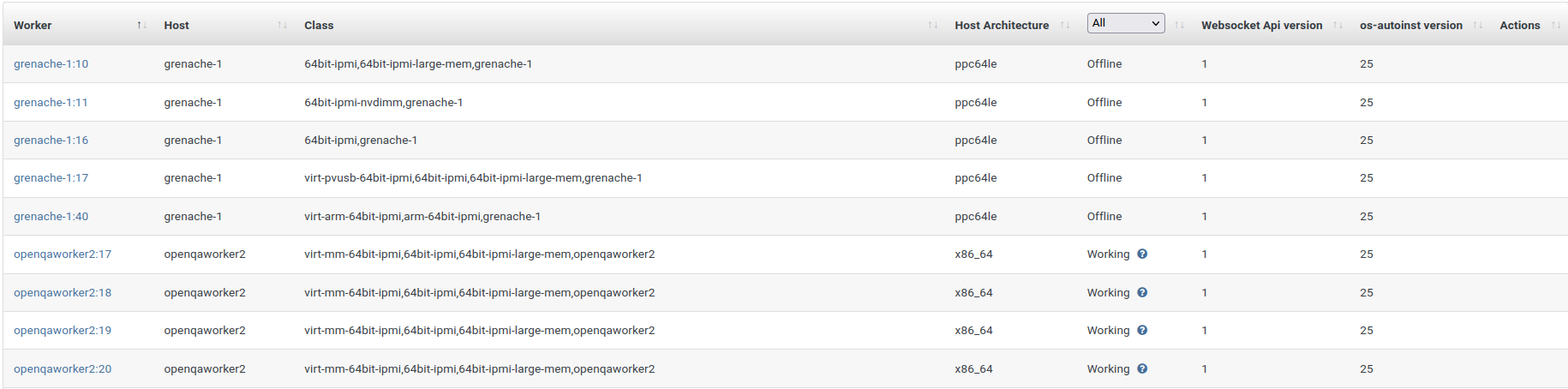
Some ipmi workers become offline which prevents tests, for example virtualization tests from running in a timely manner, especially current PublicRC-202204 candidate Build137.1 test run:
grenache-1:10 grenache-1 64bit-ipmi,64bit-ipmi-large-mem,grenache-1 ppc64le Offline 1 25
grenache-1:11 grenache-1 64bit-ipmi-nvdimm,grenache-1 ppc64le Offline 1 25
grenache-1:16 grenache-1 64bit-ipmi,grenache-1 ppc64le Offline 1 25
grenache-1:17 grenache-1 virt-pvusb-64bit-ipmi,64bit-ipmi,64bit-ipmi-large-mem,grenache-1 ppc64le Offline 1 25
grenache-1:40 grenache-1 virt-arm-64bit-ipmi,arm-64bit-ipmi,grenache-1 ppc64le Offline 1 25
Steps to reproduce¶
- Go to https://openqa.suse.de/admin/workers
- Search ipmi workers
- List all ipmi workers out
Problem¶
Some ipmi workers become offline
Suggestion¶
- Ensure all ipmi workers online and function as usual
Workaround¶
n/a
Files
| some-ipmi-workers-offline.png (89.1 KB) some-ipmi-workers-offline.png | |||
| broken-pipe.png (4.12 KB) broken-pipe.png | |||
| no-boot-device.png (8.19 KB) no-boot-device.png |
Updated by okurz almost 3 years ago
- Target version set to Ready
Seems to be related to current problems in the .qa.suse.de
Updated by waynechen55 almost 3 years ago
- File broken-pipe.png broken-pipe.png added
- Target version deleted (
Ready)
okurz wrote:
Seems to be related to current problems in the .qa.suse.de
Not sure whether the "working worker" really work, because I saw this:

openqaworker2:17 openqaworker2 virt-mm-64bit-ipmi,64bit-ipmi,64bit-ipmi-large-mem,openqaworker2 x86_64 Working 1 25
openqaworker2:18 openqaworker2 virt-mm-64bit-ipmi,64bit-ipmi,64bit-ipmi-large-mem,openqaworker2 x86_64 Working 1 25
openqaworker2:19 openqaworker2 virt-mm-64bit-ipmi,64bit-ipmi,64bit-ipmi-large-mem,openqaworker2 x86_64 Working 1 25
openqaworker2:20 openqaworker2 virt-mm-64bit-ipmi,64bit-ipmi,64bit-ipmi-large-mem,openqaworker2 x86_64 Working 1 25
Maybe all workers become "down".
Updated by waynechen55 almost 3 years ago
- Target version deleted (
Ready)
Confirmed all ipmi workers can not take jobs now, including those "working" ones. So offline/broken ones should be brought up and "working" ones should be restarted/serviced somehow.
Updated by osukup almost 3 years ago
waynechen55 wrote:
Confirmed all ipmi workers can not take jobs now, including those "working" ones. So offline/broken ones should be brought up and "working" ones should be restarted/serviced somehow.
which is logical if is qa.suse.de net down because faulty switch as @okurz wrote in https://progress.opensuse.org/issues/110296#note-2
Updated by livdywan almost 3 years ago
osukup wrote:
which is logical if is qa.suse.de net down because faulty switch as @okurz wrote in #110296#note-2
See https://sd.suse.com/servicedesk/customer/portal/1/SD-84633
Updated by okurz almost 3 years ago
- Status changed from New to Blocked
- Assignee set to okurz
- Target version set to Ready
please keep the "target version" in the ticket. Blocked by https://sd.suse.com/servicedesk/customer/portal/1/SD-84633
Updated by waynechen55 almost 3 years ago
- File no-boot-device.png no-boot-device.png added
- Assignee deleted (
okurz) - Target version deleted (
Ready)
okurz wrote:
please keep the "target version" in the ticket. Blocked by https://sd.suse.com/servicedesk/customer/portal/1/SD-84633
I do not have permission to view this ticket. So what is the situation now ? It looks like all SUT machines can not function as usual:
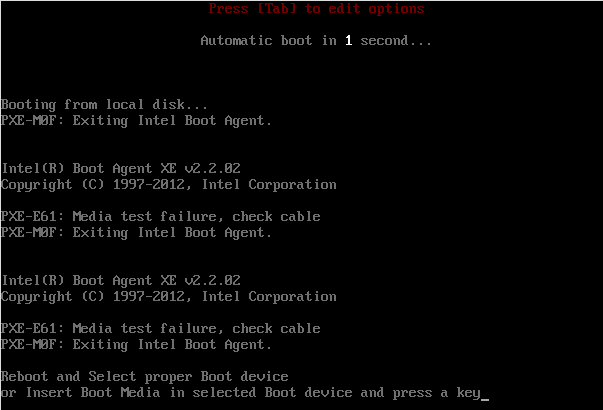
Please refer to Build137.1 Virtualization Acceptance Group, x86_64 failure and aarch64 failure
The failure involves following steps in boot_from_pxe module:
1.Start host boot from pxe
2.Assert pxe menu needle
3.Press 'esc' key on pxe menu screen
4.Type strings after 'boot:'
/mnt/openqa/repo/SLE-15-SP4-Online-x86_64-Build137.1-Media1/boot/x86_64/loader/linux initrd=/mnt/openqa/repo/SLE-15-SP4-Online-x86_64-Build137.1-Media1/boot/x86_64/loader/initrd install=http://openqa.suse.de/assets/repo/SLE-15-SP4-Online-x86_64-Build137.1-Media1?device=eth0 ifcfg=eth0=dhcp4 plymouth.enable=0 Y2DEBUG=1 vga=791 video=1024x768 console=ttyS1,115200 linuxrc.log=/dev/ttyS1 linuxrc.core=/dev/ttyS1 linuxrc.debug=4,trace reboot_timeout=0 ssh=1 sshpassword=nots3cr3t regurl=http://all-137.1.proxy.scc.suse.de kernel.softlockup_panic=1 vt.color=0x07
5.Press 'ret' key
6.Wait for boot up and assert needle sshd-server-started
But the system will not boot up as what is shown up on above screenshot
I also opened https://sd.suse.com/servicedesk/customer/portal/1/SD-84770 to help fix the issue.
Updated by waynechen55 almost 3 years ago
- Assignee set to okurz
- Target version set to Ready
Updated by okurz almost 3 years ago
- Subject changed from [openQA][worker][ipmi] Some ipmi workers become offline which affects PublicRC-202204 candidate Build137.1 test run to Machines within .qa.suse.de unavailable (was: Some ipmi workers become offline which affects PublicRC-202204 candidate Build137.1 test run)
Updated by nicksinger almost 3 years ago
- Assignee changed from okurz to nicksinger
Okay, quick update on the general situation:
- Power for the rack was recabled by me and Matthias. We split the 2 PDUs in this rack onto two different fuses which should bring enough headroom to not cause further outages
- Machines on the qsf-cluster where restored again and should run fine. If you miss yours either login over virt-manager or ping me in slack so I can check if your machine is running again
- PXE service on qanet should be restored again. First tests on OSD show that machines (especially ppc workers) are able to run tests again
Updated by okurz almost 3 years ago
@nicksinger what do you think about the starting current within the power distribution of the rack? Can we test that by completely powering off the rack like from the "outside" and reconnecting and seeing if the rack internal power distribution can handle the starting current?
Updated by okurz almost 3 years ago
@jstehlik we discussed in the weekly QE Sync meeting 2022-04-27 about creating another ticket to improve the overall situation. I recommend to use the parent ticket #109743 for any such general improvement discussions.
Updated by nicksinger almost 3 years ago
- Status changed from Blocked to Feedback
okurz wrote:
@nicksinger what do you think about the starting current within the power distribution of the rack? Can we test that by completely powering off the rack like from the "outside" and reconnecting and seeing if the rack internal power distribution can handle the starting current?
we considered this and most likely this was also the culprit in the beginning. We observed yesterday that we had 2 PDUs with 7A each connected to a multi-outlet and a few more servers also connected to this same multi-outlet all connected to a single (I guess, 16A) fuse. We now have split the PDUs onto 2 different fuses resulting in a load of ~7A (measured by the fuse) + ~1A (additional stuff connected to just the "dump" multi-outlet) each. We also split the most important machines (qanet and grenache) with their PSUs onto these two separate fuses to further improve resiliency if one of them fails. Unfortunately this is not possible for qanet15 (the TOR switch) because they only have one single PSU.
After recabling we enabled one fuse again which should have given us the "full load" while booting everything at the same time and it survived. If you'd like to do the same again we would need to be there physically to switch fuses because the "upstream-outlets" cannot be controlled remotely.
Updated by waynechen55 almost 3 years ago
- Assignee changed from nicksinger to okurz
Updated by waynechen55 almost 3 years ago
nicksinger wrote:
Okay, quick update on the general situation:
- Power for the rack was recabled by me and Matthias. We split the 2 PDUs in this rack onto two different fuses which should bring enough headroom to not cause further outages
- Machines on the qsf-cluster where restored again and should run fine. If you miss yours either login over virt-manager or ping me in slack so I can check if your machine is running again
- PXE service on qanet should be restored again. First tests on OSD show that machines (especially ppc workers) are able to run tests again
nicksinger I thin
waynechen55 wrote:
okurz wrote:
please keep the "target version" in the ticket. Blocked by https://sd.suse.com/servicedesk/customer/portal/1/SD-84633
I do not have permission to view this ticket. So what is the situation now ? It looks like all SUT machines can not function as usual:
Please refer to Build137.1 Virtualization Acceptance Group, x86_64 failure and aarch64 failure
The failure involves following steps in boot_from_pxe module:
1.Start host boot from pxe
2.Assert pxe menu needle
3.Press 'esc' key on pxe menu screen
4.Type strings after 'boot:'
/mnt/openqa/repo/SLE-15-SP4-Online-x86_64-Build137.1-Media1/boot/x86_64/loader/linux initrd=/mnt/openqa/repo/SLE-15-SP4-Online-x86_64-Build137.1-Media1/boot/x86_64/loader/initrd install=http://openqa.suse.de/assets/repo/SLE-15-SP4-Online-x86_64-Build137.1-Media1?device=eth0 ifcfg=eth0=dhcp4 plymouth.enable=0 Y2DEBUG=1 vga=791 video=1024x768 console=ttyS1,115200 linuxrc.log=/dev/ttyS1 linuxrc.core=/dev/ttyS1 linuxrc.debug=4,trace reboot_timeout=0 ssh=1 sshpassword=nots3cr3t regurl=http://all-137.1.proxy.scc.suse.de kernel.softlockup_panic=1 vt.color=0x07
5.Press 'ret' key
6.Wait for boot up and assert needle sshd-server-started
But the system will not boot up as what is shown up on above screenshotI also opened https://sd.suse.com/servicedesk/customer/portal/1/SD-84770 to help fix the issue.
nicksinger I think the same issue happens again to SUT machines that are in the charge of openqaworker2:18 and openqaworker2:20.
Please refer to new failure 1 and new failure 2.
waynechen55 wrote:
okurz wrote:
please keep the "target version" in the ticket. Blocked by https://sd.suse.com/servicedesk/customer/portal/1/SD-84633
I do not have permission to view this ticket. So what is the situation now ? It looks like all SUT machines can not function as usual:
Please refer to Build137.1 Virtualization Acceptance Group, x86_64 failure and aarch64 failure
The failure involves following steps in boot_from_pxe module:
1.Start host boot from pxe
2.Assert pxe menu needle
3.Press 'esc' key on pxe menu screen
4.Type strings after 'boot:'
/mnt/openqa/repo/SLE-15-SP4-Online-x86_64-Build137.1-Media1/boot/x86_64/loader/linux initrd=/mnt/openqa/repo/SLE-15-SP4-Online-x86_64-Build137.1-Media1/boot/x86_64/loader/initrd install=http://openqa.suse.de/assets/repo/SLE-15-SP4-Online-x86_64-Build137.1-Media1?device=eth0 ifcfg=eth0=dhcp4 plymouth.enable=0 Y2DEBUG=1 vga=791 video=1024x768 console=ttyS1,115200 linuxrc.log=/dev/ttyS1 linuxrc.core=/dev/ttyS1 linuxrc.debug=4,trace reboot_timeout=0 ssh=1 sshpassword=nots3cr3t regurl=http://all-137.1.proxy.scc.suse.de kernel.softlockup_panic=1 vt.color=0x07
5.Press 'ret' key
6.Wait for boot up and assert needle sshd-server-started
But the system will not boot up as what is shown up on above screenshotI also opened https://sd.suse.com/servicedesk/customer/portal/1/SD-84770 to help fix the issue.
@nicksinger I think the same issue happens again to SUT machines that are in the charge of openqaworker2:18 and openqaworker2:20.
Please refer to new failure 1 and new failure 2.
Also the one associated with openqaworker2:19 I think.
Updated by waynechen55 almost 3 years ago
- Assignee changed from okurz to nicksinger
Updated by nicksinger almost 3 years ago
these jobs are quite old and ran before my changes. But I keep an eye on currently running jobs, e.g.: https://openqa.suse.de/tests/8646252
Updated by waynechen55 almost 3 years ago
nicksinger wrote:
these jobs are quite old and ran before my changes. But I keep an eye on currently running jobs, e.g.: https://openqa.suse.de/tests/8646252
Could you help have a look at this one ? I think this happens more recently. https://openqa.suse.de/tests/8646233#step/boot_from_pxe/1
Updated by nicksinger almost 3 years ago
waynechen55 wrote:
nicksinger wrote:
these jobs are quite old and ran before my changes. But I keep an eye on currently running jobs, e.g.: https://openqa.suse.de/tests/8646252
Could you help have a look at this one ? I think this happens more recently. https://openqa.suse.de/tests/8646233#step/boot_from_pxe/1
I fear we accidentally unplugged the cable of fozzie. I see that instances 17,18 and 20 have the same worker class. Do you think we could temporarily disable instance 19 (fozzie) until we can physically plug the cable back in? Or are there tests which require all 4 machines to work at the same time?
Updated by waynechen55 almost 3 years ago
nicksinger wrote:
waynechen55 wrote:
nicksinger wrote:
these jobs are quite old and ran before my changes. But I keep an eye on currently running jobs, e.g.: https://openqa.suse.de/tests/8646252
Could you help have a look at this one ? I think this happens more recently. https://openqa.suse.de/tests/8646233#step/boot_from_pxe/1
I fear we accidentally unplugged the cable of fozzie. I see that instances 17,18 and 20 have the same worker class. Do you think we could temporarily disable instance 19 (fozzie) until we can physically plug the cable back in? Or are there tests which require all 4 machines to work at the same time?
Yes. Please help disable the worker openqaworker2:19. No job can run with it. But if you think the cable can be plugged back very soon, then do not disable the worker.
Updated by nicksinger almost 3 years ago
waynechen55 wrote:
Yes. Please help disable the worker openqaworker2:19. No job can run with it. But if you think the cable can be plugged back very soon, then do not disable the worker.
Max helped us to replug the cable. Machine is now capable of booting from PXE again so no need to disable the workers.
Updated by nicksinger almost 3 years ago
- Status changed from Feedback to Resolved
openqaworker2:19 seems to complete jobs successful again. As there where no further comments I consider the immediate tasks regarding the outage as done and would resolve this ticket now.
Updated by waynechen55 almost 3 years ago
nicksinger wrote:
openqaworker2:19 seems to complete jobs successful again. As there where no further comments I consider the immediate tasks regarding the outage as done and would resolve this ticket now.
Thanks for your help.
Updated by openqa_review over 2 years ago
This is an autogenerated message for openQA integration by the openqa_review script:
This bug is still referenced in a failing openQA test: mediacheck@svirt-xen-hvm
https://openqa.suse.de/tests/8738730#step/bootloader_start/1
To prevent further reminder comments one of the following options should be followed:
- The test scenario is fixed by applying the bug fix to the tested product or the test is adjusted
- The openQA job group is moved to "Released" or "EOL" (End-of-Life)
- The bugref in the openQA scenario is removed or replaced, e.g.
label:wontfix:boo1234
Expect the next reminder at the earliest in 28 days if nothing changes in this ticket.