action #164427
closedHTTP response alert every Monday 01:00 CET/CEST due to fstrim size:M
0%
Description
Observation¶
See #163592-53. https://suse.slack.com/archives/C02CANHLANP/p1721841092771439
As there is really just 1 (!) job running right now on OSD and 8 scheduled I will use the opportunity to conduct another important load experiment for https://progress.opensuse.org/issues/163592 . Expect spotty responsiveness of OSD for the next hours
date -Is && time sudo nice -n 19 ionice -c 3 /usr/sbin/fstrim --listed-in /etc/fstab:/proc/self/mountinfo --verbose --quiet-unsupported
From the output of that command and lsof -p $(pidof fstrim) it looks like only one mount point after another is trimmed. /home and /space-slow finished within seconds. /results takes long. But maybe that was me running "ab" for benchmarking. In "ab" I saw just normal response times. Pretty much as soon as I aborted that fstrim continued and finished stating /assets and only some seconds later the other file-systems:
$ date -Is && time sudo nice -n 19 ionice -c 3 /usr/sbin/fstrim --listed-in /etc/fstab:/proc/self/mountinfo --verbose --quiet-unsupported
2024-07-24T19:13:17+02:00
/home: 3.4 GiB (3630792704 bytes) trimmed on /srv/homes.img
/space-slow: 1.6 TiB (1796142841856 bytes) trimmed on /dev/vde
/results: 1.1 TiB (1231325605888 bytes) trimmed on /dev/vdd
/assets: 2.6 TiB (2893093855232 bytes) trimmed on /dev/vdc
/srv: 117.4 GiB (126101643264 bytes) trimmed on /dev/vdb
/: 7.4 GiB (7976497152 bytes) trimmed on /dev/vda1
real 37m36.323s
user 0m0.009s
sys 2m55.929s
so overall that took 37m. Let's see how long the same takes w/o me running "ab". That run finished again within 24m but interesting enough no significant effect on service availability. Let's see if without nice/ionice we can actually trigger unresponsiveness. Nope, I can't. So maybe after repeated runs the effect is not reproducible anymore for now. Over the past 30 days on https://monitor.qa.suse.de/d/WebuiDb/webui-summary?orgId=1&from=now-30d&to=now&viewPanel=78&refresh=1m it's visible that we have that outage reproduced each Monday morning. With that I consider we can simply override the fstrim service and see the effect in production. I called systemctl edit fstrim and added
[Service]
IOSchedulingClass=idle
CPUSchedulingPolicy=idle
Suggestions¶
- Monitor the effect of nice&ionice on fstrim
- can dumpe2fs provide more information what fstrim would remove?
Rollback actions¶
- in
/etc/openqa/openqa.inion OSD bump the reduced job limit again from 330 to 420 (or maybe do some middle ground between those limits?) (why would 420 not be supported anymore?) - Remove notification policy override in https://monitor.qa.suse.de/alerting/routes
Files
Updated by okurz 5 months ago
- Copied from action #163592: [alert] (HTTP Response alert Salt tm0h5mf4k) size:M added
Updated by okurz 5 months ago
No alert was triggered today but https://monitor.qa.suse.de/d/WebuiDb/webui-summary?orgId=1&from=1722201845123&to=1722218698179 shows a pending for HTTP response and there was a window of unresponsiveness. From the fstrim service
okurz@openqa:~> sudo journalctl --since=yesterday -u fstrim
Jul 29 00:48:40 openqa systemd[1]: Starting Discard unused blocks on filesystems from /etc/fstab...
Jul 29 01:14:31 openqa fstrim[19887]: /home: 487.9 MiB (511549440 bytes) trimmed on /srv/homes.img
Jul 29 01:14:31 openqa fstrim[19887]: /space-slow: 1.7 TiB (1814773288960 bytes) trimmed on /dev/vde
Jul 29 01:14:31 openqa fstrim[19887]: /results: 1.4 TiB (1529420541952 bytes) trimmed on /dev/vdd
Jul 29 01:14:31 openqa fstrim[19887]: /assets: 3.1 TiB (3451388735488 bytes) trimmed on /dev/vdc
Jul 29 01:14:31 openqa fstrim[19887]: /srv: 117.8 GiB (126535155712 bytes) trimmed on /dev/vdb
Jul 29 01:14:31 openqa fstrim[19887]: /: 5.9 GiB (6364971008 bytes) trimmed on /dev/vda1
Jul 29 01:14:31 openqa systemd[1]: fstrim.service: Deactivated successfully.
Jul 29 01:14:31 openqa systemd[1]: Finished Discard unused blocks on filesystems from /etc/fstab.
The whole execution took 26m so roughly the same time as w/o "idle" classes. I assume that the overall test load on the system was load and hence we had no alert, not that the idle class helped much. But maybe the "idle" classes don't help as much as explicit nice -n 19 ionice -c 3. Trying more aggressive
[Service]
IOSchedulingClass=idle
CPUSchedulingPolicy=idle
Nice=19
IOSchedulingPriority=7
Updated by okurz 5 months ago · Edited
- File Screenshot_20240805_095039_fstrim_and_pg_dump_running_while_no_http_response.png Screenshot_20240805_095039_fstrim_and_pg_dump_running_while_no_http_response.png added
- Status changed from Feedback to In Progress
Today in the morning there was another unresponsiveness period as visible in 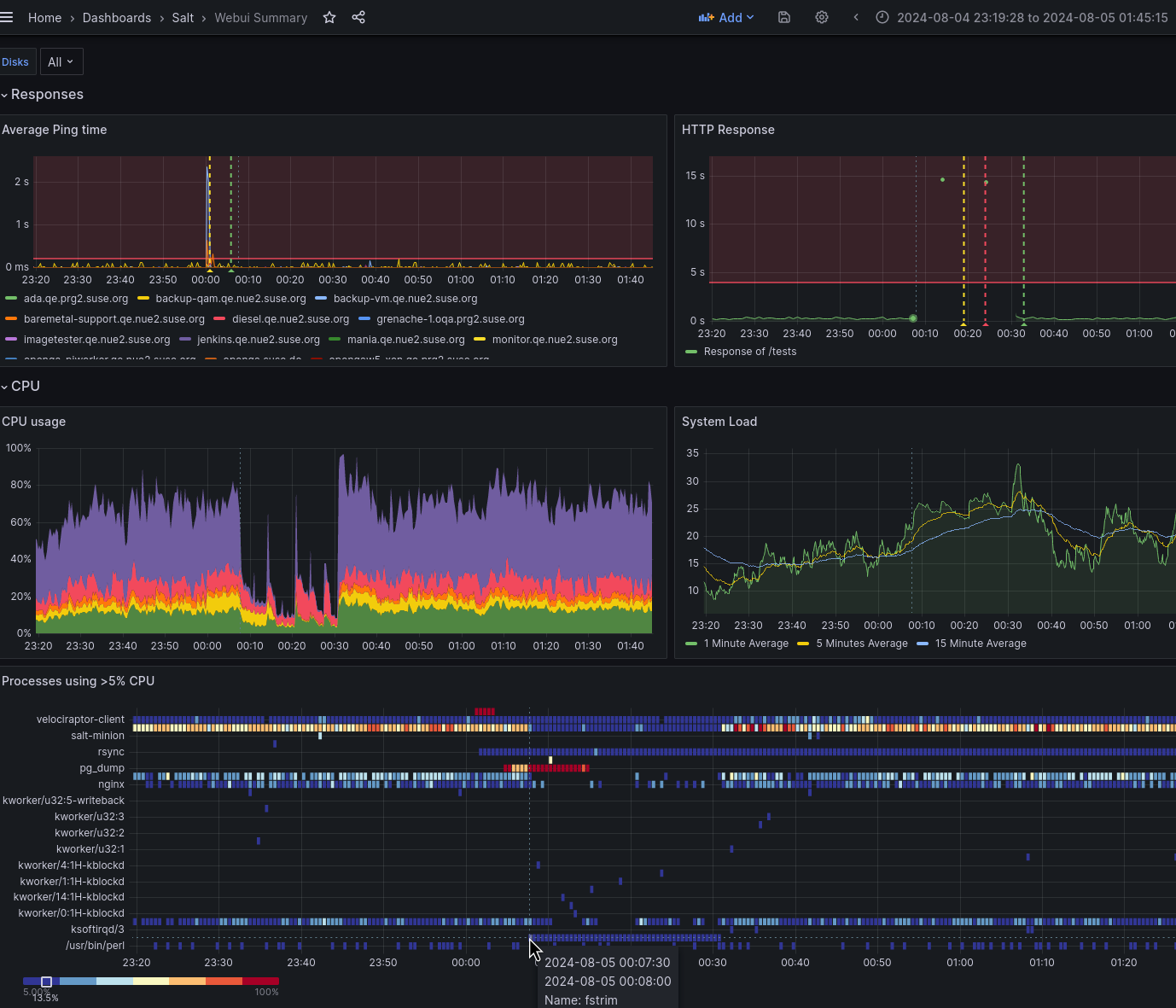 .
.
So apparently the tweaking to the scheduling classes and nice have no effect here which leaves the question why I could not reproduce problems while running fstrim manually. I suspect the problem is that pg_dump and fstrim run in parallel. I will try to shift the backup time window in https://gitlab.suse.de/qa-sle/backup-server-salt/-/blob/master/rsnapshot/init.sls
Updated by okurz 4 months ago
I received a good response in https://suse.slack.com/archives/C02CLLS7R4P/p1721719368768919 backing the statement that fstrim on virtual storage is questionable. The suggestion was to just disable it. My response:
Thank you. I will consider this. Just yesterday I understood that at the time when fstrim is running also a heavy database backup is running using pg_dump. This in combination might explain the heavy impact on the machine so my next try is if it helps to avoid that collision. If that does not help then I will most likely just disable fstrim as you mentioned.
Updated by okurz 4 months ago
- File Screenshot_20240813_084305_openqa_unresponsiveness_during_fstrim_no_pg_dump.png Screenshot_20240813_084305_openqa_unresponsiveness_during_fstrim_no_pg_dump.png added
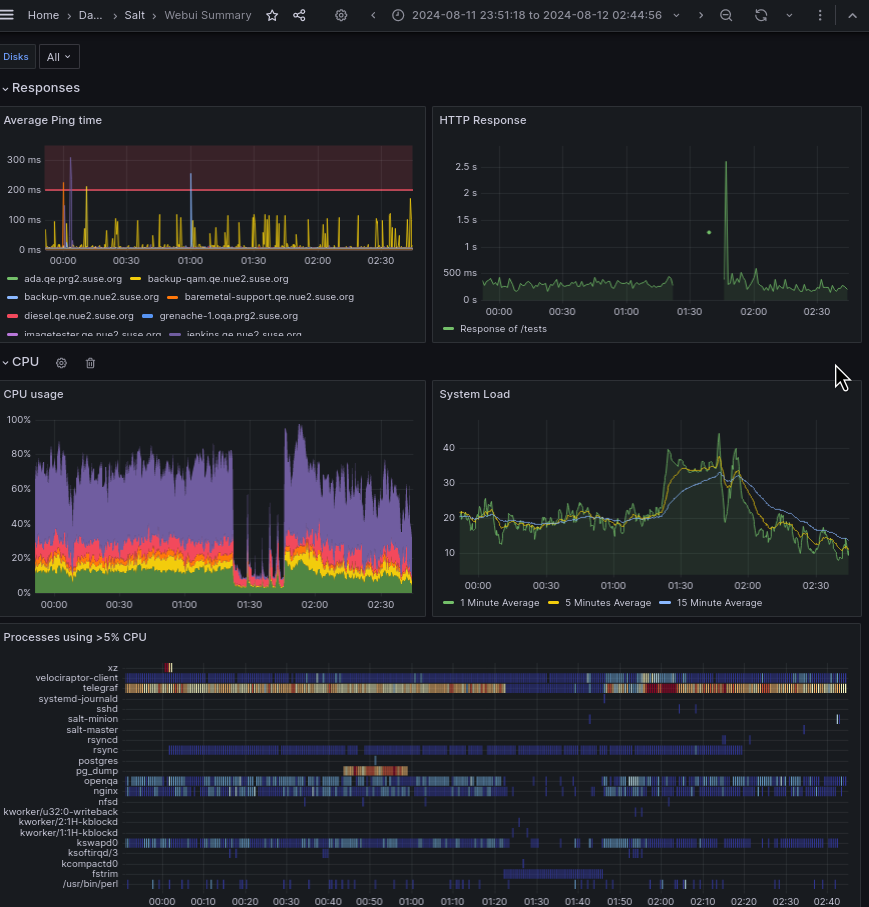
shows that we still suffer from unresponsivess despite fstrim running unaffected by pg_dump so I will disable the fstrim service completely.
https://gitlab.suse.de/openqa/salt-states-openqa/-/merge_requests/1248
Updated by okurz 4 months ago
- Related to action #165195: [alert] Failed systemd services alert added
Updated by okurz 4 months ago
- Due date deleted (
2024-09-20) - Status changed from Feedback to Resolved
No unresponsive today on Monday as visible on https://monitor.qa.suse.de/d/WebuiDb/webui-summary?orgId=1&from=1723988580749&to=1724057145466&viewPanel=78 so I assume masked fstrim is effective.