action #126821
closed[openQA][infra][worker] ppc64 fails to load grub2 completely over tftp/pxe on qanet and PXE load timeout issues size:M
0%
Description
Observation¶
spvm worker cannot display grub menu properly like as below:
https://openqa.suse.de/tests/10807175#step/bootloader/18
I noticed grenache-1:3 and grenache-1:7 can bootup normally, but grenache-1:1, grenache-1:2, grenache-1:4, grenache-1:5, grenache-1:6 cannot work.
Steps to reproduce¶
- Clone https://openqa.suse.de/tests/latest?arch=ppc64le&distri=sle&flavor=Online&machine=ppc64le-hmc&test=default&version=15-SP5
- Can be simplified to
openqa-clone-job --within-instance https://openqa.suse.de/tests/10924663 _GROUP=0 BUILD= TEST+=poo126821 SCHEDULE=tests/installation/bootloader
Expected result¶
- https://openqa.suse.de/tests/latest?arch=ppc64le&distri=sle&flavor=Online&machine=ppc64le-hmc&test=default&version=15-SP5 is consistently stable again
Suggestions¶
- DONE Remove affected machines from salt
- Manually boot machines and crosscheck on TFTP server
- Check if the problem can be reproduced or not reproduce on both qanet and qa-jump.qe.suse2.nue.org
Rollback steps¶
- Add machines back to production in salt and verify in production
Files
| grub.png (32.8 KB) grub.png | No grub configuration was provided to grub, grub finished, nothing was booted. |
{kind=link}
Updated by lansuse about 2 years ago
I collected some logs from grenache-1:3, it looks like a ssh issue
[2023-03-30T09:41:31.421356+02:00] [debug] [pid:754318] Wait for SSH on host grenache-4.qa.suse.de (timeout: 120)
[2023-03-30T09:43:31.511924+02:00] [debug] [pid:754318] grenache-4.qa.suse.de does not seems to have an active SSH server. Continuing anyway.
xterm PID is 757340
[2023-03-30T09:43:31.519706+02:00] [debug] [pid:754318] <<< backend::baseclass::start_ssh_serial(hostname="grenache-4.qa.suse.de", username="root", password="SECRET")
[2023-03-30T09:43:31.520774+02:00] [debug] [pid:754318] <<< backend::baseclass::new_ssh_connection(password="SECRET", hostname="grenache-4.qa.suse.de", username="root")
[2023-03-30T09:45:40.840506+02:00] [debug] [pid:754318] Could not connect to root@grenache-4.qa.suse.de, Retrying after some seconds...
Updated by JERiveraMoya about 2 years ago
This backend has been perfectly working until this was fixed: https://progress.opensuse.org/issues/124685#note-26
I got answer on that ticket that there is not correlation, but anyway from the same date is happening, in latest build is even less stable, restarting 3 times automatically is not enough to make pass a job.
Updated by JERiveraMoya about 2 years ago
I could check that this was happening (not an exact list):
NOVALINK_LPAR_ID 4,5,6,10 were working fine.
NOVALINK_LPAR_ID 7,8,9 fail consistently.
This is our salt configuration: https://gitlab.suse.de/openqa/salt-pillars-openqa/-/blob/master/openqa/workerconf.sls
Adding more information from:
https://sd.suse.com/servicedesk/customer/portal/1/SD-118372
from Michal Suchanek:
The redcurrant machine is a very strange configuration. There is Novalink installed but the management is taken by powerhmc1 (which means that hmc1 can manage the machine but hmc2 or the management partition cannot). The Novalink management partition is not even booted.
From the HMC LPARS redcurrant-1 to redcurrant-12 appear configured and running.
lssyscfg -m redcurrant -r lpar -F lpar_id,name,state
1,vios,Running
2,novalink,Open Firmware
3,redcurrant-1,Running
4,redcurrant-2,Running
5,redcurrant-3,Running
6,redcurrant-4,Running
7,redcurrant-10,Running
8,redcurrant-5,Running
9,redcurrant-12,Running
10,redcurrant-11,Running
11,redcurrant-6,Running
12,redcurrant-8,Running
13,redcurrant-9,Running
14,redcurrant-7,Running
15,Multipath-test,Not Activated
16,VIOS2,Not Activated
No grub configuration was provided to grub, grub finished, nothing was booted.
Updated by JERiveraMoya about 2 years ago
MR to disabling failing instance for NOVALINK:
https://gitlab.suse.de/openqa/salt-pillars-openqa/-/merge_requests/520
Updated by nicksinger about 2 years ago
- Subject changed from [openQA][infra][worker]spvm backend worker boot failed to [openQA][infra][worker] ppc64 fails to load grub2 completely over tftp/pxe on qanet
I think we see similar issues on non-novalink machines: https://openqa.suse.de/tests/10924663#step/bootloader/19
Updated by okurz about 2 years ago
- Subject changed from [openQA][infra][worker] ppc64 fails to load grub2 completely over tftp/pxe on qanet to [openQA][infra][worker] ppc64 fails to load grub2 completely over tftp/pxe on qanet and PXE load timeout issues size:M
- Description updated (diff)
- Status changed from New to Workable
Updated by okurz about 2 years ago
- Related to action #125219: Use qa-power8 for ppc tests in o3 - try the other suggestions added
Updated by nicksinger about 2 years ago
- Status changed from Workable to In Progress
- Assignee set to nicksinger
Updated by okurz about 2 years ago
- Related to action #128045: /var on qanet is 100% added
Updated by nicksinger about 2 years ago
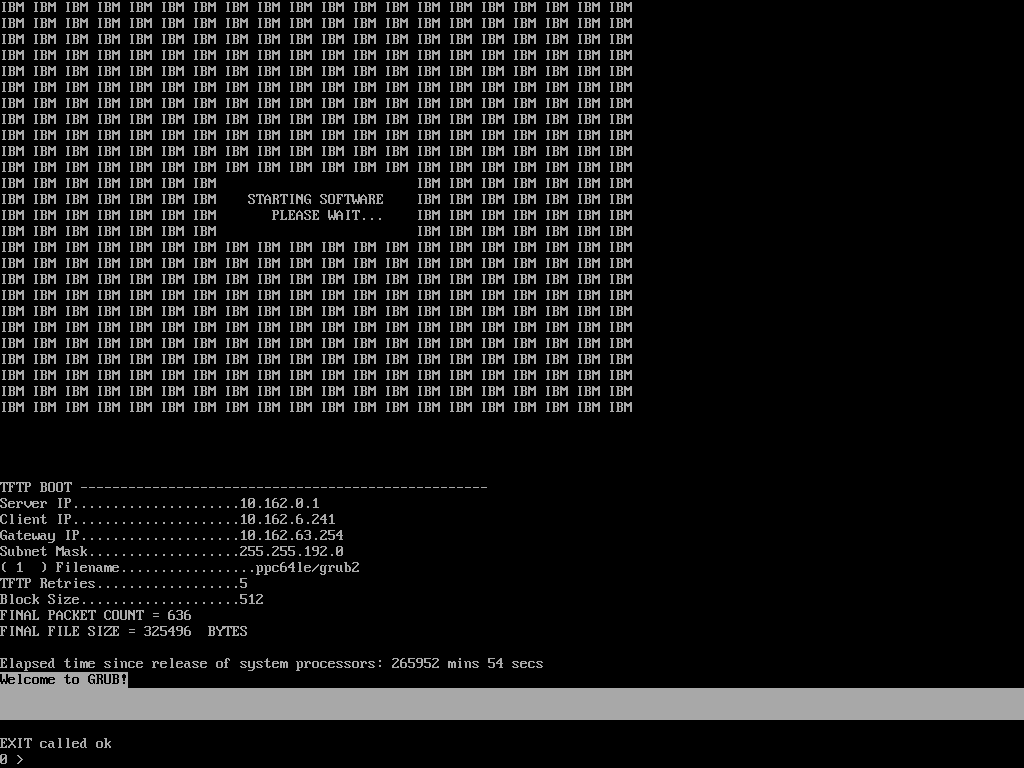
I took grenache-5 to experiment. I realized that the IP config in the PowerPC Firmware war missing and reconfigured it with the following values:
Server IP.....................10.162.0.1
Client IP.....................10.162.6.241
Gateway IP....................10.162.63.254
Subnet Mask...................255.255.192.0
Afterwards I could still observe the same issue and checked with tcpdump that all files are served correctly from qanet which is the case. However, I found https://www.ibm.com/support/pages/could-not-allocate-memory-rtas-grub-or-yaboot-ppcbe and tried the described steps in "Resolving The Problem" to reset the nvram content which indeed worked. I'm now able to boot into our grub PXE menu again. However I have no clue what caused this - the article mentions "Memory fragmentation" but I didn't see the described error messages, just the symptoms where the same.
Updated by nicksinger about 2 years ago
I did the same now for grenache-6 and 7 (not sure why 7 was disabled in https://gitlab.suse.de/openqa/salt-pillars-openqa/-/merge_requests/520 as it was reported as "working")
Updated by openqa_review about 2 years ago
- Due date set to 2023-05-05
Setting due date based on mean cycle time of SUSE QE Tools
Updated by acarvajal about 2 years ago
I think we're seeing the same with the nessberry LPARs: https://openqa.suse.de/tests/10957776.
It does seem to work sporadically; from the latest 10 runs https://openqa.suse.de/tests/10957776#next_previous over the past 2 weeks, it has worked 3 times.
BTW, is tftpd active in qanet? I see it configured in qanet:/etc/sysconfig/tftp, but there's no service running (that I could see) and it's also not configured as part of xinetd.
Updated by nicksinger about 2 years ago
acarvajal wrote:
I think we're seeing the same with the nessberry LPARs: https://openqa.suse.de/tests/10957776.
It does seem to work sporadically; from the latest 10 runs https://openqa.suse.de/tests/10957776#next_previous over the past 2 weeks, it has worked 3 times.
Not sure if it is actually the same. The symptoms look a little bit different. But you could also try a nvram reset described in https://www.ibm.com/support/pages/could-not-allocate-memory-rtas-grub-or-yaboot-ppcbe - afterwards make sure to configure TFTP/BOOTP in the SMS menu again properly. I also saw some settings regarding block-size in there - you could try to set it from 512 to 1024, it might help loading the required files in a more stable manner.
I have yet to find out why this happens. Maybe this is a firmware issue from PPC machines or maybe it is caused by many re-installs from our side.
Updated by nicksinger about 2 years ago
nicksinger wrote:
acarvajal wrote:
I think we're seeing the same with the nessberry LPARs: https://openqa.suse.de/tests/10957776.
It does seem to work sporadically; from the latest 10 runs https://openqa.suse.de/tests/10957776#next_previous over the past 2 weeks, it has worked 3 times.
Not sure if it is actually the same. The symptoms look a little bit different. But you could also try a nvram reset described in https://www.ibm.com/support/pages/could-not-allocate-memory-rtas-grub-or-yaboot-ppcbe - afterwards make sure to configure TFTP/BOOTP in the SMS menu again properly. I also saw some settings regarding block-size in there - you could try to set it from 512 to 1024, it might help loading the required files in a more stable manner.
I have yet to find out why this happens. Maybe this is a firmware issue from PPC machines or maybe it is caused by many re-installs from our side.
never mind these steps. I realized that tftpd was down on qanet. I restarted this service and the job and it looks better now: https://openqa.suse.de/tests/10958779 - could you confirm @acarvajal ?
Updated by acarvajal about 2 years ago
nicksinger wrote:
never mind these steps. I realized that tftpd was down on qanet. I restarted this service and the job and it looks better now: https://openqa.suse.de/tests/10958779 - could you confirm @acarvajal ?
Just restarted the test. I'll check later how it goes. Thanks for the help.
Updated by nicksinger about 2 years ago
- Status changed from In Progress to Feedback
So I focused on 4, 5 and 6 now as these where the only ones I was able to spot reproducible problems. All three instances can boot again as expected:
- https://openqa.suse.de/tests/10968507
- https://openqa.suse.de/tests/10968508
- https://openqa.suse.de/tests/10968509
Created https://gitlab.suse.de/openqa/salt-pillars-openqa/-/merge_requests/526 to revert the previous disable. I think after it is merged and executing a "proper" job, we can close this here. @JERiveraMoya what do you think?
Updated by nicksinger about 2 years ago
- Status changed from Feedback to Resolved
Workers look fine also after the long weekend. I'm considering this done for now.
Updated by openqa_review almost 2 years ago
- Status changed from Resolved to Feedback
This is an autogenerated message for openQA integration by the openqa_review script:
This bug is still referenced in a failing openQA test: default@ppc64le-hmc
https://openqa.suse.de/tests/11162714#step/bootloader/1
To prevent further reminder comments one of the following options should be followed:
- The test scenario is fixed by applying the bug fix to the tested product or the test is adjusted
- The openQA job group is moved to "Released" or "EOL" (End-of-Life)
- The bugref in the openQA scenario is removed or replaced, e.g.
label:wontfix:boo1234
Expect the next reminder at the earliest in 28 days if nothing changes in this ticket.
Updated by nicksinger almost 2 years ago
- Status changed from Feedback to Resolved
different issue in the meantime. Removed bugref and restarted job.
Updated by okurz almost 2 years ago
- Copied to action #129670: [qe-core] Reset ppc nvram before trying to boot Linux kernel to prevent PXE related file reading timeouts added