action #154753
closedcoordination #151816: [epic] Handle openQA fixes and job group setup
[sporadic] Make stable validate_lvm_raid1 reboot
0%
Description
Motivation¶
validate_lvm_raid1 test for x86_64 fails sporadically during reboot, as it is expected to see textmode linux login but the loading screen is taking too long.
Scope¶
The failure rate is about 8/10 test runs with increased bootloader timeout (see : https://github.com/sofiasyria/os-autoinst-distri-opensuse/blob/589791e625851f5227063559107c9c45e004a34b/tests/console/validate_lvm_raid1.pm#L30 )
and 2/10 with increased QEMURAM=2048
Acceptance criteria¶
AC1: The test should not fail at all.
Additional information¶
Last good: 50.1 (or more recent)
Always latest result in this scenario: latest
Files
Updated by JERiveraMoya over 1 year ago
- Tags set to qe-yam-feb-sprint
- Subject changed from [sporadic] test fails in validate_lvm_raid1 reboot to [sporadic] Make stable validate_lvm_raid1 reboot
- Description updated (diff)
- Status changed from New to Workable
- Parent task set to #151816
Updated by hjluo over 1 year ago
- Status changed from Workable to In Progress
- Assignee set to hjluo
Updated by hjluo over 1 year ago · Edited
opensusebasetest::wait_boot -> lib/opensusebasetest.pm:922 called opensusebasetest::wait_boot_past_bootloader -> lib/opensusebasetest.pm:778 called opensusebasetest::wait_boot_textmode -> lib/opensusebasetest.pm:714 called testapi::assert_screen
[2024-02-01T11:14:30.298319+01:00] [debug] [pid:75171] <<< testapi::assert_screen(mustmatch=[
"linux-login",
"emergency-shell",
"emergency-mode"
], timeout=500)
- PR:
- From VR, this might be not a time issue. even in dev mode, the screen hang there. need to check the console output for more details.
- this case hang at the SUSE screen for 2+ hours
- now the VR run with QEMURAM=4096 and patch:
--- a/tests/console/validate_lvm_raid1.pm
+++ b/tests/console/validate_lvm_raid1.pm
@@ -27,7 +27,7 @@ sub run {
_check_raid1_partitioning($config, $expected_num_devs);
_remove_raid_disk($config, $expected_num_devs);
_reboot();
- $self->wait_boot;
+ $self->wait_boot(textmode => 1, ready_time => 600, bootloader_time => 300);
_check_raid_disks_after_reboot($config, $expected_num_devs);
}
@@ -69,7 +69,7 @@ sub _remove_raid_disk {
sub _reboot {
record_info('system reboots');
- power_action('reboot', textmode => 'textmode');
+ power_action('reboot', textmode => 1);
}
From the VR above, I think this may maybe a bug while not a timing issue from our test side, we can wait for the new build to verify it.
Updated by hjluo over 1 year ago
- Status changed from In Progress to Workable
- Assignee deleted (
hjluo)
Updated by lmanfredi over 1 year ago
- Status changed from Workable to In Progress
- Assignee set to lmanfredi
Updated by lmanfredi over 1 year ago
Also with last build 53.1 and 4GB RAM the failure rate is 2/10. See VRs
Updated by rainerkoenig over 1 year ago
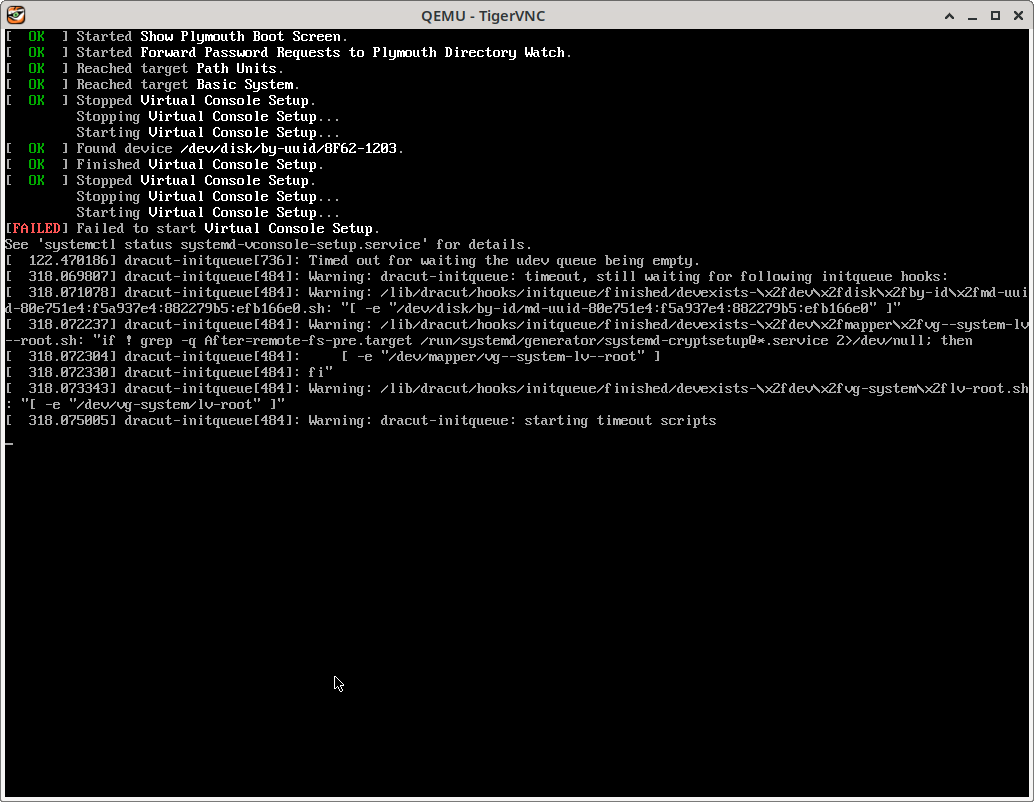
I attach a screenshot that I was taking from a debugging session of this problem on aarch64 in the current build. I obtained it by pressing ESC in the VNV viewer when we're seeing the Geeko screen after the bootloader. Problem seems to be that failure in dracut and then system locks up and will never boot.
Updated by JERiveraMoya over 1 year ago
you can focus in x86_64, aarch64 is pretty slow in openQA to debug.
Updated by JERiveraMoya over 1 year ago
- Tags changed from qe-yam-feb-sprint to qe-yam-mar-sprint
Updated by JERiveraMoya about 1 year ago
if you already detected a bug, this is not the place to report it :) but bugzilla, I assume you are blocked here not able to make it stable.
Updated by lmanfredi about 1 year ago
By increasing:
- bootloader_time => 400
- ready_time => 600
in $self->wait_boot(bootloader_time => 400, ready_time => 600); there is ~ 50% passed.
See VRs
Updated by JERiveraMoya about 1 year ago
Slack thread with more info from previous errors:
https://suse.slack.com/archives/C02CLB2LB7Z/p1710139073566099
Updated by lmanfredi about 1 year ago
More info also here:
- bsc#1150370 raid1 does not recover faulty disk after reboot
- bsc#1172203 Inconsistent behavior of raid1 disk resync after reboot
Fresh system installation of SLES Text mode, with 4 hard disks.
/dev/md0consists of 4 devices.
After first boot, one of the disk is set to faulty and removed:
mdadm --detail /dev/md0 # this will return "Active devices : 4" every time
mdadm --manage /dev/md0 --set-faulty /dev/vdd2
mdadm --manage /dev/md0 --remove /dev/vdd2
reboot
mdadm --detail /dev/md0 # this will return sometimes "Active devices: 3" and sometimes "Active Devices: 4".
See comment:
The above assumption is not correct, md raid kernel and user space code don't provide such assurance.
The behavior varies depending on the timing, that is for different internal state the md raid is in when fail the component disk and reboot the system, the observed result varies.
Updated by lmanfredi about 1 year ago
By removing the call to sub _remove_raid_disk, now the VRs works fine.
Removed WIP for PR#18827. Ready to merge.
Updated by JERiveraMoya about 1 year ago
- Status changed from In Progress to Resolved