Why download.opensuse.org does not officially support SSL
The main issue here is the way how MirrorBrain is used: instead of delivering a file directly, download.opensuse.org will redirect the requests of our customers to a mirror server which hosts the file and is nearer to their location. While this has normally benefits for both sides, it becomes problematic if MirrorBrain should redirect users who like to get their files delivered via an encrypted (https) channels.
At first: our mirrors need to support SSL for this. While some mirrors have SSL enabled since a long time, others don't - and want to avoid this also in the future to avoid an overload of their systems.
Second: MirrorBrain does not only need to know if a mirror server supports SSL before it can redirect a user requesting a file via SSL to this mirror - to avoid confusing error messages, we also need to make sure that the SSL setup on the mirrors is correct, and at least (just to give an example) provide a correct SSL certificate.
Third: MirrorBrain itself was never developed to differentiate between encrypted and not encrypted requests. As such, this "new" feature needs to be implemented properly. Volunteers needed...
Do you know that download.opensuse.org is use by nearly all openSUSE systems to get their updates and for downloading new software? The Apache (worker) process running on this machine serves (under normal conditions) 300 up to 500 requests per second for only this reason.
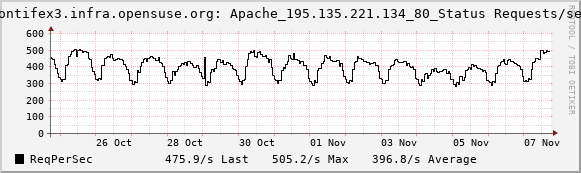
In addition to that, a dedicated Nginx service on the same host is used to quickly free up resources from the Apache and deliver files (like RPMs and ISOs) as fast as possible, without blocking Apache from handling more requests. This setup avoids database locks, as each request for a file on the Apache side results in a database request to MirrorBrain, to get the best mirror for the file. As Apache can not free up the DB connection, until the request is handled, the "hand over" (aka redirect) to the Nginx service allows to get the Apache freed up quickly, ready to handle more requests.
But the Nginx on the machine is just used as "last ressort": under normal circumstances, openSUSE benefits from over 180 mirrors world wide who offer files for our users. And the redirection is based on the GeoIP location of the requester and the closest mirrors to that destination. If you ever want to know how many mirrors host a specific file, just click on the "details" link on download.opensuse.org (have a look at the details for the Leap 15.1 ISO as example). We provide even a Google Map for you (see: "Map showing the closest mirrors") to show you the location of your client and the mirror servers around you.
While people are more and more asking to get an encrypted line to download their packages, we - as openSUSE admins - are asking ourselves often enough: "why"?
- During the installation of a client machine, it get's the public signing keys for official packages installed (one of the reasons why you really should "Verify Your Download Before Use")
- Each and every package in the official repositories is signed with such a key. As addition, each RPM also includes checksums for every file it contains.
So what happens if a mirror provides you with some malicious packages?
- first of all: our MirrorBrain scanner might detect a size mismatch and exclude the file from any redirect
- during installation, you will get warned that either the signing key does not match and/or the (internal) checksums of the package are wrong
- if you add a new repository from the Open Build Service, you should also verify the provided key
Does that change, if you download the same file via SSL? - No.
Does an encrypted download help you to mask what you are doing? - Only partly. An attacker or undercover agent might not exactly know what you download - but keep in mind that your DNS queries are known as well as the IP addresses of the machines you connect to, this mitigates the fog you want to produce.
Would TOR help ? - Probably yes, in regard of the anonymity that TOR provides, only you and your entry server know what you are looking for. Interestingly, the traffic inside the TOR network is already encrypted. So you don't win much with an encrypted endpoint download.opensuse.org.
So while we are looking for developers who like to extend MirrorBrain with the needed features for a proper SSL redirection - and on our mirror servers to prepare their infrastructure for SSL traffic - stay tuned and keep in mind that the verification of keys and installation medias will not change, even if we can officially provide you with completely SSL encrypted traffic in the near future.